
这是之前系列文章 “Logstash:Logstash 入门教程 (一)” 的续集。在之前的文章中,我们详细地介绍了 Logstash 是什么?在今天的文章中,我们将详细介绍如果使用 Logstash,并把 Apache Web log 导入到 Elasticsearch 中。在这篇文章中,我们将涉及到如下的过滤器:
安装
Elasticsearch
如果你还没有安装好自己的 Elasticsearch,请参阅我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装好自己的 Elasticsearch。
Kibana
如果你还没有安装好自己的 Kibana,请参阅我之前的文章 “如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana” 安装好自己的 Kibana。
Logstash
如果你还没有安装好自己的 Logstash,请参阅我之前的文章 “如何安装Elastic栈中的Logstash” 来安装好自己的 Logstash。
如何运行 Logstash
在 Mac, Unix 及 Linux下,我们可以使用如下的方式来进行运行:
bin/logstash [options]
在 Windows 环境下,我们使用如下的方式来运行:
bin/logstash.bat [options]
在通常情况下,我们需要跟上一些选项才可以启动 Logstash,否则它会退出。除非有一种情况,在我们启动 monitoring 后,可以不添加选项来启动 Logstash。关于如何启动集中管理,请参阅我之前的文章 “Logstash: 启动监控及集中管理”。
如何配置 Logstash pipeline
Logstash 管道有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。 输入插件使用来自源的数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。

要测试 Logstash 安装,请运行最基本的 Logstash 管道。 例如:
cd logstash-7.6.2 bin/logstash -e 'input { stdin { } } output { stdout {} }'
等 Logstash 完成启动后,我们在 stdin 里输入一下文字,我们可以看到如下的输出:
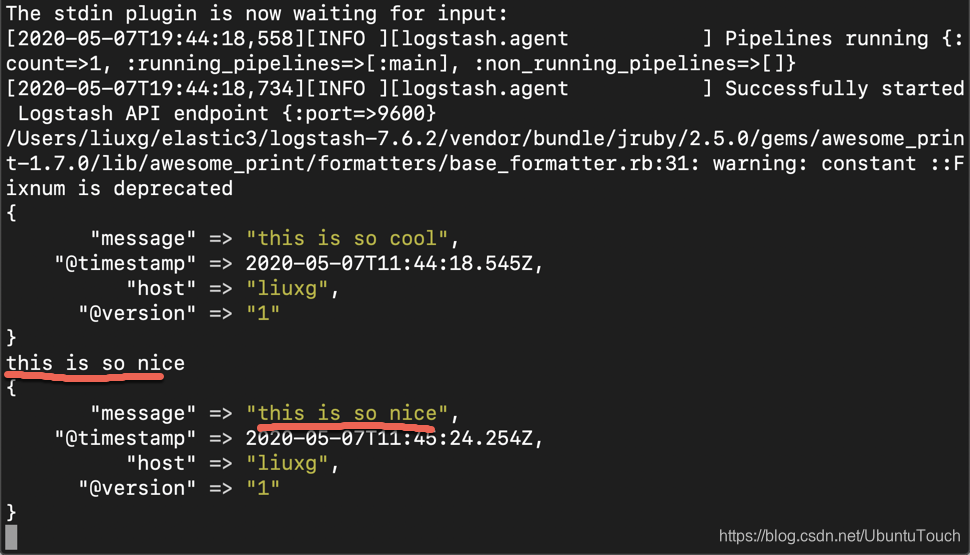
当我们打入一行字符然后回车,那么我们马上可以在 stdout 上看到输出的信息。如果我们能看到这个输出,说明我们的 Logstash 的安装是成功的。
另外一种运行 Logstash 的方式,也是一种最为常见的运行方式。我们首先需要创建一个配置文件,比如:
heartbeat.conf
input { heartbeat { interval => 10 type => "heartbeat" } } output { stdout { codec => rubydebug } }
然后,我们通过如下的方式来运行 Logstash:
bin/logstash -f heartbeat.conf
那么我们可以在 console 中看到如下的输出:
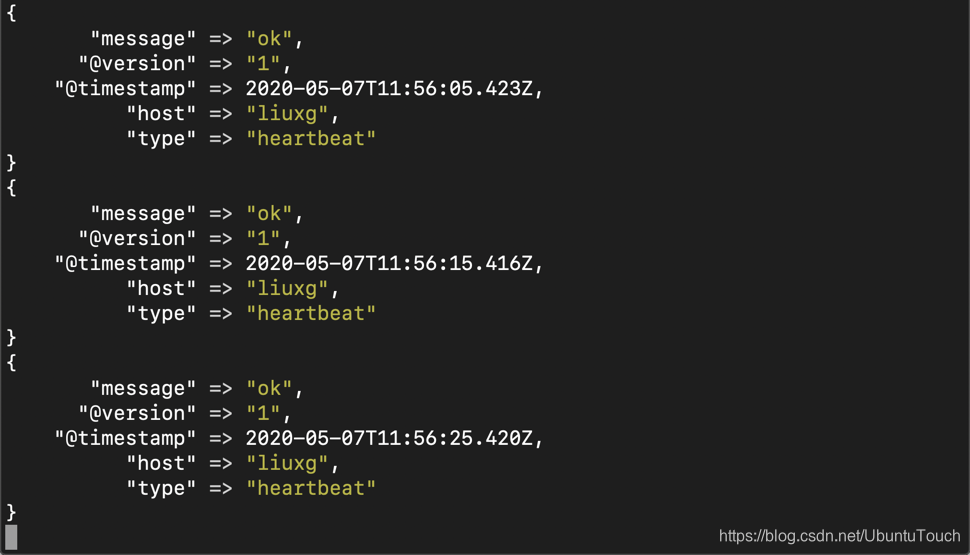
动手实践
在这一节中,我们将使用一个例子来一步一步地详细介绍如何使用 Logstash 来实现我们的数据处理。
1)首先启动我们的 Elasticsearch 及 Kibana。请参照之前的步骤运行 Elasticsearch 及 Kibana。
2)我们进入到 Logstash 安装目录,并修改 config/logstash.yml 文件。我们把 config.reload.automatic 设置为 true。

这样设置的好处是,每当我修改完我的配置文件后,我不需要每次都退出我的 Logstash,然后再重新运行。Logstash 会自动侦测到最新的配置文件的变化。
3)创建一个叫做 weblog.conf 的配置文件,并输入一下的内容:
weblog.conf
input { tcp { port => 9900 } } output { stdout { } }
4)运行我们的 Logstash
bin/logstash -f weblog.conf
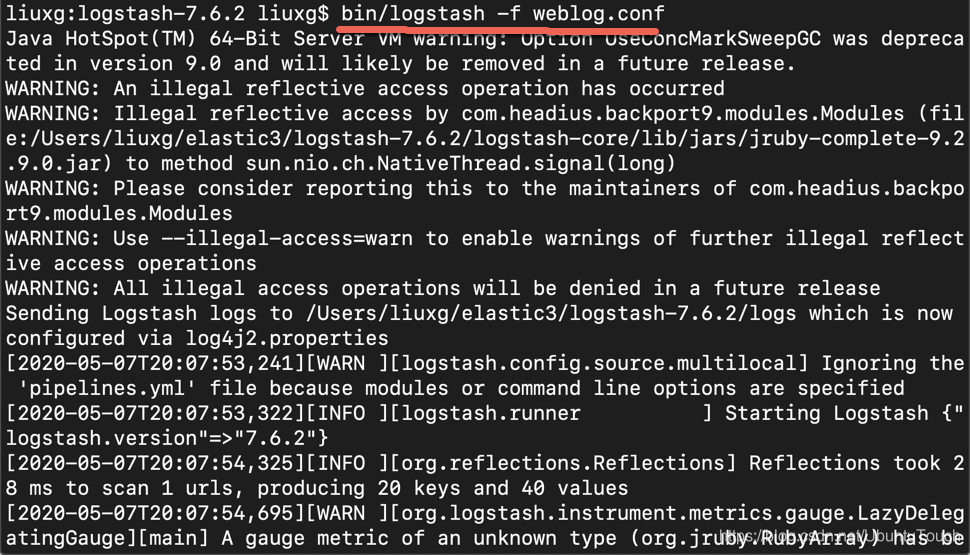
这样我们的 Logstash 就已经启动了。
接下来,我们使用 nc 应用把数据发送到 TCP 端口号 9900,并查看 console 的输出。我们在另外一个 console 中打入如下的命令:
echo 'hello logstash' | nc localhost 9900
我们在 Logstash 运行的 console 里可以看到输出:
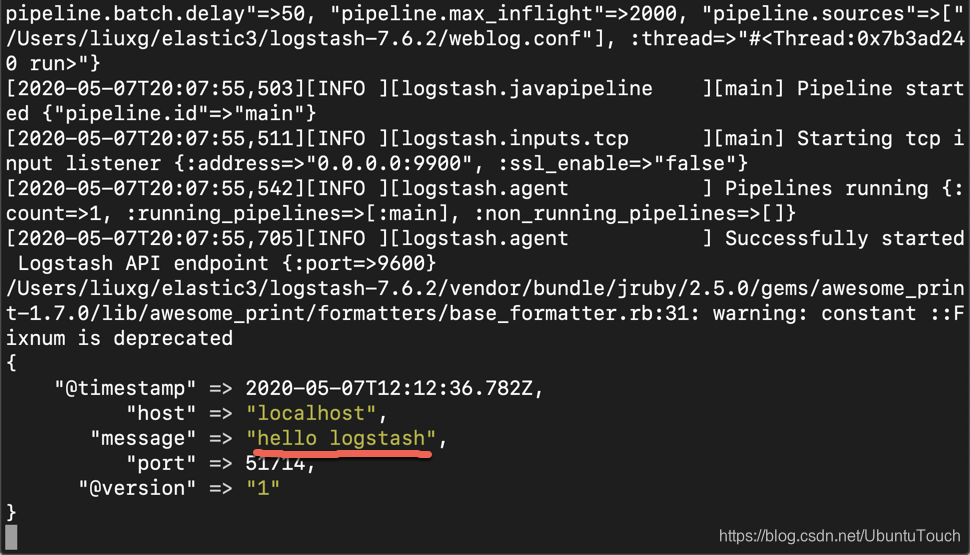
上面说明我们的 TCP input 运行是正常的。
5)下载 Weblog 文件并发送给 Logstash
我们可以在地址 https://ela.st/weblog-sample 下载一个叫做 weblog-sample.log 的文件。这个文件有 64.5M 的大下。我们把这个文件保存于 Logstash 的安装目录中。它里面的其中的一个 log 的内容如下:
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
或:
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
我使用如下的命令来读取第一行,并输入到 TCP 9900 端口:
head -n 1 weblog-sample.log | nc localhost 9900
那么在 Logstash 运行的 console 中,我们可以看到如下的输出:
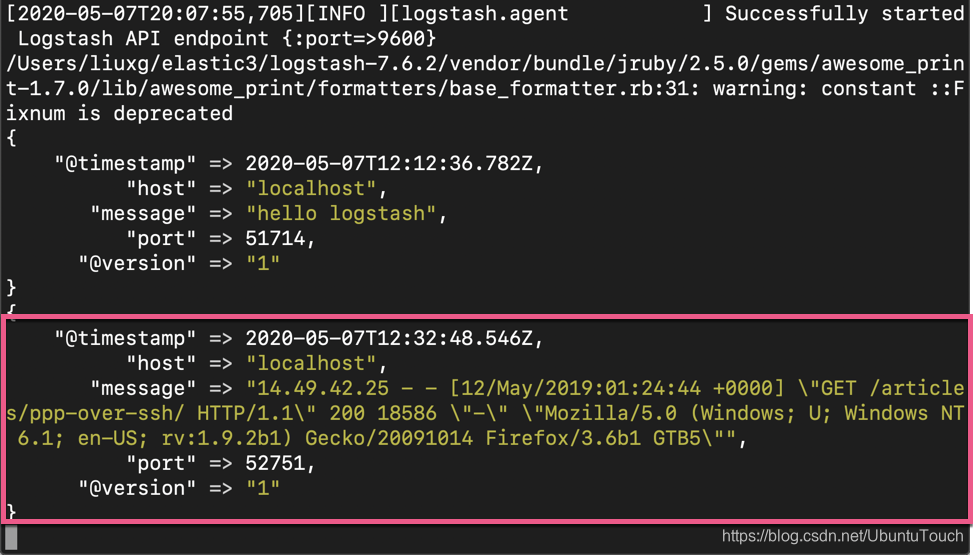
这显示是我们第一行的那条 Weblog 信息。在这里,我们没有对数据进行任何的处理。它只是把第一行日志读出来,并把它都赋予给 message 这个字段。
运用过滤器来对数据进行处理
接下来,我们分别使用一些过滤器来对数据进行分别处理。
Grok
针对 Grok,我还有有一个专门的文章 “Logstash:Grok filter 入门” 来描述。你可以发现所有的关于 Logstash 的 patterns: https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns。在这里,我们针对 weblog.conf 进行如下的修改(你可以使用你喜欢的编辑器):
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } output { stdout { } }
还记得之前我们的设置 config.reload.automatic 为 true 吗?当我们保存 weblog.conf 文件后,我们可以在 Logstash 的输出 console 里看到:
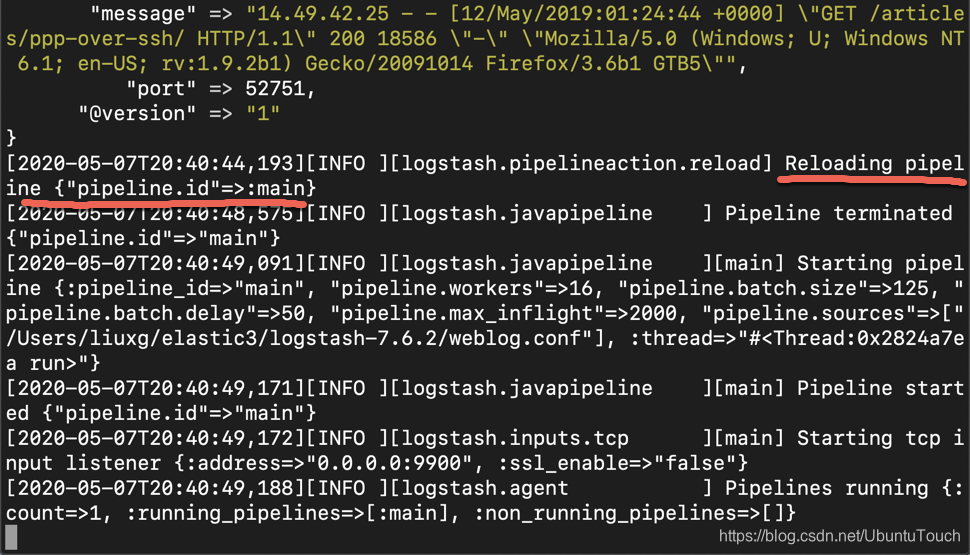
也就是说,我们的 pipleline 被自动地装载进来了。我们安装上面同样的方法取第一条的数据来输入:
head -n 1 weblog-sample.log | nc localhost 9900
这个时候,我们再在 Logstash 运行的 console 里,我们可以看到:
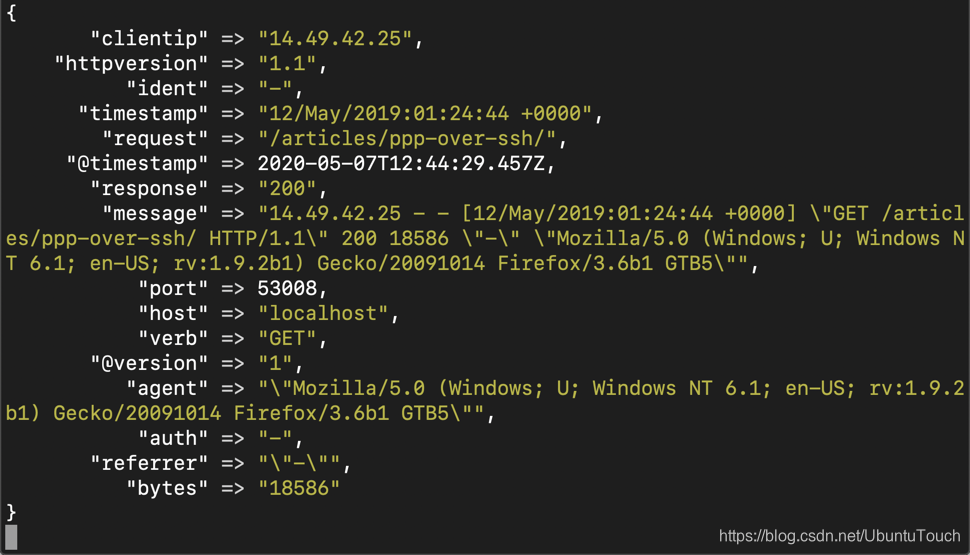
也就是说,我们通过 Grok 这个 filter,它通过正则表达式进行匹配,并把我们的输入的非结构化的数据变为一个结构化的数据。从上面,我们可以看到各种被提取的字段,比如 clientip, port, host 等等。
Geoip
尽管上面的数据从非结构化变为结构化数据,这是非常好的,但是还是有美中不足的地方。比如 clientip,我们知道了这个请求的 IP 地址,但是我们还是不知道这个 IP 是从哪个地方来的,具体是哪个国家,哪个地理位置。在这个时候,我们需要使用 geoip 过滤器来对数据进行丰富。我们在 filter 的这个部分加入 geoip。当我们保存好 weblog.conf 文件后,我们会发现 Logstash 会自动装载我们最新的配置文件(如上步所示一样):
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } geoip { source => "clientip" } } output { stdout { } }
同样地,我们使用如下的命令来发送日志里的第一条数据:
head -n 1 weblog-sample.log | nc localhost 9900
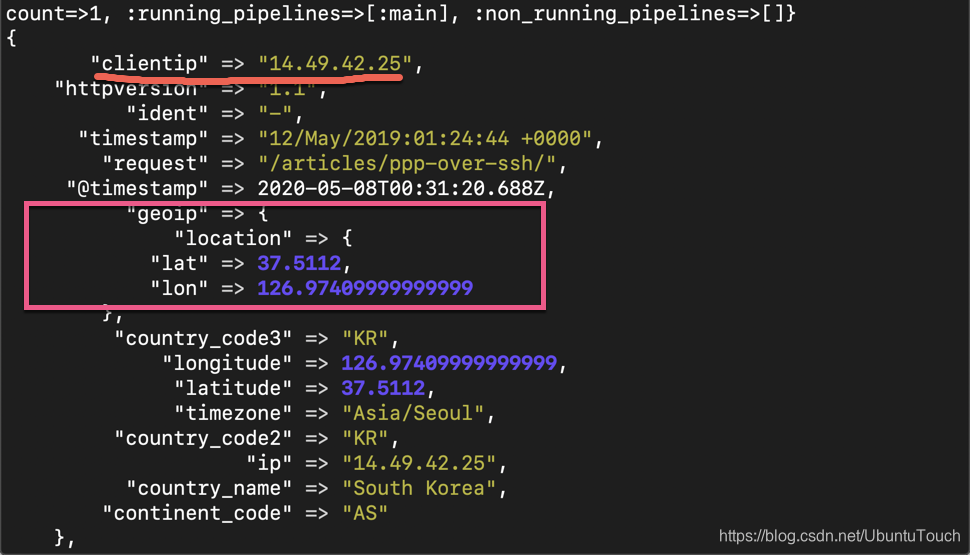
这个时候,我们可以看到除了在上面的 clientip 信息之外, 我们的数据多了一个新的叫做 geoip 的字段。它里面含有 location 位置信息。这就为我们在地图上进行显示这些数据提供了方便。我们可以利用 Elastic 所提供的地图清楚地查看到请求是来自哪里。
Useragent
上面的数据比以前更加丰富。我们还注意到 agent 这个字段。它非常长,我们没法查看出来是来自什么样的浏览器,什么语言等等信息。我们可以使用 useragent 这个过滤器来进一步丰富数据。我们在 weblog.conf 中添加这个过滤器:
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } geoip { source => "clientip" } useragent { source => "agent" target => "useragent" } } output { stdout { } }
等更新完这个配置文件后,我们再次在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900
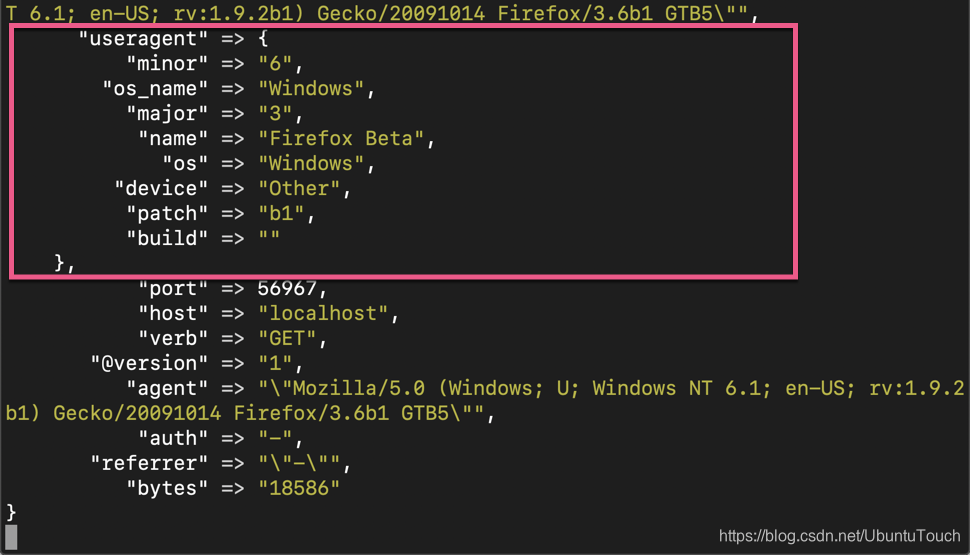
我们可以在上面看到一个新增加的字段 useragent。上面它表明了 useragent 的版本信息,浏览器的名称以及操作系统。这对于我们以后的数据分析提供更进一步的帮助。
Mutate - convert
从上面的输出中,我们了可以看出来 bytes 是一个字符串的类型。这个和我们实际的应用可能会有所不同。这应该是一个整型数。我们可以使用 mutate: convert 过滤器来对它进行转换。我们重新编辑 weblog.conf 文件。我们把它放于 grok 过滤器之后:
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } mutate { convert => { "bytes" => "integer" } } geoip { source => "clientip" } useragent { source => "agent" target => "useragent" } } output { stdout { } }
等更新完这个配置文件后,我们再次在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900
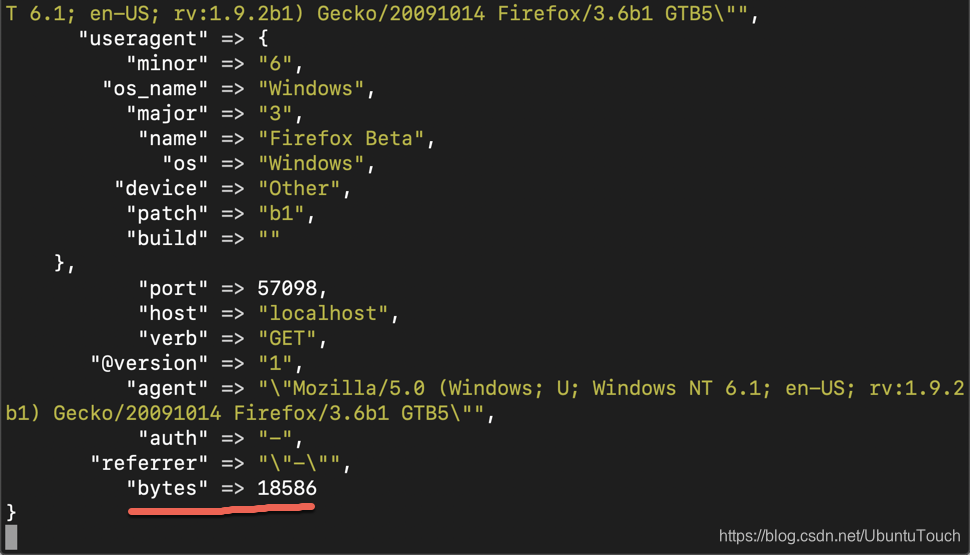
从上面的输出中,我们可以看到 bytes 这个字段已经变为正式值了,而不是之前的字符串了。
Date
Logstash 将事件时间存储在 @timestamp 字段中。 但是实际的日志创建时间在 timestamp 字段中(没有@)。 该字段的格式不是 ISO8601,因此存储为文本。 我们可以使用 date 过滤器将此字段转换为日期类型。我们编辑 weblog.conf,并加入 date 过滤器:
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } mutate { convert => { "bytes" => "integer" } } geoip { source => "clientip" } useragent { source => "agent" target => "useragent" } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } } output { stdout { } }
等更新完这个配置文件后,我们再次在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900
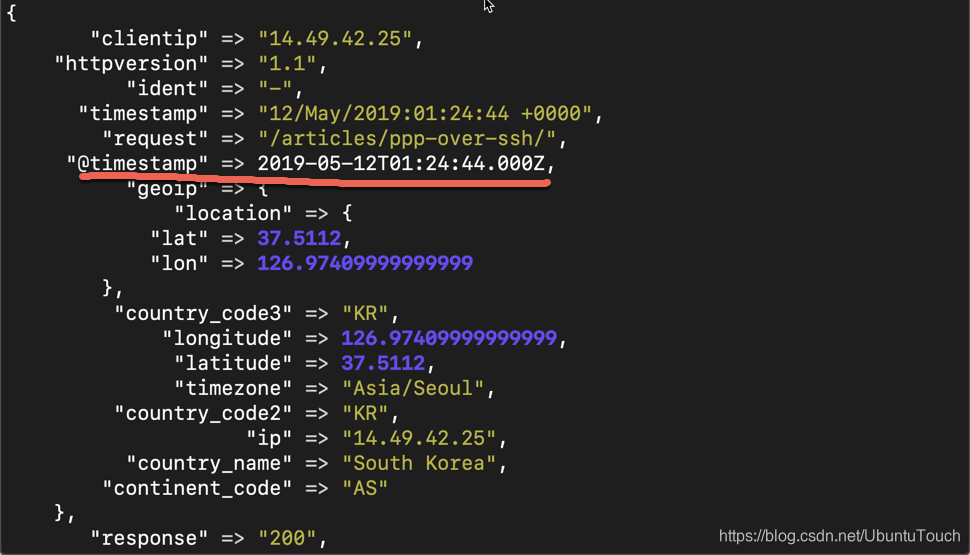
从上面,我们看出来新添加了一个叫做 @timestamp 的字段。
设置输出 - Elasticsearch
所有的到目前为止,所有的输出都是 stdout,也就是输出到 Logstash 运行的 console。我们想把处理后的数据输出到 Elasticsearch。我们在 output 的部分添加如下的 Elasticsearch 输出:
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } mutate { convert => { "bytes" => "integer" } } geoip { source => "clientip" } useragent { source => "agent" target => "useragent" } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } } output { stdout { } elasticsearch { hosts => ["localhost:9200"] user => "elastic" password => "changeme" } }
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。依赖于我们是否已经为 Elasticsearch 提供安全设置,我们需要在上面配置好访问的用户名及密码。
等更新完这个配置文件后,我们再次在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900
这一次,我们打开 Kibana:
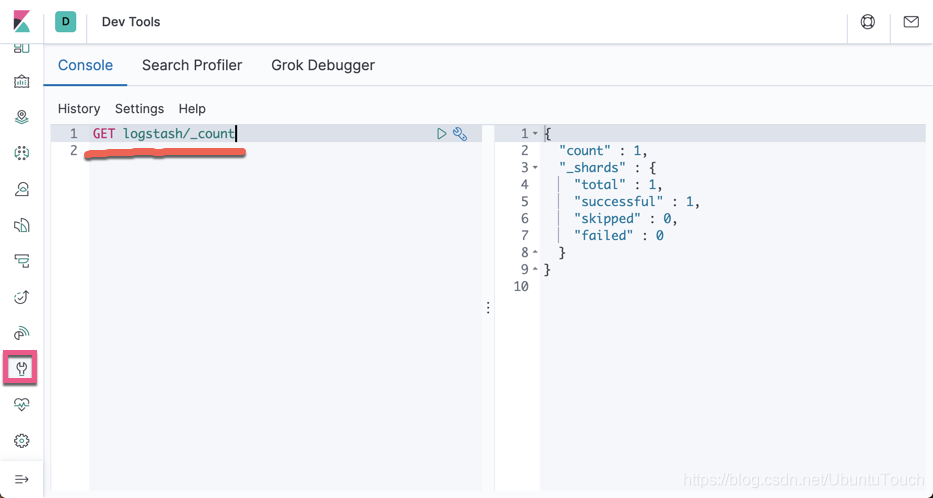
我们在 Dev Tools 里输入如下的命令:
GET logstash/_count
从上面,我们可以看到有一条 Logstash 的数据。我们可以再接着打入如下的命令:
GET logstash/_search
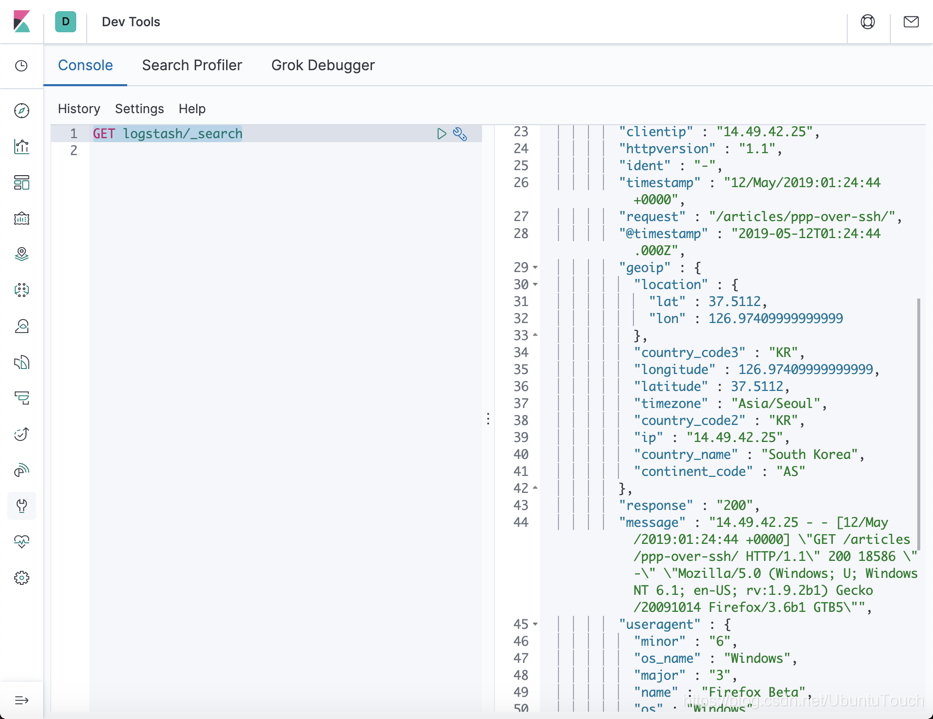
从上面我们可以看到这条 Logstash 导入的数据。它和我们之前在 Longstash console 里看到的是一摸一样的。
启用 keystore 来保护自己的密码等
在上面所有的配置中,我们在配置文件中把自己的用户名及密码都写在文本中间。这个是非常不好的,这是因为任何可以接触到这个配置文件的人都可以看到你这些敏感信息。为此,logstash-keystore 提供了一种安全机制。它允许我们把这些信息保存于一个 keystore 里,这样别人都看不到真实的用户名及密码等信息。如果你还不知道如何为 Elasticsearch设置安全信息的话,请参阅我之前的文章 “Elasticsearch:设置 Elastic 账户安全”。
我们在 Logstash 的 console 里打入如下的命令:
bin/logstash-keystore create
$ bin/logstash-keystore create Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. 2020-05-08T10:38:35.483+08:00 [main] WARN FilenoUtil : Native subprocess control requires open access to sun.nio.ch Pass '--add-opens java.base/sun.nio.ch=org.jruby.dist' or '=org.jruby.core' to enable. WARNING: The keystore password is not set. Please set the environment variable `LOGSTASH_KEYSTORE_PASS`. Failure to do so will result in reduced security. Continue without password protection on the keystore? [y/N] y Created Logstash keystore at /Users/liuxg/elastic3/logstash-7.6.2/config/logstash.keystore
我们接着打入如下的命令:
bin/logstash-keystore add ES_HOST
我们把配置文件中的 Elasticsearch 的地址 localhost:9200 拷贝并粘贴过来:
$ bin/logstash-keystore add ES_HOST Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. 2020-05-08T10:39:41.884+08:00 [main] WARN FilenoUtil : Native subprocess control requires open access to sun.nio.ch Pass '--add-opens java.base/sun.nio.ch=org.jruby.dist' or '=org.jruby.core' to enable. Enter value for ES_HOST: Added 'es_host' to the Logstash keystore.
我们再接着打入如下的命令:
bin/logstash-keystore add LS_USER
$ bin/logstash-keystore add LS_USER Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. 2020-05-08T10:41:41.603+08:00 [main] WARN FilenoUtil : Native subprocess control requires open access to sun.nio.ch Pass '--add-opens java.base/sun.nio.ch=org.jruby.dist' or '=org.jruby.core' to enable. Enter value for LS_USER: Added 'ls_user' to the Logstash keystore.
我们在上面输入我们的 Logstash 的用户名。这个用户名可以是那个超级用户 elastic,也可以是我们自己创建的一个专为数据采集的用户。
最后,我们也可以打入如下的命令:
bin/logstash-keystore add LS_PWD
我们把上面用户名的密码进行输入:
$ bin/logstash-keystore add LS_PWD Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. 2020-05-08T10:48:29.166+08:00 [main] WARN FilenoUtil : Native subprocess control requires open access to sun.nio.ch Pass '--add-opens java.base/sun.nio.ch=org.jruby.dist' or '=org.jruby.core' to enable. Enter value for LS_PWD: Added 'ls_pwd' to the Logstash keystore.
在这里我必须指出的是:上面我使用的 ES_HOST, LS_USER 及 LS_PWD 都是你自己任意可以选取的名字。只要它们和我们下边所使用的配置里的名字是配合的即可。
你可以使用如下的命令来查看你已经创建的 key:
./bin/logstash-keystore list
在上面,我们已经创建了一下键值,那么我们该如何使用它们呢?我们重新打开 weblog.conf 文件:
weblog.conf
input { tcp { port => 9900 } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } mutate { convert => { "bytes" => "integer" } } geoip { source => "clientip" } useragent { source => "agent" target => "useragent" } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } } output { stdout { } elasticsearch { hosts => ["${ES_HOST}"] user => "${LS_USER}" password => "${LS_PWD}" } }
在上面的 elasticsearch 输出部分,我们分别使用了 ES_HOST, LS_USER 及 LS_PWD 来分别代替了之前使用的字符串。这样做的好处是,我们再也不用硬编码我们的这些字符串了。我们把这个文件给任何人看,他们都不会发现我们的这些敏感信息了。
经过这个修改后,我们重新运行 Logstash:
bin/logstash -f weblog.conf
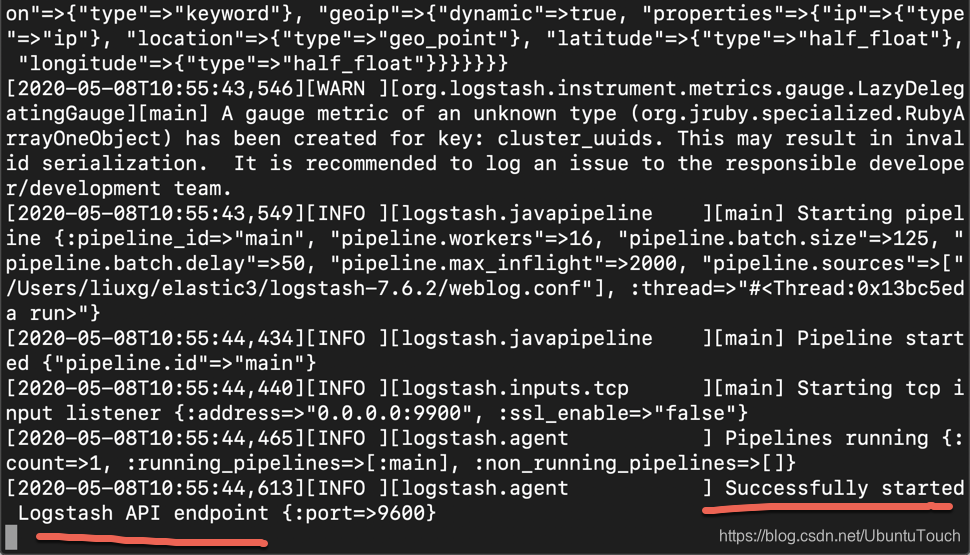
我们看到 Logstash 已经被成功启动了。我们使用如下的命令再次发送第一条日志信息:
head -n 1 weblog-sample.log | nc localhost 9900
我们再次查看 Kibana:
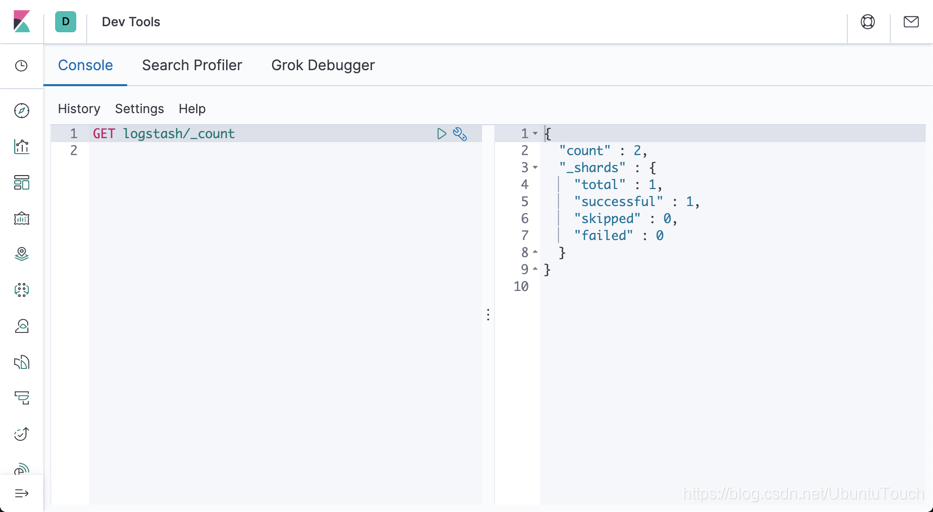
显然,这次比上一次多了一条数据。说明我们的配置是成功的!
把整个文件都导入进 Elasticsearch
到目前为止,我们只是测试了我们的 Logstash 的配置文件部分。可能很多的人觉得并不完整。如果你想把整个的 log 文件都导入进 Elasticsearch 中,那么我们可以配合 Filebeat 来进行使用。关于这个部分,请阅读我的另外一篇文章 “Logstash:把 Apache 日志导入到 Elasticsearch”。
由于一些原因,我们可以把 Filebeat 的配置文件设置为:
filebeat_logstash.yml
filebeat.inputs: - type: log enabled: true paths: - /path-to-log-file/weblog-sample.log output.logstash: hosts: ["localhost:9900"]
我们要记得根据自己 weblog-sample.log 的位置修改上面的 paths。同时,由于一些原因,我们也同时也要做上面的 Logstash 的配置文件 weblog.conf 做很小的修正。把 useragent 里的 source 修改为 user-agent 而不是之前的 agent。
weblog.conf
input { beats { port => "9900" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } mutate { convert => { "bytes" => "integer" } } geoip { source => "clientip" } useragent { source => "user_agent" target => "useragent" } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] } } output { stdout { codec => dots {} } elasticsearch { hosts=>["localhost:9200"] user=>"elastic" password=>"123456" index => "apache_elastic_example" template => "/Users/liuxg/data/beats/apache_template.json" template_name => "apache_elastic_example" template_overwrite => true } }
你可以在地址:https://github.com/liu-xiao-guo/beats-getstarted 下载所以的代码。记得换掉上面的路径即可。在使用时,你先要启动 Logstash,然后再启动 Filebeat。
bin/logstash -f weblog.conf
然后,再运行 Filebeat:
bin/filebeat -e -c filebeat_logstash.yml
在 Kibana 中,我们可以通过如下的命令来查看索引:
GET _cat/indices
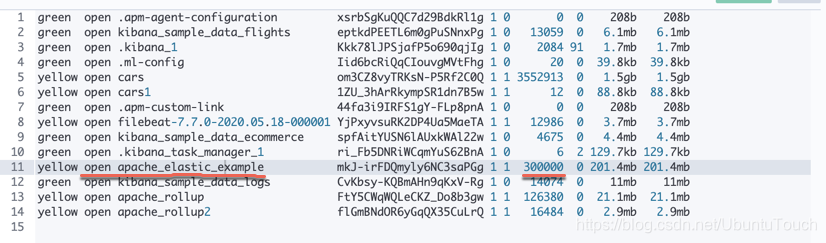
从上面,我们可以看出来有30万个数据被导入到 Elasticsearch 中。
更多阅读
你可以发现更多的关于 Logstash 的文章。相关的文章:



