
一、MySQL主从搭建#
搭建主从架构的MySQL常用的有两种实现方式:
- 基于binlog的fileName + postion模式完成主从同步。
- 基于gtid完成主从同步搭建。
本篇就介绍如何使用第一种方式完成MySQL主从环境的搭建。
基于fileName和position去实现主从复制,所谓的fileName就是bin-log的name,position指的是slave需要从master的binlog的哪个位置开始同步数据。
这种模式同步数据方式麻烦的地方就是需要我们自己通过如下的命令去查找应该从哪个bin-log的哪个position去开始同步。
二、主库#
2.0、确定主库的binlog是否开启#
命令:
SHOW VARIABLES LIKE 'log_bin';
原因:了解MySQL中常见的三个日志:
- 单机MySQL的undolog日志中记录着如何将现有的数据恢复成被修改前的旧数据。
- 单机MySQL的redolog. 中记录事物日志。
- 主从模式的MySQL通过bin-log日志同步数据。
2.1、设置master的binlog#
重置
reset master;
查看binlog
show binary logs
2.2、骚气的命令#
grant replication slave on *.* to mysqlsync@"127.0.0.1" identified by "mysqlsync123";
这条命令是在干什么呢?
捋一下思路:我们做主从同步,在主库这边我们其实会单独创建一个账号用于实现主从同步。下面的命令其实就会帮我们创建出 username=mysqlsync password=mysqlsync123的账户专门用户主从同步使用。
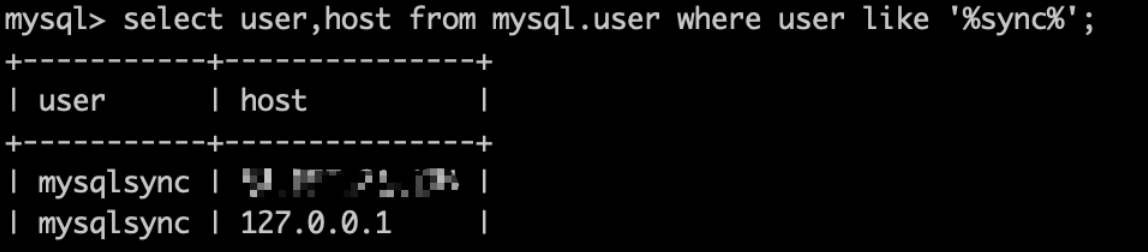
执行完上面的命令后,执行如下的命令查看上面的grant执行结果:
select user,host from mysql.user where user like '%mysqlsync%';
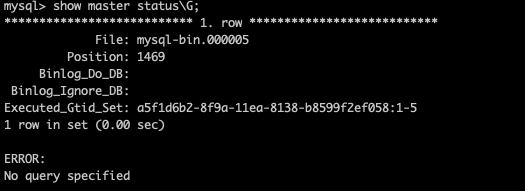
2.3、记录主库的master状态#
注意主库的查看主库当前是第几个binlog,以及数据的position。
因为一会从库就是根据这两个信息知道自己该从主库的第几个binlog的什么positon开始同步。
三、从库#
3.1、从库和主库保持同步#
从库执行change语句,和主库保持同步
CHANGE MASTER TO MASTER_HOST='10.157.23.158', MASTER_USER='mysqlsync', MASTER_PASSWORD='mysqlsync123', MASTER_PORT=8882, MASTER_LOG_FILE='mysql-bin.000008', MASTER_LOG_POS=1013; CHANGE MASTER TO MASTER_HOST = '${new_master_ip}', MASTER_USER = '${user}', MASTER_PASSWORD = '${password}', MASTER_PORT = ${new_master_port}, master_auto_position = 1; CHANGE MASTER TO MASTER_HOST = '10.157.23.123', MASTER_USER = 'mysqlsync', MASTER_PASSWORD = 'mysqlsync123', MASTER_PORT = 8882, master_auto_position = 1;
3.2、开启主从同步#
start slave show slave status \G
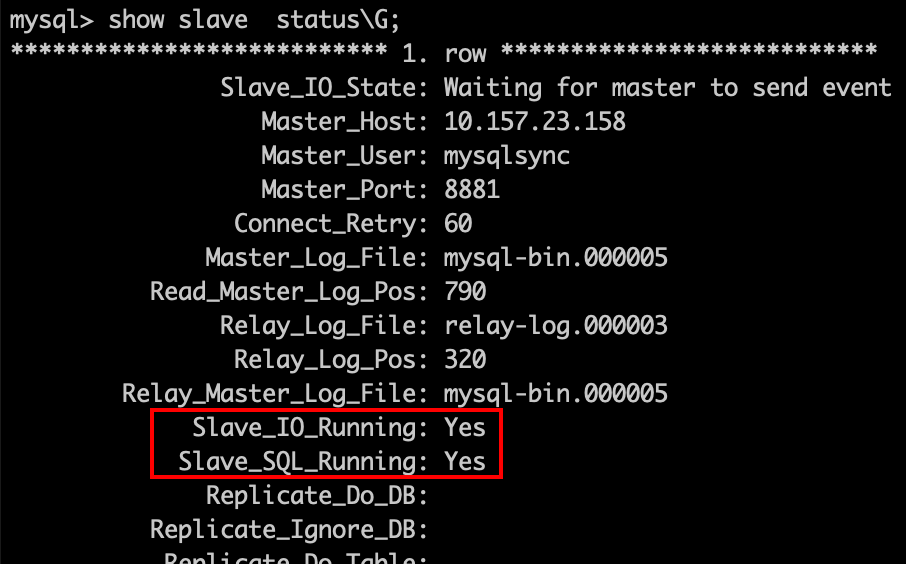
当我们可以看到 io线程和sql线程的状态都是yes时,说明此刻主从同步已经搭建完成了。
3.3、从库:如何断开主从#
stop slave io_thread; stop slave sql_thread;
3.4、主库:如何断开主从#
把用于进行主从同步的账号删除就好了
drop user ${user}@${slave_ip}
四、中断处理#
中断处理部分说的是,一开始我们搭建主从很可能并不是一番风顺的,就比如上面的Slave_IO_Running和Slave_SQL_Running很可能处于NO的状态。下面介绍一下常见的解决方式。
4.1、Slave_IO_Running异常#
Slave_IO_Running:no/connecting
这说明从库连接不上主库,或者是一直处于正在连接的状态。
可能是主库没有对从库进行授权,如果已经授权了那么重启一下salve。
另一种原因就是master和slave的mysqld相关配置文件中,配置了相同server_id。
还有可能你在执行change master命令时,输入的主库相关的信息本来就是错误的。
4.2、Slave_Sql_Running异常#
Slave_Sql_Running:no
一般这种情况是bin-log中的sql出问题了。
第一种情况:可能我们配置了slave只能读,但是却有写请求打过来了,导致slave不能继续往下执行。
第二种解决思路:让slave跳过有问题的这个事件,但是还是得把事件的原因查明白,不然不推荐直接跳过这个事件。
stop slave; set global sql_slave_skip_counter=1; start slave;
第三种思路:我们提前配置好错误号机制,当slave在同步的过程中,碰到我们配置的错误号采取自动跳过的机会而不再去默认的终止同步数据。
# 一般我们可以像下面这样,在my.cnf中的[MySQLd]的启动参数中添加如下内容 --slave-skip-errors=1062,1053 --slave-skip-errors=all --slave-skip-errors=ddl_exist_errors # 通过如下语句查看当前MySQL配置的变量 MySQL> show variables like 'slave_skip%'; # 通过如下命令可以查看到出现的errorno show slave status; # 观察Last_Errno # 常见的errorno 1007:数据库已存在,创建数据库失败 1008:数据库不存在,删除数据库失败 1050:数据表已存在,创建数据表失败 1051:数据表不存在,删除数据表失败 1054:字段不存在,或程序文件跟数据库有冲突 1060:字段重复,导致无法插入 1061:重复键名 1068:定义了多个主键 1094:位置线程ID 1146:数据表缺失,请恢复数据库 1053:复制过程中主服务器宕机 1062:主键冲突 Duplicate entry '%s' for key %d
第四种思路:手动给slave调整fileName和position的位置(如何允许放弃之前的一部分数据,而从当前最新的数据开始同步)
# 停掉slave slave stop # 进入master # 停止master的写操作 # 查看master中当前bin-log和position show master status; # 切换回slave从新根据最新的position和bin-log进行同步 # 进入master,开启master的写操作



