
1.3 Kubernetes 集群版
1.3.1 安装
$ helm repo add incubator https://kubernetes-charts-incubator.storage.googleapis.com $ helm install incubator/druid --version 0.2.6 --generate-name
NAME: druid-1592218780 LAST DEPLOYED: Mon Jun 15 23:59:42 2020 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: 1. Get the router URL by running these commands: export POD_NAME=$(kubectl get pods --namespace default -l "app=druid,release=druid-1592218780" -o jsonpath="{.items[0].metadata.name}") echo "Visit http://127.0.0.1:8080 to use your application" kubectl port-forward $POD_NAME 8080:8888
$ export POD_NAME=$(kubectl get pods --namespace default -l "app=druid,release=`helm list | grep druid- | awk '{print $1}'`" | grep router | awk '{print $1}') $ nohup kubectl port-forward $POD_NAME 8888:8888 --address 0.0.0.0 2>&1 &
1.3.2 校验
$ kubectl get all
上述 CLUSTER-IP 信息已脱敏
1.3.3 ZooKeeper 元数据
$ zkCli.sh [zk: localhost:2181(CONNECTED) 0] ls -R /druid
/druid /druid/announcements /druid/coordinator /druid/discovery /druid/indexer /druid/internal-discovery /druid/loadQueue /druid/overlord /druid/segments /druid/servedSegments /druid/announcements/10.10.10.63:8083 /druid/coordinator/_COORDINATOR /druid/coordinator/_COORDINATOR/_c_281fb87b-c40c-4d71-a657-8254cbcf3730-latch-0000000000 /druid/discovery/druid:broker /druid/discovery/druid:coordinator /druid/discovery/druid:overlord /druid/discovery/druid:router /druid/discovery/druid:broker/0e76bfc1-87f8-4799-9c36-0fb0e5617aef /druid/discovery/druid:coordinator/035b1ada-531e-4a71-865b-7a1a6d6f1734 /druid/discovery/druid:overlord/a74523d6-1708-45b3-9c0b-87f438cda4e3 /druid/discovery/druid:router/c0bb18d3-51b1-4089-932b-a5d6e05ab91c /druid/indexer/announcements /druid/indexer/status /druid/indexer/tasks /druid/indexer/announcements/10.10.10.65:8091 /druid/indexer/status/10.10.10.65:8091 /druid/indexer/tasks/10.10.10.65:8091 /druid/internal-discovery/BROKER /druid/internal-discovery/COORDINATOR /druid/internal-discovery/HISTORICAL /druid/internal-discovery/INDEXER /druid/internal-discovery/MIDDLE_MANAGER /druid/internal-discovery/OVERLORD /druid/internal-discovery/PEON /druid/internal-discovery/ROUTER /druid/internal-discovery/BROKER/10.10.10.73:8082 /druid/internal-discovery/COORDINATOR/10.10.10.72:8081 /druid/internal-discovery/HISTORICAL/10.10.10.63:8083 /druid/internal-discovery/MIDDLE_MANAGER/10.10.10.65:8091 /druid/internal-discovery/OVERLORD/10.10.10.72:8081 /druid/internal-discovery/ROUTER/10.10.10.55:8888 /druid/loadQueue/10.10.10.63:8083 /druid/overlord/_OVERLORD /druid/overlord/_OVERLORD/_c_ecacbc56-4d36-4ca0-ac1d-0df919c40bff-latch-0000000000 /druid/segments/10.10.10.63:8083 /druid/segments/10.10.10.63:8083/10.10.10.63:8083_historical__default_tier_2020-06-20T04:08:23.309Z_1b957acb6850491ca6ea885fca1b3c210 /druid/segments/10.10.10.63:8083/10.10.10.63:8083_historical__default_tier_2020-06-20T04:10:16.643Z_57c1f60104a94c459bf0331eb3c1f0a01 /druid/servedSegments/10.10.10.63:8083
上述 IP 地址相关信息已脱敏
1.3.4 Broker 健康检查
$ kill `ps -ef | grep 8082 | grep -v grep | awk '{print $2}'`; export POD_NAME=$(kubectl get pods --namespace default -l "app=druid,release=`helm list | grep druid- | awk '{print $1}'`" | grep broker | awk '{print $1}') ; nohup kubectl port-forward $POD_NAME 8082:8082 --address 0.0.0.0 2>&1 & $ curl localhost:8082/status/health
true
1.3.5 Historical 缓存
$ cd /opt/druid/var/druid/segment-cache/info_dir $ cat wikipedia_2016-06-27T00:00:00.000Z_2016-06-27T01:00:00.000Z_2020-06-20T04:10:01.833Z
{ "dataSource": "wikipedia", "interval": "2016-06-27T00:00:00.000Z/2016-06-27T01:00:00.000Z", "version": "2020-06-20T04:10:01.833Z", "loadSpec": { "type": "hdfs", "path": "hdfs://10.10.10.44:8020/druid/segments/wikipedia/20160627T000000.000Z_20160627T010000.000Z/2020-06-20T04_10_01.833Z/0_index.zip" }, "dimensions": "channel,cityName,comment,countryIsoCode,countryName,diffUrl,flags,isAnonymous,isMinor,isNew,isRobot,isUnpatrolled,namespace,page,regionIsoCode,regionName,user", "metrics": "count,sum_added,sum_commentLength,sum_deleted,sum_delta,sum_deltaBucket", "shardSpec": { "type": "numbered", "partitionNum": 0, "partitions": 0 }, "binaryVersion": 9, "size": 241189, "identifier": "wikipedia_2016-06-27T00:00:00.000Z_2016-06-27T01:00:00.000Z_2020-06-20T04:10:01.833Z" }
$ cd /opt/druid/var/druid/segment-cache/wikipedia/2016-06-27T00:00:00.000Z_2016-06-27T01:00:00.000Z/2020-06-20T04:10:01.833Z/0 $ ls
00000.smoosh factory.json meta.smoosh version.bin
1.3.6 Segment 文件
$ kubectl exec -it hdfs-1593317115-namenode-0 bash $ hdfs dfs -get /druid/segments/wikipedia/20160627T000000.000Z_20160627T010000.000Z/2020-06-28T04_10_01.833Z/0_index.zip /tmp/index/ $ exit $ kubectl cp hdfs-1593317115-namenode-0:/tmp/index/0_index.zip /tmp/0_index.zip $ unzip 0_index.zip $ ls
00000.smoosh 0_index.zip factory.json meta.smoosh version.bin
1.3.7 Coordinator 动态配置
$ kill `ps -ef | grep 8081 | grep -v grep | awk '{print $2}'`; export POD_NAME=$(kubectl get pods --namespace default -l "app=druid,release=`helm list | grep druid- | awk '{print $1}'`" | grep coordinator | awk '{print $1}') ; nohup kubectl port-forward $POD_NAME 8081:8081 --address 0.0.0.0 2>&1 & $ curl localhost:8081/druid/coordinator/v1/config | python -m json.tool
{ "balancerComputeThreads": 1, "decommissioningMaxPercentOfMaxSegmentsToMove": 70, "decommissioningNodes": [], "emitBalancingStats": false, "killAllDataSources": false, "killDataSourceWhitelist": [], "killPendingSegmentsSkipList": [], "maxSegmentsInNodeLoadingQueue": 0, "maxSegmentsToMove": 5, "mergeBytesLimit": 524288000, "mergeSegmentsLimit": 100, "millisToWaitBeforeDeleting": 900000, "pauseCoordination": false, "replicantLifetime": 15, "replicationThrottleLimit": 10 }
# 将 maxSegmentsToMove 调整为 50 $ curl -XPOST -H 'Content-Type:application/json' localhost:8081/druid/coordinator/v1/config -d '{"maxSegmentsToMove":50}' $ curl localhost:8081/druid/coordinator/v1/config | python -m json.tool
{ "balancerComputeThreads": 1, "decommissioningMaxPercentOfMaxSegmentsToMove": 70, "decommissioningNodes": [], "emitBalancingStats": false, "killAllDataSources": false, "killDataSourceWhitelist": [], "killPendingSegmentsSkipList": [], "maxSegmentsInNodeLoadingQueue": 0, "maxSegmentsToMove": 50, "mergeBytesLimit": 524288000, "mergeSegmentsLimit": 100, "millisToWaitBeforeDeleting": 900000, "pauseCoordination": false, "replicantLifetime": 15, "replicationThrottleLimit": 10 }
动态配置项 maxSegmentsToMove 可以用于控制同时被 rebalance 的 Segment 数量
1.3.8 Druid SQL 查询
# 映射 Broker 容器的 8082 端口 $ kill `ps -ef | grep 8082 | grep -v grep | awk '{print $2}'`; export POD_NAME=$(kubectl get pods --namespace default -l "app=druid,release=`helm list | grep druid- | awk '{print $1}'`" | grep broker | awk '{print $1}') ; nohup kubectl port-forward $POD_NAME 8082:8082 --address 0.0.0.0 2>&1 & $ echo '{"query":"SELECT COUNT(*) as res FROM wikipedia"}' > druid_query.sql $ curl -XPOST -H'Content-Type: application/json' http://localhost:8082/druid/v2/sql/ -d@druid_query.sql
[{"res":24433}]
二、配置
2.1 常用端口

生产中,建议将 ZooKeeper 和 Metadata Stroage 部署在独立的物理机上,而不是混合部署在 Coordinator 节点上
2.2 rollup
在 Apache Druid 0.9.2 版本之后,我们可以通过在 granularitySpec 中配置 "rollup": false,来完全关闭 RollUp 特性,即在数据摄入的过程中,不做任何的预聚合,只保留最原始的数据点。即便是同一时刻的、具有相同维度的、完全相同的多个数据点,都会全部存储下来,不会发生覆盖写
2.3 selectStrategy
该参数默认为 fillCapacity,意味着分配 Task 的时候,会将某个 MiddleManager 分配满,才会分配新的 Task 到其他 MiddleManager 上。这里可以考虑使用 equalDistribution 策略,将 Task 均匀分配到 MiddleManager 上
$ cd $DRUID_HOME $ vim conf/druid/overlord/runtime.properties
druid.indexer.selectStrategy=equalDistribution
在 0.11.0 版本中,默认策略已经改成了 equalDistribution。详见 WorkerBehaviorConfig#DEFAULT_STRATEGY
2.4 maxRowsPerSegment
该参数用于控制每个 Segment 中最大能够存储的记录行数(默认值为 500,0000),只有二级分区采用的是 dynamic 才会生效。如果 spec.tuningConfig.type 设置的是 hashed,则需要指定 shard 的数量,以及哪些 Dimension 被用于 hash 计算(默认为所有 Dimension)。另外,在 dynamic 类型的二级分区中,还有一个 maxTotalRows 参数(默认值为 2000,0000),用来控制所有尚未被存储到 Deep Storage 中的 segment 的记录行数,一旦达到 maxTotalRows 则会立即触发 push 操作
如果该参数设置得很低,会产生很多小的 Segment 文件。一方面,如果 DeepStorage 为 HDFS 的话,会触发小文件问题,影响到集群性能(访问大量小文件不同于访问少数大文件,需要不断地在 DataNode 之间跳转,大部分时间都会耗费在 task 的启动和释放上,并且 NameNode 要监控的数据块变多后,网络带宽和内存占用也会比高,还会拖慢 NameNode 节点的故障恢复);另一方面,如果操作系统中 vm.max_map_count 参数为默认的 65530 的话,可能会达到这个阈值,使得 MMap 操作失败,进而导致 Historical 进程 crash 退出,如果 Segment 一直无法完成 handoff 的过程,则会促使 Coordinator 进程 kill 实时任务
2.5 druid.server.tier
该参数相当于给 Historical 节点加了一个标签,可以将相同 Tier 名称的 Historical 进行分组,便于实现冷热分层。在 historical/runtime.properties 配置文件中设置,默认值为 _default_tier。例如,可以创建 hot、cold 两个 Tier,hot Tier 用于存储最近三个月的数据,cold Tier 用于存储最近一年的数据。如此一来,因为 cold 分组下的 Historical 节点存储的数据只需要应对一些低频查询,便可以使用非 SSD 的磁盘,以节约硬件成本
2.6 tieredReplicants
该参数用于在 Rule 中设置 Tier 存储的副本数量。假设将 tieredReplicants 设置为 2 之后,数据便会在不同的 Historical 节点上各自存储一份,以避免某一个 Historical 故障,而影响到查询
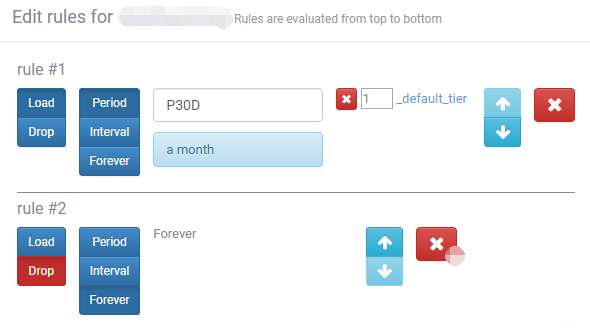
2.7 Coordinator Rule 配置
保留最近 30 天数据
文章知识点与官方知识档案匹配,可进一步学习相关知识
