

作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/84
本文地址:http://www.showmeai.tech/article-detail/167
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
1.大数据的背景
随着互联网高速发展,网络数据呈现出指数级别的快速增长,企业应用需要处理的数据量也变得非常巨大,轻松达到了TB、PB甚至EB、ZB级别,需要巨型存储空间进行存储。而对这些数据进行处理和分析挖掘,仅仅使用单机处理已经无法完成,这个大背景下,针对海量数据处理的大数据解决方案应运而生。ShowMeAI将在接下来的内容中逐步展开讲解大数据生态工具的应用,以及大数据的处理分析挖掘方法。
以下几点,更详细地介绍了大数据技术的相关历史和背景。
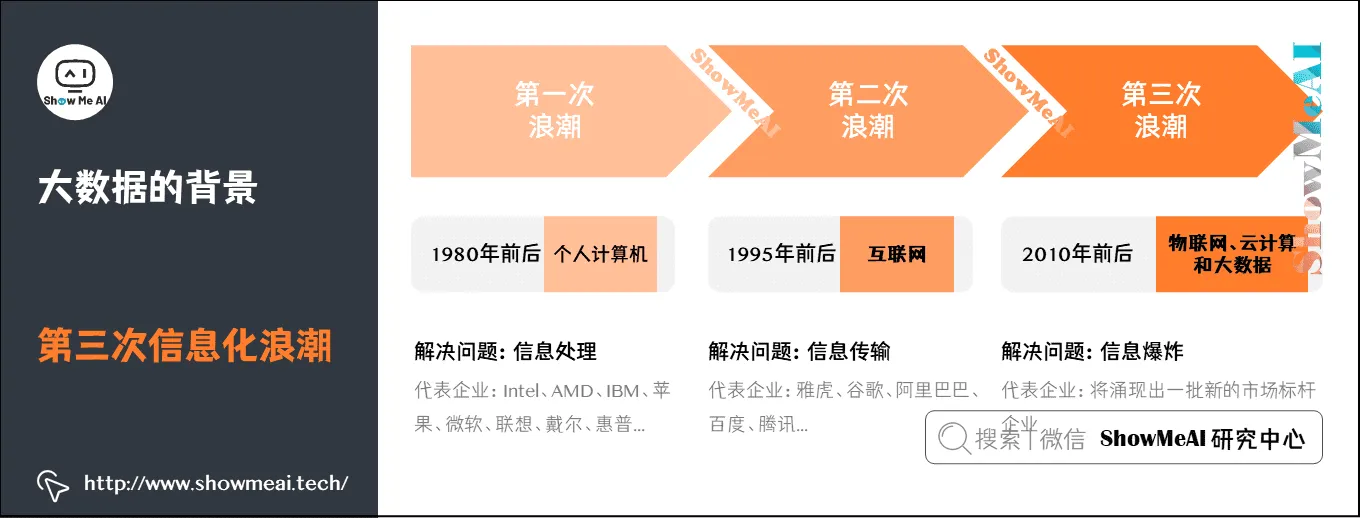
1)第三次信息化浪潮
根据IBM前首席执行官郭士纳的观点,IT领域每隔十五年就会迎来一次重大变革。
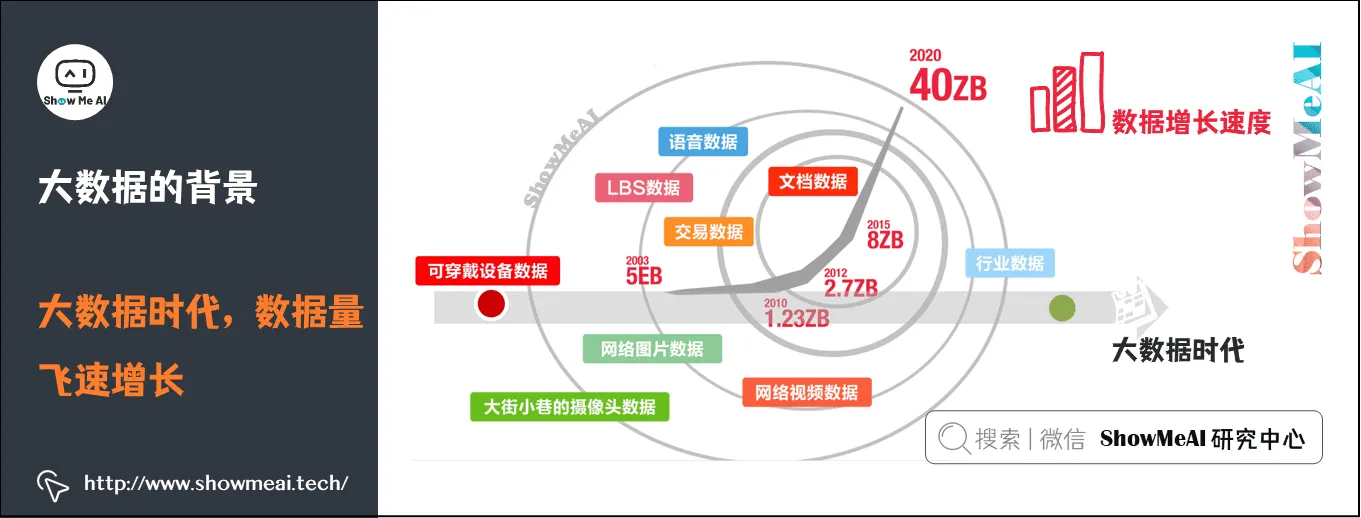
2)数据量飞速增长
移动互联网时代,产生大量的数据。
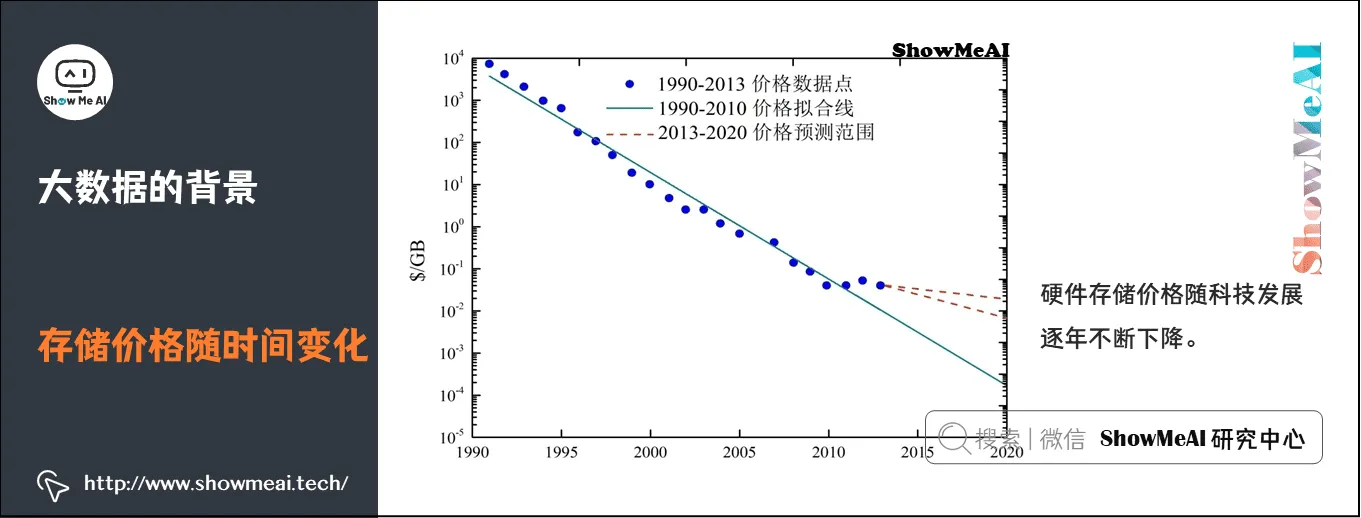
3)存储价格随时间变化
硬件存储价格随科技发展逐年不断下降。
4)数据产生方式的变革
大数据的兴起也跟数据产生方式的变化有关,数据产生方式的变革促成大数据时代的来临。

2.大数据的发展历史
下面我们来看看大数据的发展历史。
1)大数据的发展历程

2)大数据的概念
大数据不仅是数据的“大量化”,而且包含“快速化”“多样化”“价值化”等多重属性。

(1)大量化 Volume
大数据摩尔定律:数据一直都在以每年50%的速度增长,即每两年就增长一倍(IDC)人类在最近两年产生的数据量相当于之前产生的全部数据量。预计到2020年,全球将总共拥有35ZB的数据量,相较于2009年,数据量将增长近44倍。

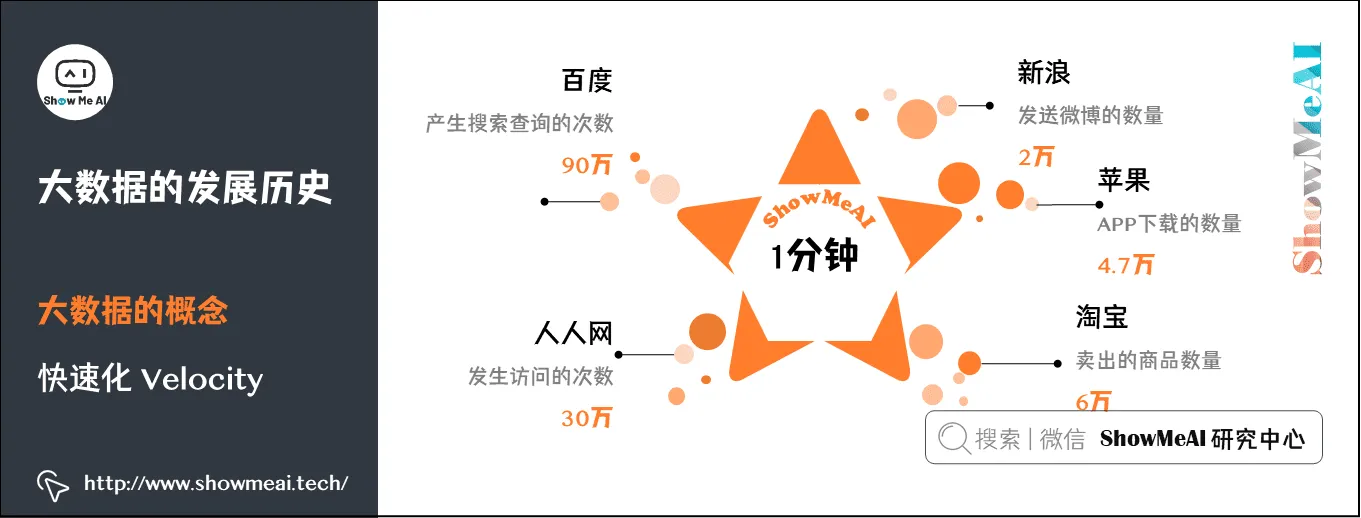
(2)快速化 Velocity
大数据需要很快的处理速度:从数据的生成到消耗,时间窗口非常小,可用于生成决策的时间非常少。1秒定律(秒级定律):这一点和传统的数据挖掘技术有着本质的不同。
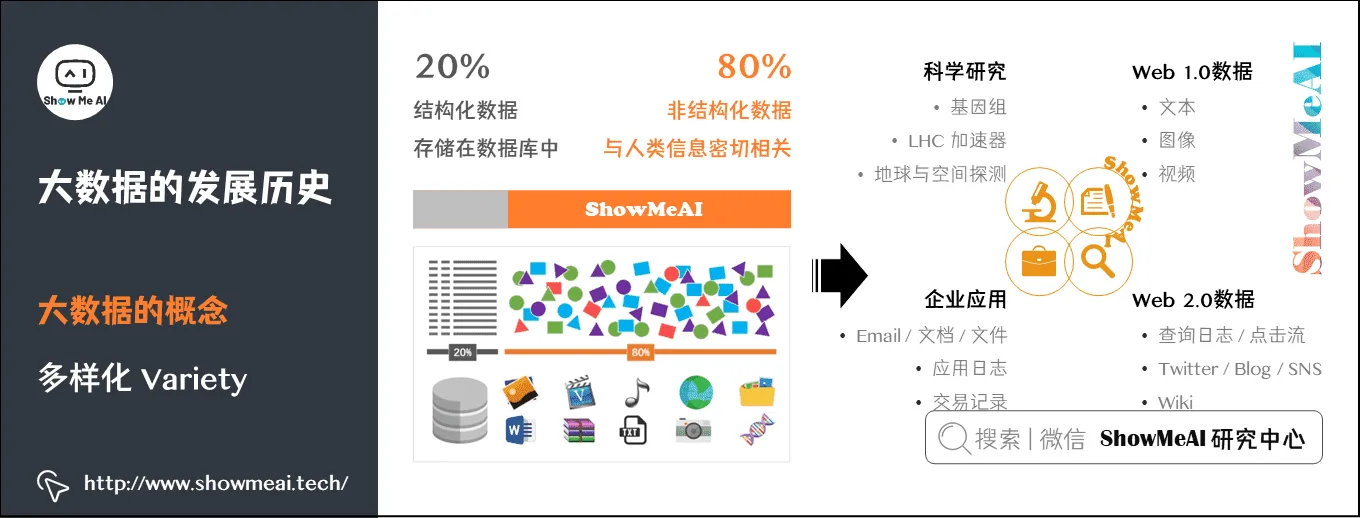
(3)多样化 Variety
大数据数据形态丰富:大数据由结构化数据和非结构化数据组成。
3)大数据生态发展史
伴随着大数据的发展,层出不穷的大数据工具开始诞生和发展,并形成一个大数据生态,下面罗列了一些大数据生态发展史中的典型项目工具,它们也是我们当前处理大数据的主流工具平台。


3.大数据带来的影响
大数据的兴起与高速发展,给我们也带来了很大的影响。
1)大数据带来的影响

- 社会发展:大数据决策逐渐成为一种新的决策方式。大数据应用有力促进了信息技术与各行业的深度融合,大数据开发大大推动了新技术和新应用的不断涌现。
- 就业市场:大数据的兴起使数据科学家成为热门职业。
- 人才培养:大数据的兴起,将在很大程度上改变中国高校信息技术相关专业的现有教学和科研体制。
- 人工智能:人工智能需要海量的数据作为依托,对于海量数据快速处理分析的需求非常强烈。
2)大数据的应用
大数据无处不在,包括金融、汽车、零售、餐饮、电信、能源、政务、医疗、体育、娱乐等在内的社会各行各业都已经融入了大数据的印迹。

下面我们一起来看看大数据在不同行业领域的典型应用场景案例。
电商 - 预测用户行为:用户行为信息就是用户在网站上发生的所有行为。
- 如搜索、浏览、打分、点评、加入购物筐、取出购物筐、加入期待列表、购买、使用减价券和退货等;
- 也包括在第三方网站上的相关行为,如比价、看相关评测、参与讨论、社交媒体上的交流、与好友互动等。
- 对电商大数据AI应用感兴趣的同学可以查看ShowMeAI在电商与用户行为预估垂直领域的一些介绍文章,如《大厂技术实现 | 多目标优化及应用(含代码实现)》
娱乐 - 定制影视节目:大数据在影视作品的制作、发行、放映环节都发挥着重要作用。
- 对于发行方而言,可以根据作品题材,受众群众等数据制定营销策略,比如Netflix通过分析用户数据买下《纸牌屋》版权并开启了大数据对于影视产业的全面渗透;
- 对于投资方和制片方来说,可以利用大数据对投资回报进行预测,减少风险和损失;
- 对于影院来说,可以利用大数据进行排片和票房预测。
- 对娱乐大数据AI应用感兴趣的同学可以查看ShowMeAI在相关垂直领域的一些介绍文章,如《大厂技术实现 | 爱奇艺短视频推荐业务中的多目标优化实践》
医疗 - 预测疾病趋势:从谷歌流感趋势(Google Flu Trends, GFT)是看大数据的应用价值。
- 2008年推出的一款预测流感的产品,通过跟踪搜索词相关数据来判断全美地区的流感情况。
- 对医疗大数据AI应用感兴趣的同学可以查看ShowMeAI在相关垂直领域的一些介绍文章,如《大厂技术实现 | 华为云用于医疗推理的预训练模型和知识图谱整合方案》
交通 - 优化城市交通:目前公共领域率先使用大数据技术的主要是交通行业。
- 曾经的无处可查的套牌车,死板的红绿灯跳转算法,在大数据的影响下都被一一解决,为城市的交通做出巨大的贡献。
环境 - 预警环境污染:为环境保护部门提供强力的数据支撑。
- 影响深远的环境问题,难以使用的大规模环境检测器的数据,在大数据的强大计算能力下,可以做到近乎实时的在大屏上进行呈现,快速预警环境污染问题。
政务 - 智慧城市建设:通过大数据建立起信息集群中心,为城市管理业务提供数据支持。
- 通过信息技术,将城市的系统和服务打通、集成,以提升资源运用的效率,优化城市管理和服务,以及改善市民生活质量。
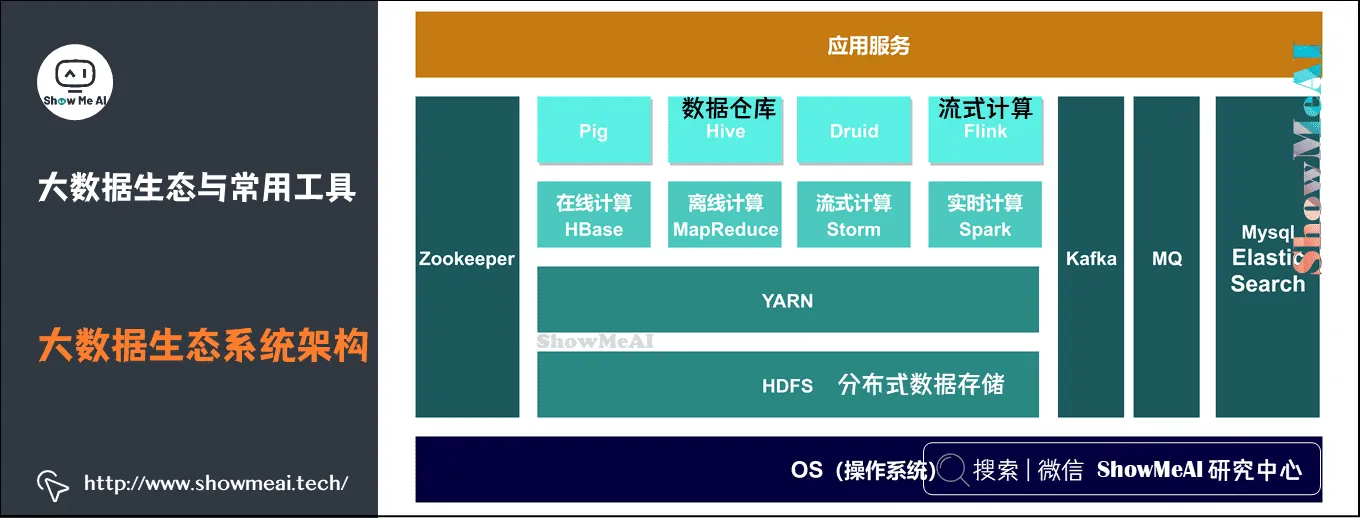
4.大数据生态与常用工具
下面我们来了解一下大数据生态系统架构,以及应用大数据技能,完整的大数据工具技能图谱。如下两图所示~
1)大数据生态系统架构
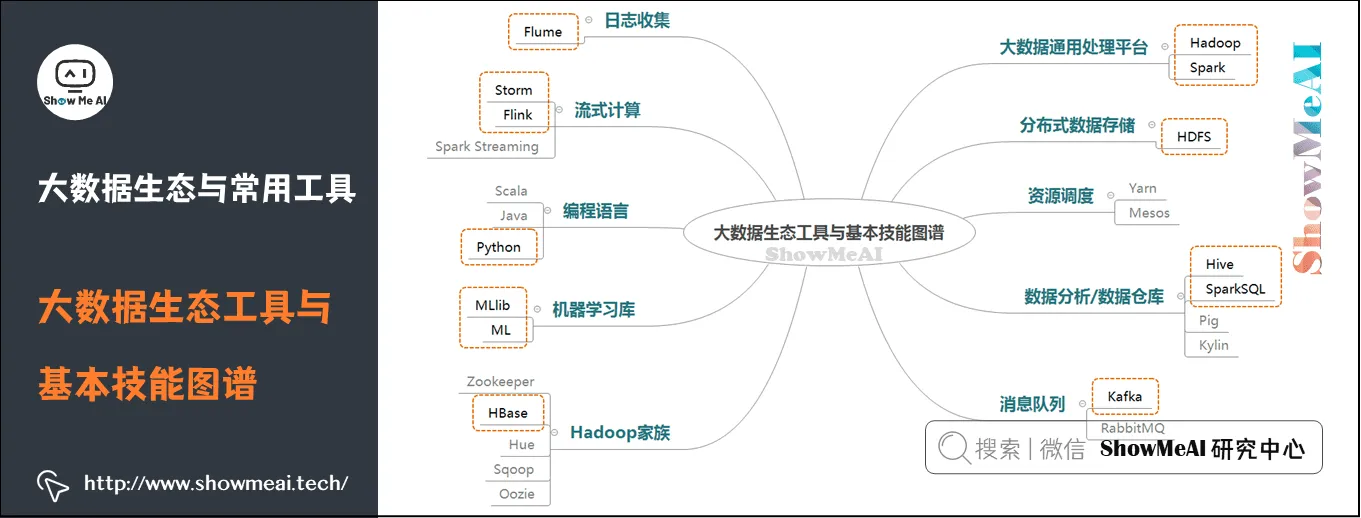
2)常用工具-编程语言
大数据生态工具应用的主流编程语言是Scala、Java,随着AI生态的快速发展,其最常用语言python也被大数据生态工具很好地支持了。目前,在大数据处理场景下,使用Scala、Java或者python进行实现,并不会有特别大的效率差异。
3)常用工具-日志收集:Flume
Flume,Apache下的一个顶级开源项目,一个分布式、可靠的数据收集组件。能够高效的收集,整合数据,还可以将来自不同源的大量数据汇聚到数据中心存储落地。
目前常用于企业内收集整合日志数据,但由于其数据源的可自定义特性,还可用于传输结构化数据(oracle, mysql等),也常被用于流式数据的采集输入工具。
相关学习链接:
- Flume 官方网站: http://flume.apache.org/
- Flume 介绍及其安装:http://blog.51cto.com/13589448/2086140
4)常用工具-分布式数据存储:HDFS
HDFS(Hadoop Distributed File System),全称Hadoop分布式文件系统。Hadoop生态体系的存储底层,用于存储管理大批量文件数据。其自带的容错机制,高度的可拓展性,让其成为现今最适用的开源分布式存储底层系统。
特性:
- 存储数据类型为任意文件,满足大部分的存储使用场景;
- 基于Java平台开发,适配绝大多数PC,服务器;
- 安装高度可配置化,默认配置适用大部分场景,仅部分超大规模集群需要进行特殊的参数优化,可用性与易用性较强。
关于HDFS的更多知识也可以查看ShowMeAI的后续教程了解。
相关学习链接:
- Hadoop 官方文档:https://hadoop.apache.org/docs/stable/index.html
- HDFS 架构介绍:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
- HDFS 命令指南:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
5)常用工具-数据仓库:Hive
Hive是构建于HDFS上的一套分布式结构化数据存储系统,可以狭义的理解为一个开源的分布式数据库,通过SQL语言进行操作,可以较为遍历的处理超大规模下结构化数据的处理分析工作。
特性:
- 底层调用MapReduce计算框架,能够相对快速完成大规模数据的查询和分析工作;
- 数据载入模式支持自定义,且支持多种格式的数据文件,为不同的数据使用场景提供更适合的方案。
关于hive的更多知识也可以查看ShowMeAI的后续教程了解。
相关学习链接:
- Hive 官方文档:http://hive.apache.org/
- Hive 核心基本概念:https://blog.csdn.net/freefish_yzx/article/details/77150248
6)常用工具-Hadoop家族:HBase
HBase是构建于HDFS上的一套分布式非结构化数据存储系统,类似于Redis之类的Key-Value数据库,可以通过key进行大规模数据的快速索引查询。目前常用于在大规模数据中快速查询某些信息记录,例如从几亿用户信息中快速查询某个用户信息。
特性:
- 对于检索key查询value可以做到毫秒级的响应,满足大多数低延迟相应的要求;
- 底层使用HDFS作为文件存储系统,让HBase的单表存储记录数可以达到极高的规模。
关于HBase的更多知识也可以查看ShowMeAI的后续教程了解。
相关学习链接:
- HBase 官方文档:https://hbase.apache.org/
- HBase 介绍:https://blog.csdn.net/u010270403/article/details/51648462
- HBase 常用命令:https://www.cnblogs.com/shadowalker/p/7350484.html
7)常用工具-大数据通用处理平台:Spark
Spark是第二代分布式处理框架,其核心思想与MapReduce类似,并在其基础上对于处理Pipeline进行了优化,包括引入DAG,依赖划分等机制。同时,通过针对对于数据缓存的使用,完成整体计算性能的大幅度提升,成为目前主流的分布式处理框架组件。
特性:
- 中间过程最大程度基于内存缓存,降低磁盘IO,实现高效计算;
- 高度复合的框架整合,集成Spark Core、SparkSQL、SparkGraphx、SparkML、SparkStreaming,让多环境的大数据开发可以单平台完成。
关于Spark的详细教程和综合应用也可以查看ShowMeAI的后续内容了解。
相关学习链接:
Spark官方文档:http://spark.apache.org/docs/latest/
Spark源代码环境搭建:https://blog.csdn.net/haohaixingyun/article/details/60968776
8)常用工具-流式计算:Storm
Storm是目前使用最多的实时流式数据处理框架,其核心思想主要是对每一个流入的数据都分配一个线程进行处理,Storm框架完成所有数据,线程的调度处理,让开发者可以专注开发基于流式数据的业务性功能开发。
特性:
- Storm针对单条记录进行接受处理并反馈结果,适用实时事务性处理场景
- 由于处理机制导致其并发度无法达到非常高的程度,集群一旦到达性能瓶颈,难以进行进一步的优化
相关学习链接:
- Storm官方文档:http://storm.apache.org/
- Storm 入门原理介绍:http://www.cnblogs.com/wuxiang/p/5629138.html
9)常用工具-流式计算:Flink
Apache Flink是一个用于分布式流和批处理数据处理的开源平台。Flink的核心是流数据流引擎,为数据流上的分布式计算提供数据分发、通信和容错。Flink在流引擎之上构建批处理,覆盖本机迭代支持,托管内存和程序优化。Flink核心思想与SparkStreaming类似,针对数据集的微批处理框架,在相对不高的延迟下(秒级)完成批量数据的近实时处理。
特性:
- 收集数据,按照时间进行微批数据的切分,并进行分布式处理,数据处理吞吐量大;
- 由于针对批次数据加工,相对延迟高于Storm,且无法完成实时事务性处理(例:银行即时转账等业务)。
相关学习链接:
- Flink 官方文档:https://flink.apache.org/
- Flink架构、原理与部署测试:https://blog.csdn.net/jdoouddm7i/article/details/62039337
- Flink 初体验:https://www.jianshu.com/p/cd39656c39d3
5.参考资料
- Apache Spark官方文档中文版:http://spark.apachecn.org/docs/cn/2.2.0/
- ApacheCN Github资料地址:https://github.com/apachecn
- 图解Spark:核心技术与案例实战,电子工业出版社,郭景瞻
- Python编程 从入门到实践,人民邮电出版社,Eric Matthes 袁国忠译
【大数据技术与处理】推荐阅读
- 图解大数据 | 大数据生态与应用导论
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
- 图解大数据 | Hadoop系统搭建与环境配置@实操案例
- 图解大数据 | 应用Map-Reduce进行大数据统计@实操案例
- 图解大数据 | Hive搭建与应用@实操案例
- 图解大数据 | Hive与HBase详解@海量数据库查询
- 图解大数据 | 大数据分析挖掘框架@Spark初步
- 图解大数据 | 基于RDD大数据处理分析@Spark操作
- 图解大数据 | 基于Dataframe / SQL大数据处理分析@Spark操作
- 图解大数据 | 使用Spark分析新冠肺炎疫情数据@综合案例
- 图解大数据 | 使用Spark分析挖掘零售交易数据@综合案例
- 图解大数据 | 使用Spark分析挖掘音乐专辑数据@综合案例
- 图解大数据 | Spark Streaming @流式数据处理
- 图解大数据 | 工作流与特征工程@Spark机器学习
- 图解大数据 | 建模与超参调优@Spark机器学习
- 图解大数据 | GraphFrames @基于图的数据分析挖掘
ShowMeAI 系列教程推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读



