
以某招聘网站的部分网页源码为例。
from bs4 import BeautifulSoup
html = """
<table class="tablelist" cellpadding="0" cellspacing="0">
<tbody>
<tr class="h">
<td class="l" width="374">职位名称</td>
<td>职位类别</td>
<td>人数</td>
<td>地点</td>
<td>发布时间</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td>
<td>技术类</td>
<td>4</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a id="test" class="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
</tbody>
</table>
"""
获取所有的tr标签
trs = soup.find_all('tr')
for tr in trs:
print(tr)
print('-'*100)
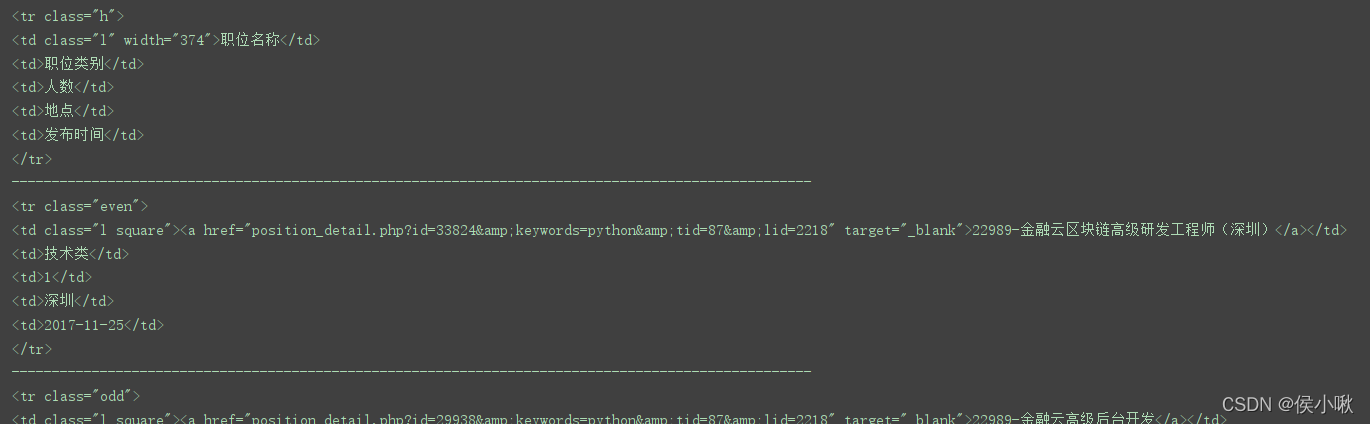
获取第二个tr标签
tr = soup.find_all('tr')[1] # 0 1
print(tr)

获取class属性为even的tr标签
因为python团队用了class关键字,所以这里就不能使用,规定需要加下划线
用class_表示class
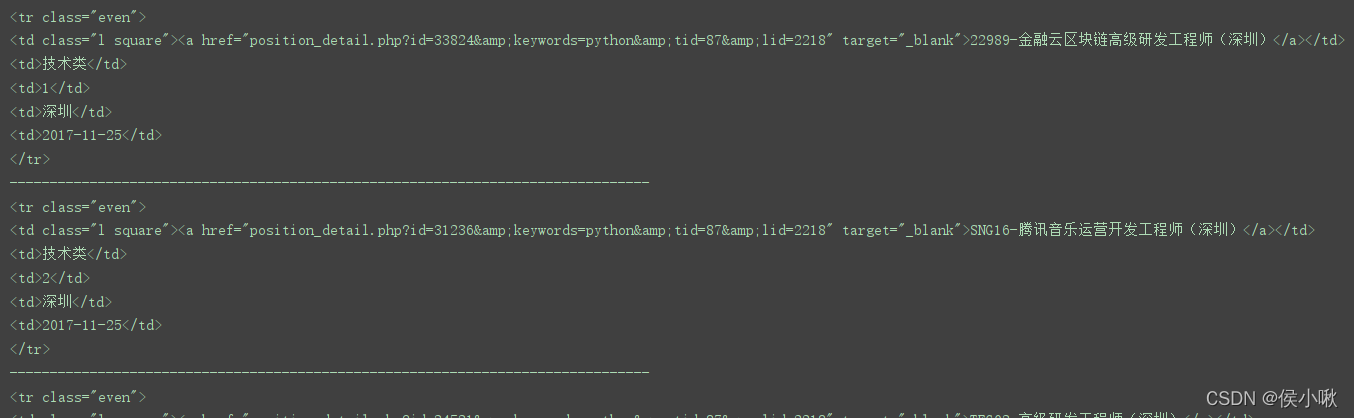
trs = soup.find_all('tr', class_="even") # python团队用了,就不能使用,需要加下划线
for tr in trs:
print(tr)
print('-'*80)
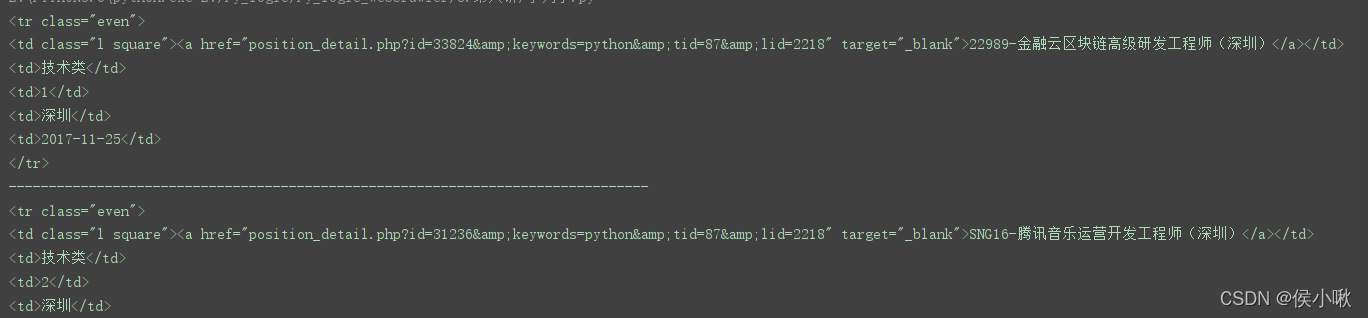
但是写成字典的话就没有问题了
trs = soup.find_all('tr', attrs={
'class': 'even'}) # python团队用了,就不能使用,需要加下划线
for tr in trs:
print(tr)
print('-'*80)
将所有的a标签中 id=test,class=test的提取出来
lst = soup.find_all('a', id='test', class_='test')
for a in lst:
print(a)

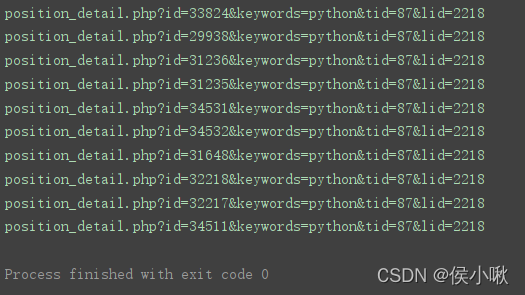
获取所有a标签的href属性
a_lst = soup.find_all('a')
for a in a_lst:
href = a.get('href')
print(href)
爬取职位名称
trs = soup.find_all('tr')[1:]
for tr in trs:
tds = tr.find_all('td')
job_name = tds[0].string
print(job_name)



