

写在前面:
感谢大家的关注。在此声明:博客的本意是供自己存档实验报告,同时便于同学之间相互交流遇到的问题。 欢迎大家评论和私信自己遇到的问题和解决方案,让我们共同进步。
VGG19模型文件及实验用图下载地址(无需积分,直接下载,如遇404说明资源在审核,csdn审核为2-10个工作日):
https://download.csdn.net/download/qq_43554335/34058130
下面是我在调试代码过程中遇到的一些问题及解决方案,希望对您有所帮助。
Q1:Variable += value not supported. Use variable.assign_add(value) to modify the variable value and variable = variable + value to get a new Tensor object.
A1:不支持+=这种写法,就是把l+=dd这种写法变成l=l+dd就可以了,替换如图:


Q2:RuntimeError: tf.gradients is not supported when eager execution is enabled. Use tf.GradientTape instead.


A2:使用tf1的compat模式禁用eager-execution约束表单tf2,添加如下代码:
import tensorflow as tf tf.compat.v1.disable_eager_execution()

Q3:
If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
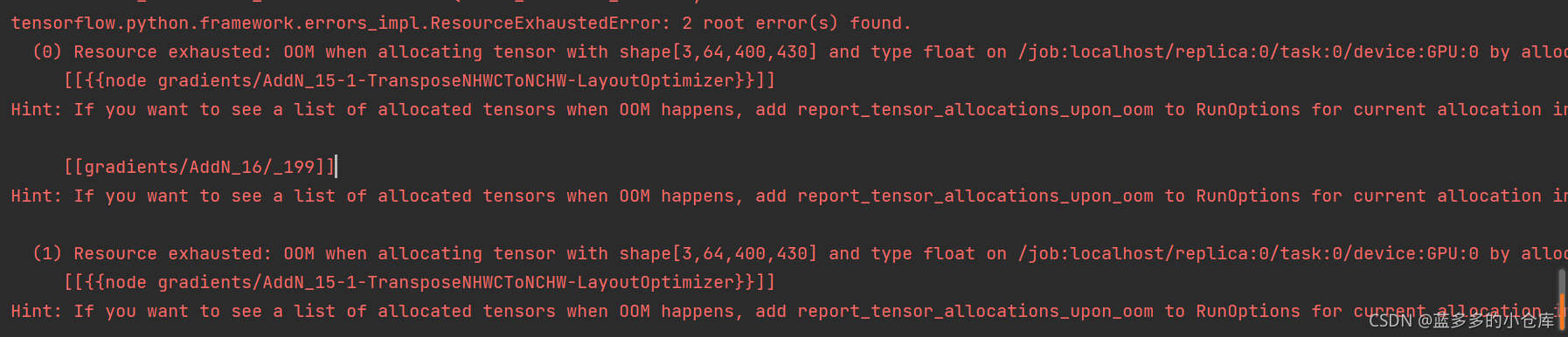

A3:错误原因显卡内存不足
解决方案1:减少Batch_Size大小。(网上说的,我改小了也8行)
Batch就是每次送入网络中训练的一部分数据,而Batch_Size就是每个batch中训练样本的数量。
解决方案2:增加pool层,降低整个网络的维度。(没试,有兴趣可以试试)
解决方案3:修改输入图片的大小,将图片尺寸改小。(然而我试了并8行)
解决方案4:指定第二块GPU,添加如下代码:(我采用的是这个方式,由于显卡问题,运行的比较慢,需要耐心等待)
import os os.environ["CUDA_VISIBLE_DEVICES"] = "2"#指定第二块GPU

这里推荐两个基础学习链接:
1、深度学习中的Epoch,Batchsize,Iterations,都是什么鬼?
深度学习中的Epoch,Batchsize,Iterations,都是什么鬼? - 简书
2、深度学习笔记:windows+tensorflow 指定GPU占用内存(解决gpu爆炸问题)
深度学习笔记:windows+tensorflow 指定GPU占用内存(解决gpu爆炸问题)_去向前方的博客-CSDN博客
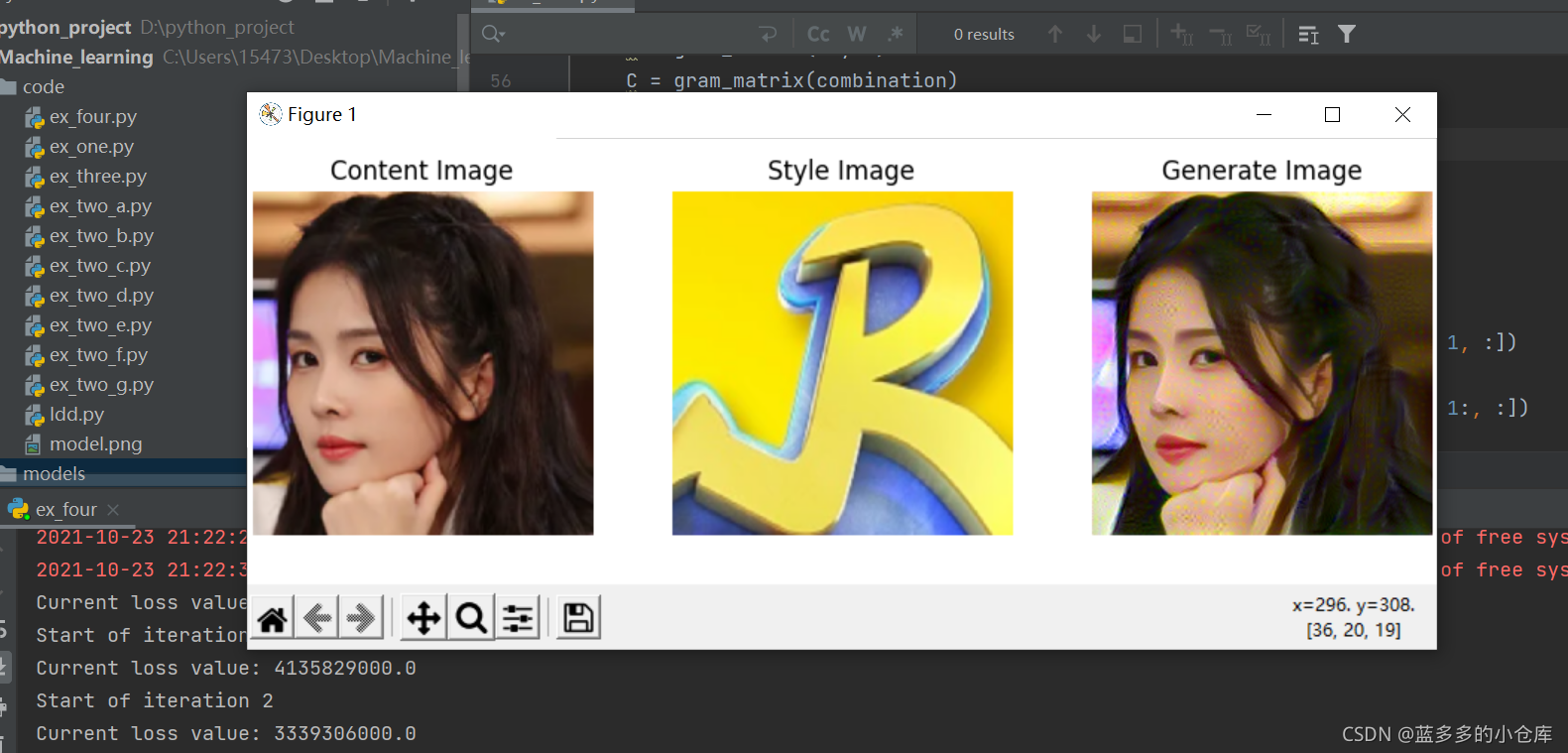
实验结果截图

完整代码(代码来源指导书,再次强调不许截图我的白鹿)
from keras.preprocessing.image import load_img, img_to_array import numpy as np from keras.applications import vgg19, inception_v3 from keras import backend as K import matplotlib.pyplot as plt import scipy from scipy.optimize import fmin_l_bfgs_b import time import tensorflow as tf tf.compat.v1.disable_eager_execution() #import os #os.environ["CUDA_VISIBLE_DEVICES"]="" import os os.environ["CUDA_VISIBLE_DEVICES"] = "2"#指定第二块GPU target_image_path = '../sources/bailu.png' style_reference_image_path = '../sources/benpaoba.png' width, height = load_img(target_image_path).size img_height = 400 img_width = int(width * img_height / height) #定义函数preprocess_image()用于做图像预处理。将图像从指定路径读入,调整为高度为400的尺寸,并做输入VGG19模型的预处理。 def preprocess_image(image_path): img = load_img(image_path, target_size=(img_height, img_width)) img = img_to_array(img) img = np.expand_dims(img, axis=0) img = vgg19.preprocess_input(img) return img def deprocess_image(x): # Remove zero-center by mean pixel x[:, :, 0] += 103.939 x[:, :, 1] += 116.779 x[:, :, 2] += 123.68 # 'BGR'->'RGB' x = x[:, :, ::-1] x = np.clip(x, 0, 255).astype('uint8') return x target_image = K.constant(preprocess_image(target_image_path)) style_reference_image = K.constant(preprocess_image(style_reference_image_path)) combination_image = K.placeholder((1, img_height, img_width, 3)) input_tensor = K.concatenate([target_image, style_reference_image, combination_image], axis=0) model = vgg19.VGG19(input_tensor=input_tensor, weights='../models/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5', include_top=False) #定义工具函数content_loss()用于计算原始图像和生成图像的内容损失。 def content_loss(base, combination): return K.sum(K.square(combination - base)) #定义工具函数style_loss()用于计算参考图像和生成图像的风格损失。 def gram_matrix(x): features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1))) gram = K.dot(features, K.transpose(features)) return gram def style_loss(style, combination): S = gram_matrix(style) C = gram_matrix(combination) channels = 3 size = img_height * img_width return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2)) #定义工具函数total_variation_loss()用于计算生成图像的空间连续性,可以看作正规化损失。 def total_variation_loss(x): a = K.square( x[:, :img_height - 1, :img_width - 1, :] - x[:, 1:, :img_width - 1, :]) b = K.square( x[:, :img_height - 1, :img_width - 1, :] - x[:, :img_height - 1, 1:, :]) return K.sum(K.pow(a + b, 1.25)) # Dict mapping layer names to activation tensors outputs_dict = dict([(layer.name, layer.output) for layer in model.layers]) # Name of layer used for content loss content_layer = 'block5_conv2' # Name of layers used for style loss style_layers = ['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1'] # Weights in the weighted average of the loss components total_variation_weight = 1e-4 style_weight = 1. content_weight = 0.025 # Define the loss by adding all components to a `loss` variable loss = K.variable(0.) layer_features = outputs_dict[content_layer] target_image_features = layer_features[0, :, :, :] combination_features = layer_features[2, :, :, :] #loss += content_weight * content_loss(target_image_features,combination_features) loss = loss + content_weight * content_loss(target_image_features,combination_features) for layer_name in style_layers: layer_features = outputs_dict[layer_name] style_reference_features = layer_features[1, :, :, :] combination_features = layer_features[2, :, :, :] sl = style_loss(style_reference_features, combination_features) loss += (style_weight / len(style_layers)) * sl loss += total_variation_weight * total_variation_loss(combination_image) # Get the gradients of the generated image wrt the loss grads = K.gradients(loss, combination_image)[0] # Function to fetch the values of the current loss and the current gradients fetch_loss_and_grads = K.function([combination_image], [loss, grads]) class Evaluator(object): def __init__(self): self.loss_value = None self.grads_values = None def loss(self, x): assert self.loss_value is None x = x.reshape((1, img_height, img_width, 3)) outs = fetch_loss_and_grads([x]) loss_value = outs[0] grad_values = outs[1].flatten().astype('float64') self.loss_value = loss_value self.grad_values = grad_values return self.loss_value def grads(self, x): assert self.loss_value is not None grad_values = np.copy(self.grad_values) self.loss_value = None self.grad_values = None return grad_values evaluator = Evaluator() #调用程序包scipy.optimize中的函数fmin_l_bfgs_b()做梯度下降,共计3次迭代。 iterations = 3 x = preprocess_image(target_image_path) x = x.flatten() for i in range(iterations): print('Start of iteration', i) start_time = time.time() x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x, fprime=evaluator.grads, maxfun=20) print('Current loss value:', min_val) # Save current generated image img = x.copy().reshape((img_height, img_width, 3)) img = deprocess_image(img) end_time = time.time() print('Iteration %d completed in %ds' % (i, end_time - start_time)) # Content image plt.figure(figsize=(8,3)) plt.subplots_adjust(left=0.0, right=1.0) plt.subplot(131) plt.title('Content Image') plt.imshow(load_img(target_image_path, target_size=(img_height, img_width))) plt.axis('off') plt.subplot(132) plt.title('Style Image') plt.imshow(load_img(style_reference_image_path, target_size=(img_height, img_width))) plt.axis('off') plt.subplot(133) plt.title('Generate Image') plt.imshow(img) plt.axis('off') plt.show()


