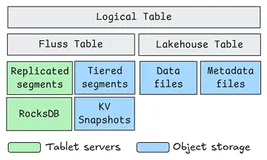
三、架构演进
设计总图
Apache Druid 初始版本架构图 ~ 0.6.0(2012~2013)

0.7.0 ~ 0.12.0(2013~2018)
Apache Druid 旧架构图——数据流转
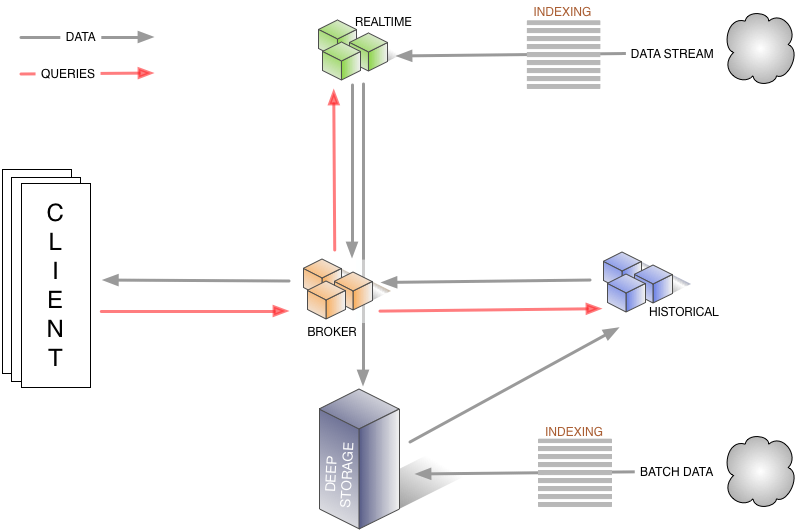
查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点
Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage
Apache Druid 旧架构图——集群管理

0.13.0 ~ 当前版本(2018~now)
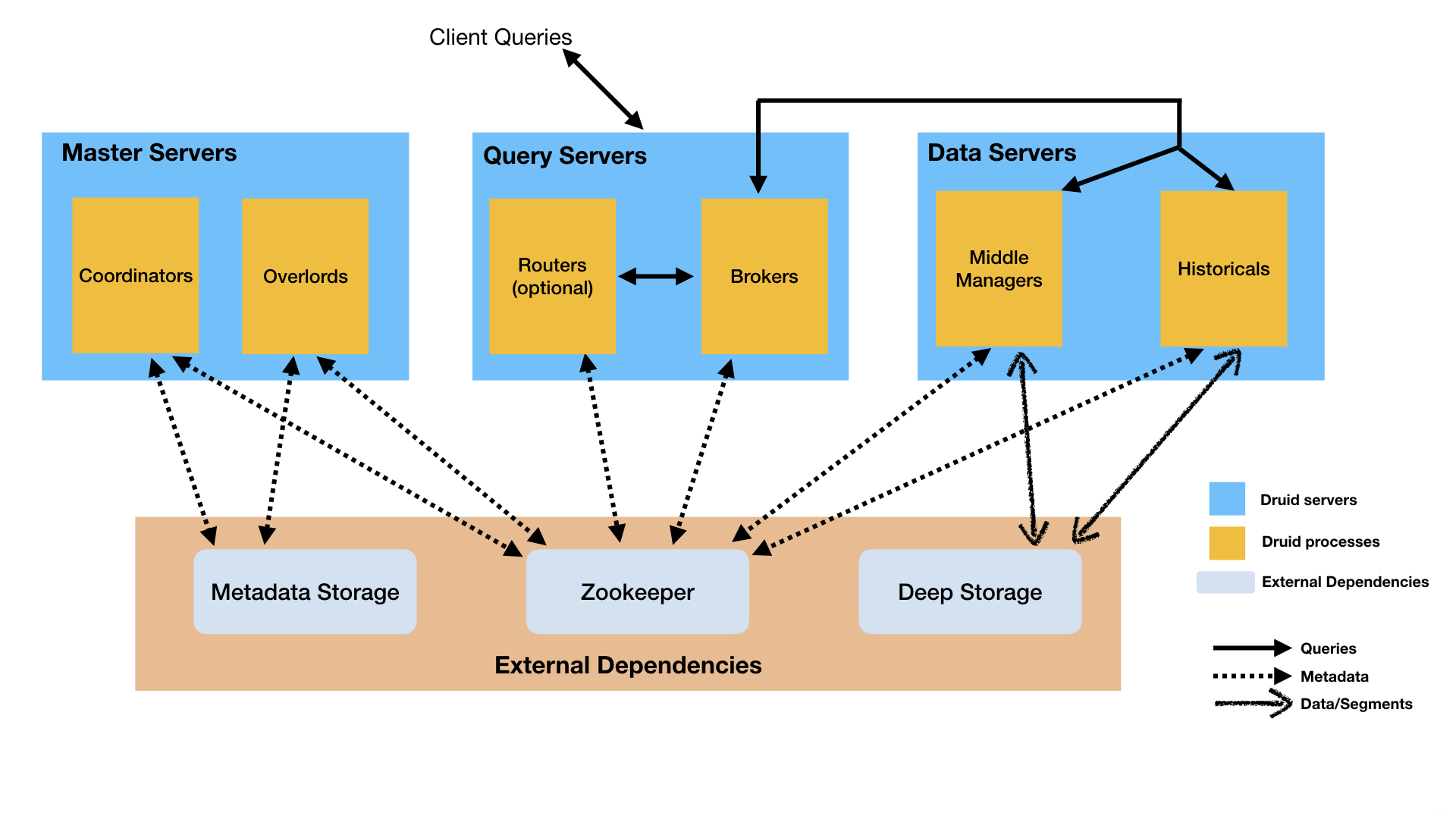
从架构图中可以看出来 Apache Druid 集群的通讯是基于 Apache ZooKeeper 的。
四、Lambda 流式架构

通常流式数据的链路为 Raw data → Kafka → Stream processor(optional, typically for ETL) → Kafka(optional)→ Druid → Application / user,而批处理的链路为 Raw data → Kafka(optional)→ HDFS → ETL process(optional)→ Druid → Application / user