近些年来物联网技术高速发展,广泛应用到了诸如智慧出行、智慧工业、智能家居等场景中,无论是何种场景的应用,都离不开对数据的“采集-处理-存储-分析”这套流程。但是不同的应用,其自身的数据特性和业务需求大不相同,那么对于实现上述流程所需的产品组件也会有所区别。总体来说,我们可以按照应用和数据特点分为三类场景:时序数据、消息数据、元数据。

如上图展示了物联网场景的三大类数据。以智能汽车场景为例,车辆定时会更新当前的最新状态信息,例如发动机当前转速、当前车速等,这些描述车辆最新状态信息的数据我们称之为元数据。而在智能汽车行驶过程中,车辆的状态数据会随着时间的变化而变化,例如车辆一段时间内的车速、胎压等,这些描述车辆历史状态信息的数据我们称之为时序数据。还有一种数据场景是对车辆行为进行控制的指令消息,例如调节车辆空调温度指令下发以及车辆执行命令后的结果反馈,这些控制指令的上下行我们称之为消息数据。不同类型的数据应用的场景各不相同,所以对存储系统的需求也有所不同。本文章主要分析设备元数据场景有哪些业务需求,以及如何选择合适的存储组件和实现方案。
场景需求
首先以工业设备元数据场景为例,来分析有哪些具体的业务需求。
在工业生产过程中,通常设备会以某个固定的周期(或由某个事件触发)上报最新运转状态信息,这也就是上文提到的设备元数据,例如设备 ID ,当前运转温度、湿度、压力值等。业务上根据设备元数据来管理设备,例如查询某台设备的当前运转状态,多条件在线检索设备,“圈选”出符合条件的设备集合。通过分析设备元数据来实时监控设备的运转状态,出现异常及时响应,避免故障发生等。下面对业务需求做一个小结:
a. 设备状态数据定时上报,通过数据网关上云存储。
b. 存储侧需要能够支持大规模设备元数据实时更新。
c. 存储侧需要支持根据任意个设备指标作为条件查找设备。如果查询设备量较少,我们称之为“设备检索”;如果一次查找的设备数量非常大,我们称之为“设备圈选”。
d. 设备状态更新后,存储侧需要支持对异常状态实时监测。
技术难点
根据上面的场景需求,我们可以总结为对存储侧的几个功能需求:
1. 存储规模:支持海量设备元数据存储,可能达到千万级甚至亿级。
2. 实时更新:支持高并发、低延迟的数据更新。
3. 任意字段组合检索:支持根据一个或多个字段值组合条件来检索设备元数据。
4. 支持并发检索:对应设备圈选的场景,在设备圈选的结果集较大的场景下,需要支持并发检索以提升圈选性能。
5. 数据更新实时计算:能够探测数据更新,并能够对更新后数据进行实时计算。
存储选型
元数据存储场景对数据库的规模、性能、查询能力等各个方面都有较高的要求。通常来说,关系型数据库 MySQL 都是作为存储选型的第一选项,这是因为 MySQL 是最为通用,大家也最为熟悉的数据库产品。然而 MySQL 一般只在小规模的数据存储(千万级)和低并发的数据更新(一万内 QPS)场景下表现优异,当规模变大时,MySQL 的性能会急剧下降,这显然不满足元数据存储的要求。到这里,大家可能会想到使用开源数据库 HBase,因为 HBase 的分布式架构能够支持大规模数据存储和写入,在这一点上是可以满足元数据存储需求的。但是 HBase 只支持了基于主键(RowKey)查询,无法在属性列上建索引查询,所以在设备检索、圈选时的效率极低,极端情况下可能会以全表扫描加数据过滤的这种方式来查询数据,这一点上无法满足上述的需求。最后我们来看下表格存储 Tablestore,Tablestore 是一款云原生 Serverless 的结构化数据存储,原生具备大规模的数据存储和低延迟数据更新,同时提供了多元索引功能,能够支持任意字段组合检索,是物联网平台底层依赖的核心数据存储系统,支撑了亿级设备的元数据管理。下面对上述几个存储产品在实现元数据存储场景中的能力做一个总结:
存储规模 |
实时更新 |
任意字段组合检索 |
并发检索 |
数据更新实时计算 |
|
MySQL |
小 |
支持(难以扩展) |
支持(单列索引) |
不支持 |
支持 |
HBase |
大 |
支持(水平扩展) |
不支持 |
不支持 |
支持 |
Tablestore |
大 |
支持(水平扩展) |
支持 |
支持 |
支持 |
Tablestore 技术介绍
表格存储 Tablestore 是一款云上的结构化数据存储产品,具备极为丰富的产品功能和生态,提供了物联网存储 Iotstore、宽表引擎、多元索引等能力来满足时序数据、消息数据、元数据场景的需求。针对于时序与消息数据场景的解决方案不在本文章中展开讲解。下面我们来看一下Tablestore 提供了哪些能力来满足元数据存储的场景需求。
Tablestore 采用了多引擎的存储架构,不同的场景需求实现的原理不同,先来看一张图:

其中宽表引擎是一个分布式的数据表,负责设备元数据的存储与更新。宽表引擎采用了多分区(shard)的分布式结构,每一个分区对应了一台 worker。在元数据写入的过程中,路由节点根据主键的范围将写入请求路由到不同的分区进行处理,当某个分区的负载达到瓶颈时,服务端会自动分裂成多个分区,使得宽表引擎的整体吞吐能力能够线性提高。如下图所示:

相比于宽表引擎, 索引引擎底层采用了倒排索引、空间索引等存储结构,能够支持任意数据组合检索、聚合。索引引擎分别提供了两种查询接口:search 和 parallelScan。
o search 接口。search 接口支持多条件组合查询、模糊查询等能力,可以满足设备检索的场景需求。
o parallelScan 接口。parallelScan 接口支持以多并发的方式进行数据检索,能够大幅提高数据返回速度,适用用于设备元数据圈选场景。
Tablestore 提供了与 Flink 实时计算对接的能力,可作为 Flink 的数据源表,将实时变化的设备元数据推送到 Flink 中进行计算,从而实现元数据检测的业务场景。与此同时,支持将计算的结果再写入 Tablestore 的数据表中,来实现记录异常数据结果。
分享完元数据存储场景的需求和 Tablestore 的技术原理后,我们来看看如何搭建一个设备元数据场景的物联网架构。物联网数据上报网关后,根据不同的应用类型一般有三种数据流向,应用服务器订阅消费,持久化存储,转发到消息队列。设备元数据的主要需求是存储和计算,所以我们可以列出一个简单的数据流转过程:网关->存储->流计算。下面将介绍通过物联网平台 + Tablestore + Flink 来搭建元数据管理平台。
物联网平台 + Tablestore + Flink 实现元数据管理方案
基于云上搭建的元数据管理平台架构如下图所示:

上述的架构图中包含了三个组成模块:物联网平台,表格存储 Tablestore、实时计算 Flink。各个模块在架构中承担的角色和功能如下:
· 物联网平台:负责设备元数据接入、设备管理和数据转发。
· 表格存储 Tablestore:数据表负责设备元数据的存储、更新、查询。多元索引负责设备检索和圈选。通道服务提供与实时计算 Flink 对接的能力。
· 实时计算 Flink:负责对设备元数据变化进行流计算作业,可将计算结果回写到 Tablestore 中存储,或对接 Kafka 等消息队列订阅消费。
方案实现
假设某工业生产厂商现有一百万台智能设备,每台设备定时更新自身的温度、湿度、压力数据等状态数据,准备使用上述方案架构来搭建元数据管理平台。数据规模:一亿行数据结构:如下面的 SQL 语句所示
CREATE TABLE device_meta_data (
device_name varchar(100), -- 设备名
humidity decimal(5,2), -- 设备当前湿度
pressure decimal(5,2), -- 设备当前压力值
temperature decimal(5,2), -- 设备当前温度
location varchar(20), -- 设备位置坐标
timestamp long -- 数据上报时间戳
);
开通服务
准备一个阿里云账号,分别开通如下服务。开通步骤请参考产品官网。
· 物联网平台
· 表格存储 Tablestore
· 实时计算 Flink
1. 创建实例和表
首先需要在 Tablestore 中创建实例 metadata-db(数据库),并创建存储元数据和异常结果数据的两张数据表,表名分别为 device_meta_data 和 device_errorResult_data,操作步骤如下图所示。
(1)创建实例。

(2)创建元数据表和异常数据表。

2. 创建产品、模型和设备
在物联网平台控制台中创建产品(product_metadata),物模型(默认模块)、设备(test_deviceName)。一个产品相当于同类型设备的抽象,而物模型则是对设备上报数据结构的定义。
(1)创建产品。

(2)创建物模型。

(3)创建设备。

3. 创建解析器
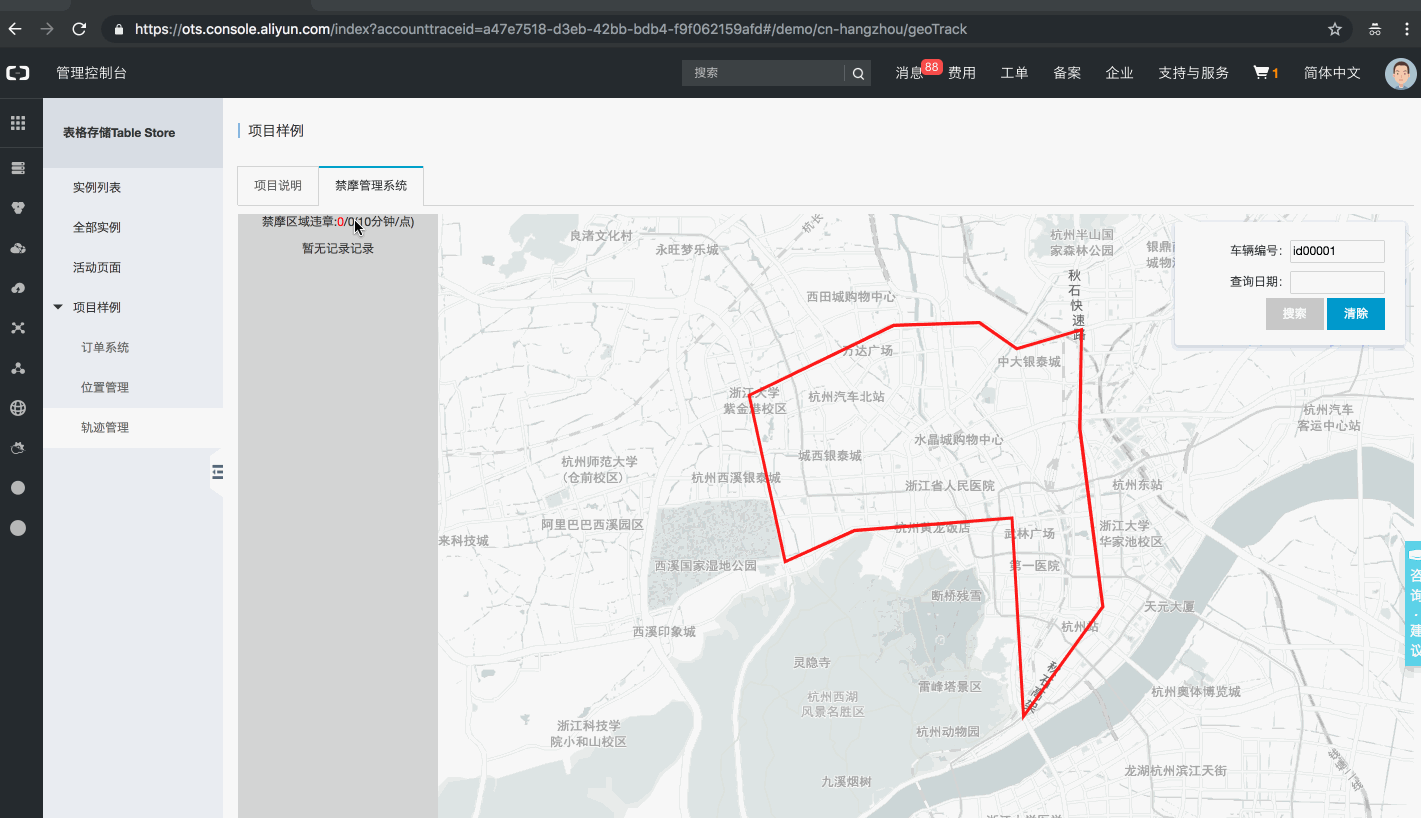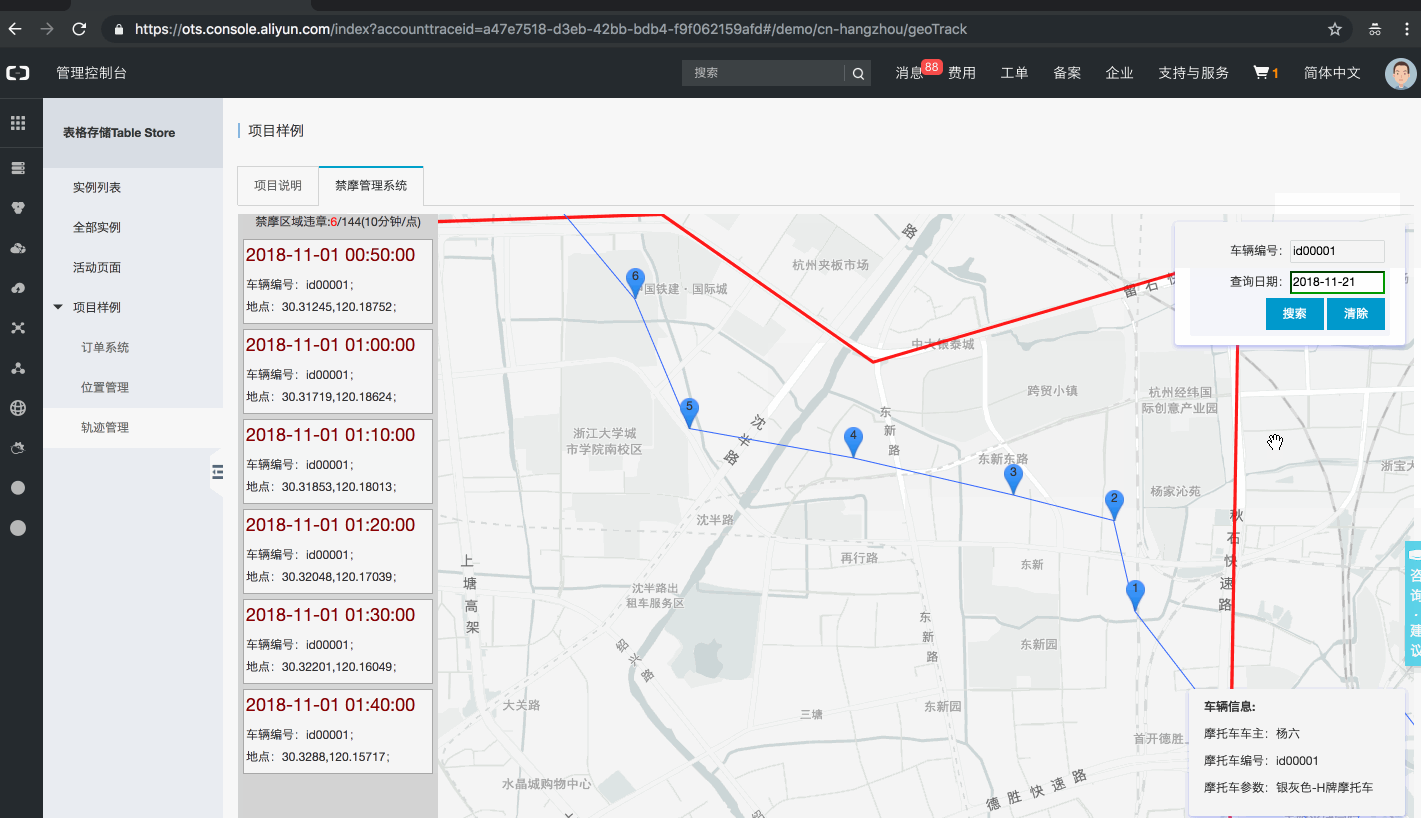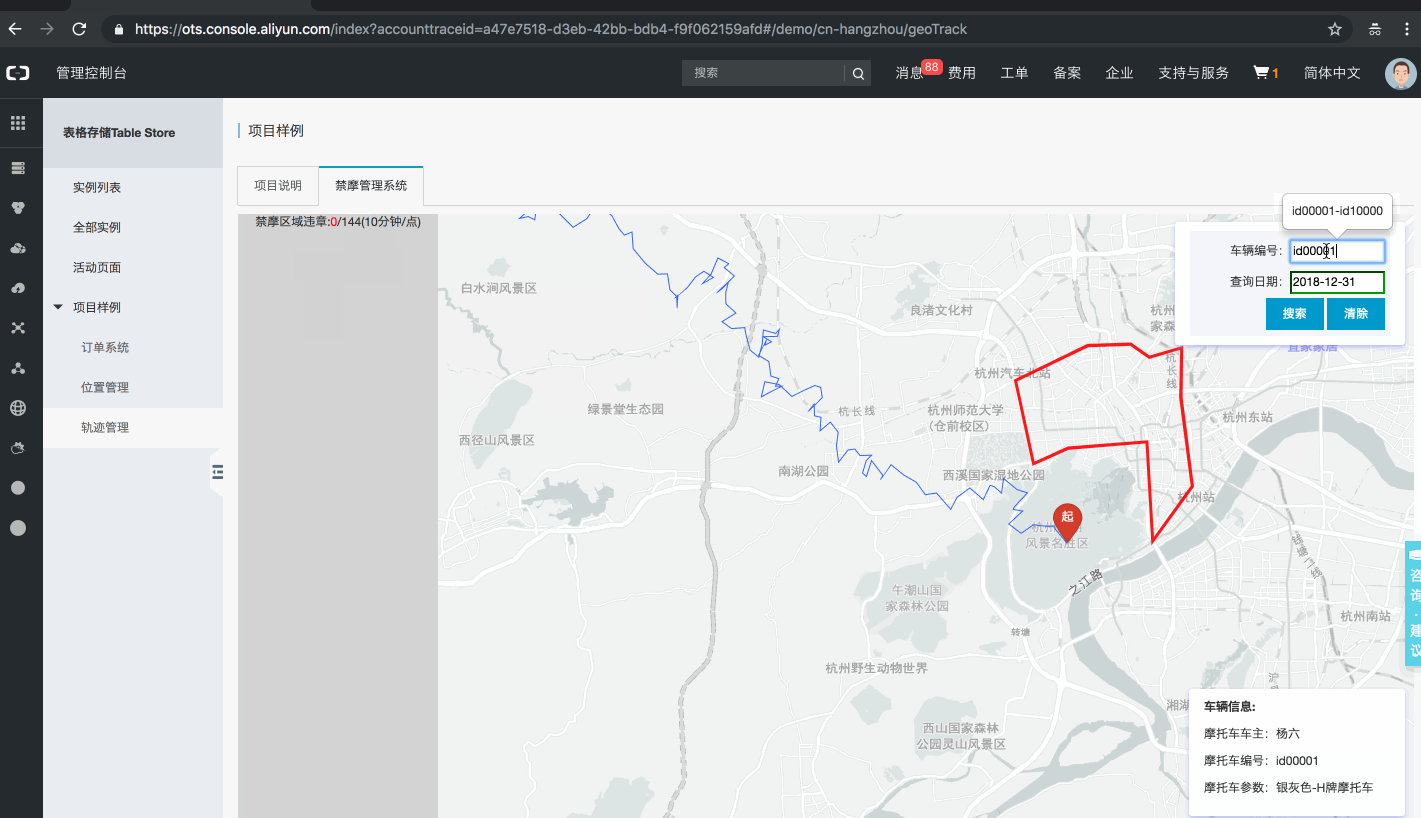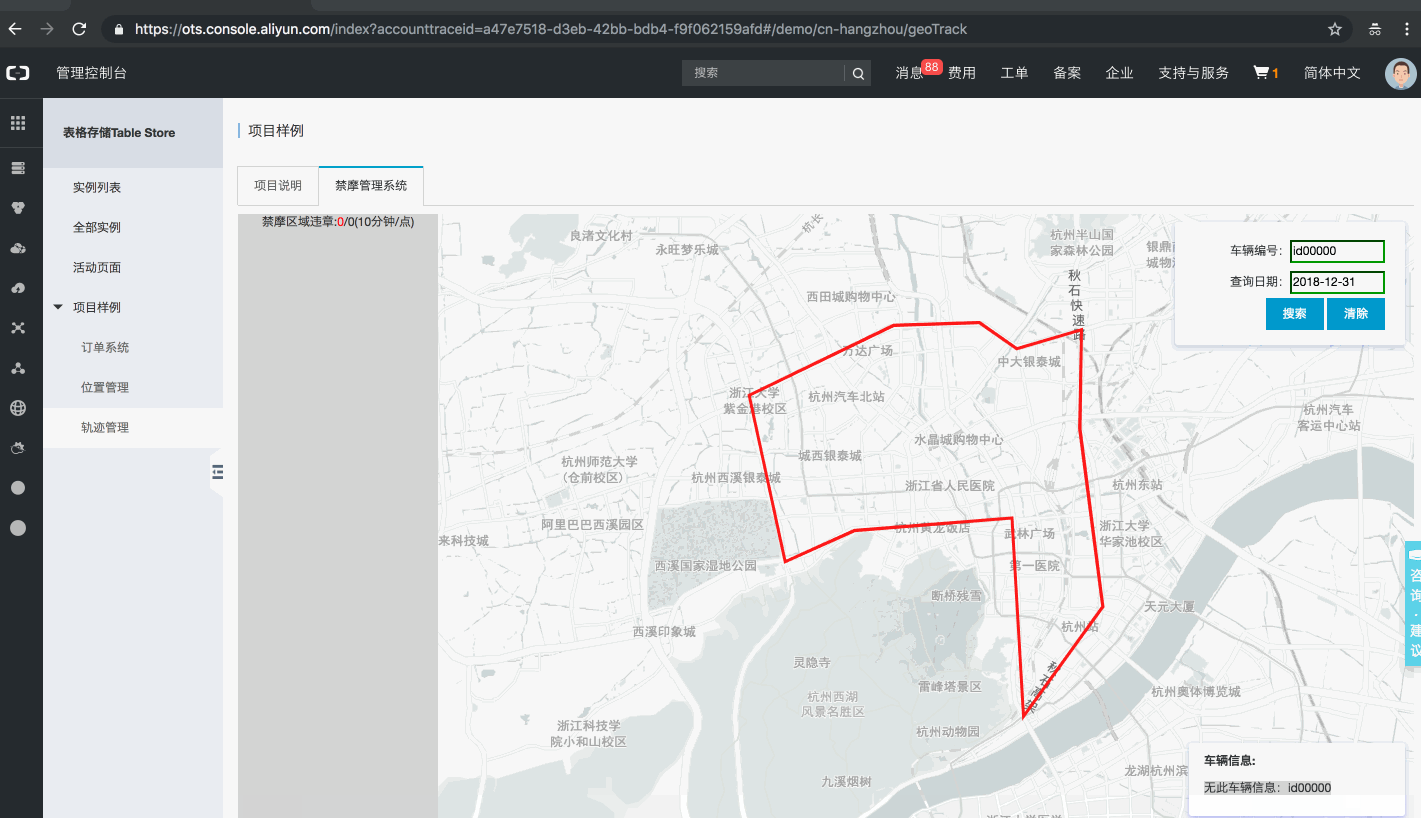
在物联网平台中创建解析器,解析器负责将设备元数据更新的 topic 进行自定义脚本处理后,写入到 Tablestore 中持久化存储。如下图所示:

创建解析器需要分别配置数据源、解析脚本和数据目的。通过物模型上报的设备元数据会汇聚到名为 /产品名/设备名/thing/event/property/post 的 topic 中作为数据源,也可以自定义一个 topic 。数据目的则是配置设备元数据需要写入的 Tablestore 实例名和表名等信息。解析脚本是可以自定义的,例如本案例中将设备的经纬度信息组合成一个坐标字符串写入 Tablestore,如下图所示:

4. 设备上报数据
通常设备上报数据是基于设备端 SDK 开发程序来上报数据到物联网平台中,但为了快速实现方案,本文中使用物联网平台提供的设备模拟器来进行数据上报操作。如下图的一个模拟设备上报了一条数据:

设备元数据经过解析器处理后存储到 Tablestore 中,到此我们已经完成了设备元数据采集与存储的所有操作。
由于设备模拟器只能模拟单台设备元数据产生的过程,为了更贴近真实的业务场景,我们直接在 Tablestore 中生成了一亿条设备元数据以供后续步骤的实现。通过上文我们可以得知,设备检索与圈选需要依赖 Tablestore 的多元索引功能,所以首先我们需要创建一个多元索引device_meta_data_index:

下面将通过 Tablestore 来实现设备元数据查询、检索、圈选等业务需求。
5. 设备查询
Tablestore提供了 SQL、控制台或 SDK 等多种数据访问方式。以 SQL 为例,首先通过 SQL 确认设备元数据已正确导入。
select count(*) from `device_meta_data`;

· 查询 device_name ="test_deviceName" 的设备元数据。
select * from `device_meta_data` where device_name = 'test_deviceName'

6. 设备检索和圈选
设备检索和圈选依赖 Tablestore 的多元索引能力,分别采用 search 和 parallelScan 接口来实现。
(1)设备检索。
先来说设备检索,设备检索通常不会返回比较大的数据结果集,即使符合查询条件的数据量很大,也会采取分页的策略返回。针对于此场景,Tablestore 的多元索引功能采用了倒排索引、空间索引等数据结构来加速数据检索速度,例如下面一个例子:
· 检索设备温度低于 20 摄氏度,压力值在 0.5 kpa 至 1.0 kpa 之间,并且设备名以 “e3” 开头的设备。
select * from device_meta_data where temperature < 20 and pressure between 0.5 and 1.0 and device_name like 'e3%';
(2)设备圈选。
设备圈选通常返回的数据量比较大,如果使用 SQL 只能单并发查询和返回,这样性能显然是不高的。针对这个场景,Tablestore 推出了 parallelScan 接口来实现,parallelScan 接口的优化如下图所示:

在执行设备元数据圈选之前,首先会调用 ComputeSplit 接口根据多元索引中的数据量级来计算最大可执行的查询并发度。然后会按照多并发的方式分别查询多个数据分区,每一并发只负责一部分数据的查询和返回,通过这种方式可以极大地提高数据圈选的速度。如下面一个例子:
· 需要圈选设备名以“a”开头并且设备温度低于 10 摄氏度的所有设备。


从上面代码的运行结果可以看出,查询的数据结果将以多并发的方式返回,每个并发都包含了一部分查询命中的数据。parallelScan 接口在大规模数据圈选、数据导出场景下,平均单个并发可以达到 1W/s 以上的查询返回速度,并且查询数据量越大可切的并发数越高,这种可水平扩展的查询方式极大地提高了数据圈选导出速度。
7. 设备实时监控
设备实时监控依赖于 Tablestore 的通道服务能力,通道服务可以直接对接实时计算 Flink 来实现元数据流计算,如下图所示:

在实时计算中创建了源表、结果表和流计算作业。其中源表依赖 Tablestore 中设备元数据中创建增量通道服务,通道服务将设备元数据的实时变化数据推送到 Flink 计算引擎中进行流计算作业。而本案例中流计算作业将异常的设备状态数据保存到了Tablestore 的异常结果数据表中,后续可通过异常数据结果表中查询某台设备的异常记录信息。针对于异常数据的处理还有一种业务场景是推送到 Kafka 等消息队列中进行处理,如告警机制接入、短信通知等。
update `device_meta_data` set `pressure` = 2.0 where `device_name` =
"test_deviceName"
为了更直观地看到流计算作业效果,我们可以在设备元数据表中更新一条设备元数据:
select * from `device_errorResult_data` where `device_name` = "test_deviceName"

经过流计算引擎处理后,会判定该条数据为异常数据,并自动写入到异常结果数据表中。
总结
本文分享了设备元数据的场景特点和架构实践。设备元数据场景中业务需求对存储组件的存储规模、查询方式以及计算性能有很高的要求,从存储、查询、计算几个维度对比 MySQL、HBase、Tablestore 三款产品,最终选择了采用表格存储 Tablestore 作为元数据场景核心存储库,并运用 Tablestore 上下游生态,打造出 物联网平台 + Tablestore+ 实时计算 Flink 组合作为实现设备元数据存储的云端架构。
联系我们
关于元数据场景的相关介绍就到这里了,后续我们还会分享物联网中时序数据、消息数据的场景与方案。若对本文内容有疑问或希望进一步了解物联网场景里的各种数据存储的方案实现,欢迎加入钉钉群:“表格存储公开交流群-2”。群内提供免费的在线专家服务,欢迎扫码加入,群号:44327024,或扫下方二维码加入。