
目录
升级kubeadm、kubelet、kubectl(所有机器)
scheduler/controller-manager: dial tcp 127.0.0.1:10251: connect: connection refused
Kubernetes1.16.0手动升级到1.22.2

前言
本文基于centos7 搭建 kubernetes1.16.0 集群进行升级改造
Docker卸载升级最新版本
# --------[1. 停用当前docker]-------- # 查看当前docker版本 [root@node2 ~]# docker version Client: Version: 18.09.7 API version: 1.39 Go version: go1.10.8 Git commit: 2d0083d Built: Thu Jun 27 17:56:06 2019 OS/Arch: linux/amd64 # 查看当前docker状态 # 如果是运行状态则停掉--systemctl stop docker [root@node2 ~]# systemctl status docker Unit docker.service could not be found. # --------[2. 删除当前docker]-------- # 查看yum安装的docker文件包 [root@node2 ~]# yum list installed |grep docker docker-ce-cli.x86_64 1:18.09.7-3.el7 @docker-ce-stable # 查看docker相关的rpm源文件 [root@node2 ~]# rpm -qa |grep docker docker-ce-cli-18.09.7-3.el7.x86_64 # 删除所有安装的docker文件包 [root@node2 ~]# yum -y remove docker.x86_64 Loaded plugins: fastestmirror No Match for argument: docker.x86_64 No Packages marked for removal # 其他的docker相关的安装包同样删除操作,删完之后可以再查看下docker rpm源 [root@node2 ~]# rpm -qa |grep docker docker-ce-cli-18.09.7-3.el7.x86_64 [root@node2 ~]# yum -y remove docker-ce-cli.x86_64 Loaded plugins: fastestmirror Resolving Dependencies --> Running transaction check ---> Package docker-ce-cli.x86_64 1:18.09.7-3.el7 will be erased --> Finished Dependency Resolution Dependencies Resolved ============================================== Package Arch Version Repository Size ============================================== Removing: docker-ce-cli x86_64 1:18.09.7-3.el7 @docker-ce-stable 66 M Transaction Summary ============================================== Remove 1 Package Installed size: 66 M Downloading packages: Running transaction check Running transaction test Transaction test succeeded Running transaction Erasing : 1:docker-ce-cli-18.09.7- 1/1 Verifying : 1:docker-ce-cli-18.09.7- 1/1 Removed: docker-ce-cli.x86_64 1:18.09.7-3.el7 Complete! [root@node2 ~]# rpm -qa |grep docker [root@node2 ~]# [root@node2 ~]# docker version -bash: /usr/bin/docker: No such file or directory # --------[3. 安装最新版本或者指定版本docker]-------- [root@node2 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2 Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirror.lzu.edu.cn * extras: mirror.lzu.edu.cn * updates: mirrors.bupt.edu.cn Package yum-utils-1.1.31-54.el7_8.noarch already installed and latest version Package device-mapper-persistent-data-0.8.5-3.el7_9.2.x86_64 already installed and latest version Package 7:lvm2-2.02.187-6.el7_9.5.x86_64 already installed and latest version Nothing to do [root@node2 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo Loaded plugins: fastestmirror adding repo from: http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo grabbing file http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo to /etc/yum.repos.d/docker-ce.repo repo saved to /etc/yum.repos.d/docker-ce.repo [root@node2 ~]# yum makecache Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.huaweicloud.com * extras: mirrors.huaweicloud.com * updates: mirrors.huaweicloud.com base | 3.6 kB 00:00 docker-ce-stable | 3.5 kB 00:00 extras | 2.9 kB 00:00 kubernetes/signature | 844 B 00:00 kubernetes/signature | 1.4 kB 00:00 !!! updates | 2.9 kB 00:00 Metadata Cache Created # 可以查看所有仓库中所有docker版本,并选择特定的版本安装。 # yum list docker-ce --showduplicates | sort -r # yum install docker-ce 默认安装最新版本 [root@node2 ~]# yum install docker-ce -y
验证效果
Kubernetes还原
升级集群前, 保险起见, 先还原重置下
kubeadm reset
Kubernetes升级1.22.2
升级kubeadm、kubelet、kubectl(所有机器)
# 执行配置k8s的yum--阿里源 # 可以先产看是否有 cat /etc/yum.repos.d/kubernetes.repo cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 安装kubeadm、kubectl、kubelet yum install -y kubectl-1.22.2 kubeadm-1.22.2 kubelet-1.22.2 # 重启 docker,并启动 kubelet systemctl daemon-reload systemctl restart docker systemctl enable kubelet && systemctl start kubelet
升级k8smaster管理节点
#下载管理节点中用到的6个docker镜像,你可以使用docker images查看到 #这里需要大概两分钟等待,会卡在[preflight] You can also perform this action in beforehand using ''kubeadm config images pull kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.22.2 --apiserver-advertise-address 10.0.0.198 --pod-network-cidr=10.244.0.0/16 --token-ttl 0
上面安装完后,会提示你输入如下命令,复制粘贴过来,执行即可。
# 上面安装完成后,k8s会提示你输入如下命令,执行 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
记住node加入集群的命令---- 上面kubeadm init执行成功后会返回给你node节点加入集群的命令,等会要在node节点上执行,需要保存下来
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.0.0.198:6443 --token utoxqq.yl2ss3tut97a3ck1 \ --discovery-token-ca-cert-hash sha256:af31741fd42a53a30bc56afba7f37b42d30cdaaf8d8ac996efa928ea2649e6b4 [root@master-1 k8s-big-data-suite]# mkdir -p $HOME/.kube [root@master-1 k8s-big-data-suite]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config cp: overwrite ‘/root/.kube/config’? y [root@master-1 k8s-big-data-suite]# sudo chown $(id -u):$(id -g) $HOME/.kube/config [root@master-1 k8s-big-data-suite]#
重新安装网络插件
重新安装calico (master机器)
# 安装 calico 网络插件 # 安装 Tigera Calico operator和自定义资源。 curl https://docs.projectcalico.org/manifests/tigera-operator.yaml -O kubectl create -f tigera-operator.yaml # 通过创建必要的自定义资源来安装 Calico。有关此清单中可用配置选项的更多信息,请参阅安装参考。 # 注意:在创建此清单之前,请阅读其内容并确保其设置适合您的环境。例如,您可能需要更改默认 IP 池 CIDR 以匹配您的 Pod 网络 CIDR。 curl https://docs.projectcalico.org/manifests/custom-resources.yaml -O export POD_SUBNET=10.244.0.0/16 sed -i "s#192\.168\.0\.0/16#${POD_SUBNET}#" custom-resources.yaml kubectl create -f custom-resources.yaml
修改 Pods 使用的 IP 网段,默认使用 192.168.0.0/16 网段,但是和我们的服务器本来的网段不一样,会产生冲突,所以我们需要修改一下,注意,这个网段应该与kubeapi定义–service-cluster-ip-range的网段一样
参考链接: https://docs.projectcalico.org/getting-started/kubernetes/quickstart
注意:在创建此清单之前,请阅读其内容并确保其设置适合您的环境。例如,您可能需要更改默认 IP 池 CIDR 以匹配您的 Pod 网络 CIDR。
升级k8s node工作节点
加入集群 这里加入集群的命令每个人都不一样,可以登录master节点,使用kubeadm token create --print-join-command 来获取。获取后执行如下。
# 加入集群,如果这里不知道加入集群的命令,可以登录master节点,使用kubeadm token create --print-join-command 来获取 kubeadm join 10.0.0.198:6443 --token utoxqq.yl2ss3tut97a3ck1 \ --discovery-token-ca-cert-hash sha256:af31741fd42a53a30bc56afba7f37b42d30cdaaf8d8ac996efa928ea2649e6b4
加入成功后,可以在master节点上使用kubectl get nodes命令查看到加入的节点。
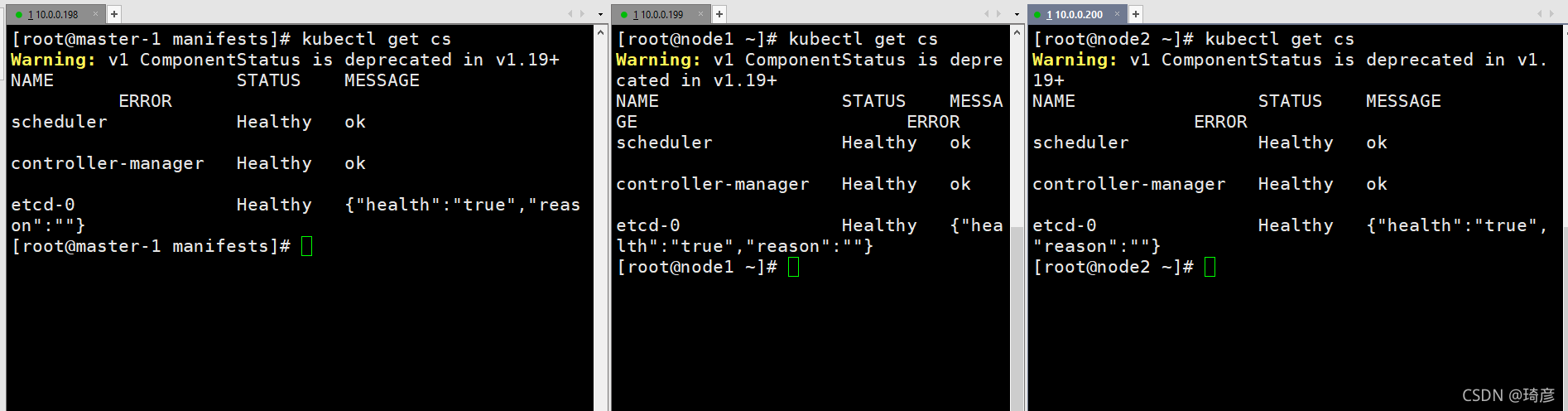
验证升级是否成功
kubectl get cs
执行
kubectl get cs命令来检测组件的运行状态
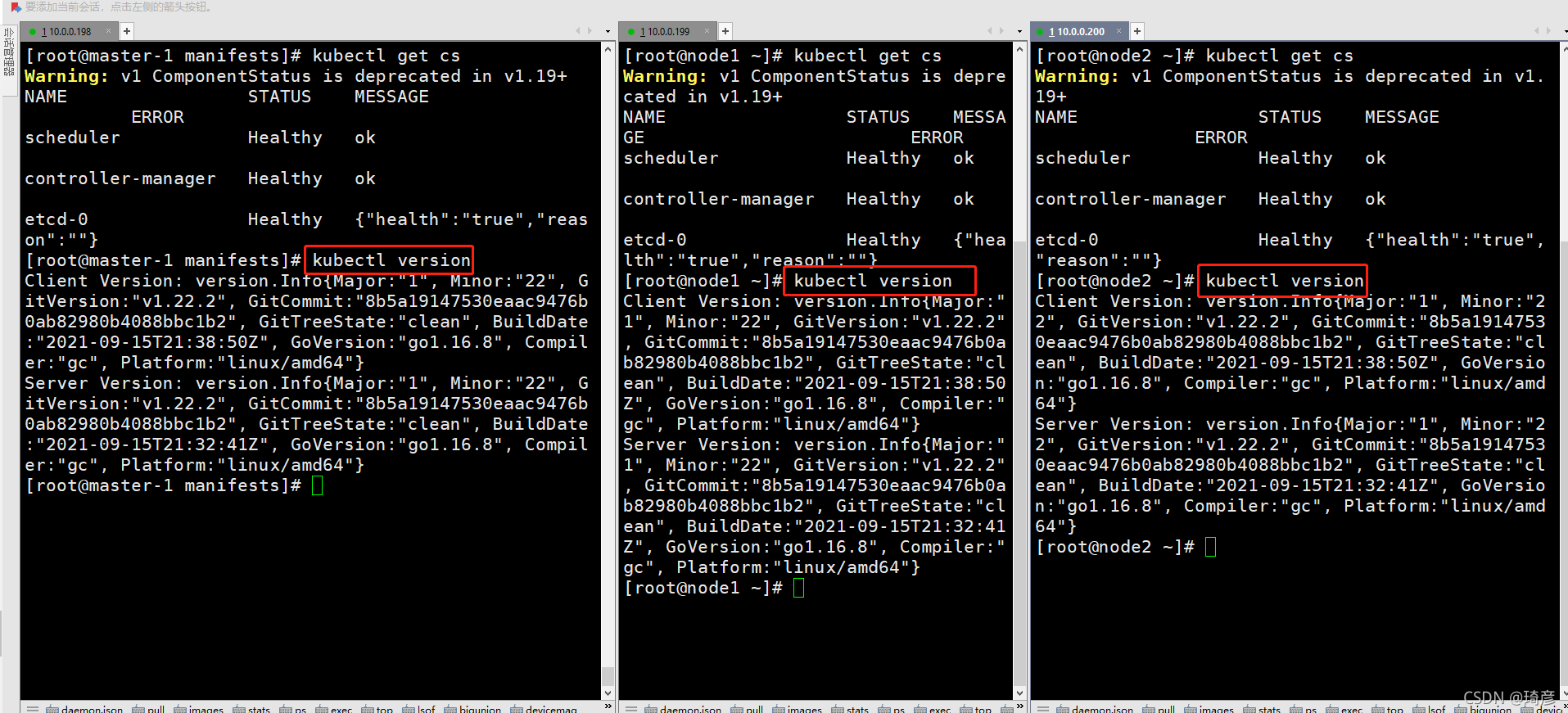
kubectl version
执行
kubectl version命令来查看版本
问题:
scheduler/controller-manager: dial tcp 127.0.0.1:10251: connect: connection refused
部署完master节点以后,执行kubectl get cs命令来检测组件的运行状态时,报如下错误:
root@fly-virtual-machine:/etc/netplan# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused etcd-0 Healthy {"health":"true","reason":""} controller-manager Healthy ok root@fly-virtual-machine:/etc/netplan# vim /etc/kubernetes/manifests/kube-scheduler.yaml root@fly-virtual-machine:/etc/netplan# systemctl restart kubelet.service
原因分析
出现这种情况,是/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0导致的,解决方式是注释掉对应的port即可,操作如下:

然后在master节点上重启kubelet,systemctl restart kubelet.service,然后重新查看就正常了
port=0是做什么用的? 关闭非安全端口
