作者 | 寒斜 & 江昱
当 Serverless 与低代码这两个不同的技术共同相交于同一个业务时会有怎样的价值展现?本文以 “盲盒抽奖” 这个 Serverless Devs 做过的创意营销活动为例,为大家讲述 Serverless 和低代码是如何搭配来满足一个业务诉求的。
前言
线上 H5 创意动画结合线下实体奖励是互联网营销活动的一种常见手段。为了抓住关键时间节点,活动从策划到落地的周期一般都比较短,短时间内落地线上服务对于做技术开发的同学有着不小的挑战。
尤其是当有更多需求,比如增加后台管理以及关键前端访问数据埋点等需求时,挑战难度往往会加倍。对于开发而言除了完成业务核心诉求,往往还需要关注非业务诉求以外的其他状况,比如系统访问安全,高并发流量应对,系统运行指标可观测等。
在以前这类需求往往需要跟多的角色参与,如产品,前端,后端,设计,测试,运营,运维等,使得投入产出比变得比较低,活动持续性比较差。今天使用 Serverless + 低代码的技术我们可以大幅缩减做此类活动的成本,让它变成持续性的活动,从而大大提高运营效果。
实际上 Serverless Devs 此次的盲盒抽奖活动仅仅投了 3.5 个人,便完成了活动策划,产品设计, 前后端实现,系统部署运维等工作。并且借助于 Serverless 的服务能力,轻松应对了系统访问安全,高并发流量,系统可观测等这些非业务挑战。功能性的补齐 + 效率提升,让本次运营取得了非常好的收益,活动服务的模板化沉淀又为后续同类活动奠定好了良好的基础。
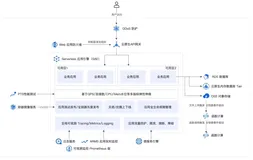
“盲盒抽奖” 活动的整体流程如下:
- 需求设计(含业务逻辑和交互逻辑)
- 设计稿
- 低代码实现前端
- 编码实现 Serverless 服务
- 联调测试
- 部署上线
- 活动中问题修复
- 活动后复盘
应用效果预览:

“1 分钟 Serverless 极速部署盲盒” 抽奖活动目前已经结束,但是感兴趣的同学仍可以体验一下:
https://developer.aliyun.com/adc/series/serverless2
架构预览:

本次的部署架构没有使用阿里云API网关,而是直接用函数计算Custom Runtime 作为托管形态,这样做是因为本次需求的特殊性,我们是“自己部署自己抽”,实际上意味着端侧访问是非中心化的,端侧访问的服务做的也比较薄,只是数据处理接口调用和提供静态渲染服务,后经过一个中心化的逻辑后台处理中奖概率,管理奖品查询数据库等。

如果您是自己做中心化的的活动后台的话建议参考下面的架构模式,采用 API网关作为流量入口。方便做更多的安全限制以及更灵活的扩展
实现解析
前端交互低代码实现
本次前端实现使用低代码工作 hype4,hype4 的具体使用这里不做详细介绍,有兴趣的同学可以自行搜索。
设计稿除了之后将需要的图切出来,然后跟处理 Flash 一样将动画效果实现,最后就是添加 js 代码实现接口访问,场景切换等能力。整个流程会比全编码要快很多,尤其是动效实现上比纯手写效率高 2-3 倍。
数据层 Serverless 服务
如架构所示,这里的数据层实际上就是我们理解的 SSF ,这层仅做数据转发和静态的渲染。代码实现比较简单,采用 express 框架,然后以函数计算 Custom runtime 形式部署。
目的是为了这个服务既可以托管静态内容也可以做动态的数据转发。值得注意的是,用户的信息获取也是在这层实现的。

这里我们获取的是阿里云用户的 accountId,方便对齐中奖信息发放奖品。对于普通开发者而言这个参数没有太大意义。
我们会提前将摇奖后台部署完毕,接下来就是,每个用户自己部署完这层服务后,访问自己部署好的服务,然后向摇奖后台传递 uid 等基本信息,发起摇奖。最终返回中奖结果透传给前端展示。作为管理员则可以通过后台操作设置奖品和概率等。
后台抽奖逻辑实现
后端服务采用 Python Web 框架:Django 进行实现,主要方法有:
1.获取用户的 uid 信息,并对uid信息进行校验,以确保:
- uid 信息的准确性
- 该客户端服务是通过 Serverless Devs 开发者工具进行部署;
2.当日奖品池的构建;
3.用户中奖信息的初步确定;
4.用户中奖信息的复核;
5.返回最终的结果给客户端;
基本流程
1.用户在本地,将盲盒抽奖的客户端服务,通过 Serverless Devs 开发者工具进行部署,部署到用户自己的账号下;
在部署期间,需要给用户下发一个临时域名 (这个临时域名需要用到用户的 uid),Serverless Devs 在进行临时域名下发的过程中,会生成部分的客户端token,并记录到 Serverless Devs 后端服务中;这个token实际上就是鉴定用户身份的重要标记;
(如果用户在 Yaml 中声明了不使用系统自动下发的域名信息,可能就没办法顺利参加本次活动)。
2.用户部署完成之后,会返回一个Serverless Devs下发的临时域名,供用户学习和测试使用。
3.接下来用户通过浏览器,打开该临时域名,便可以看到抽奖的相关页面,用户可以点击进行抽奖操作。
4.用户点击抽奖操作之后,会发起请求,请求用户账号下的 Serverless 服务,该服务会根据用户的 uid 信息进行相关的处理,并发起真正的抽奖请求到本次活动的后端 Serverless 服务上;
5.本次活动的后端 Serverless 服务接收到用户的抽奖请求时,会:
- 获取用户账号下的 Serverless 服务发起抽奖请求时所传递 uid 信息;
- 使用获得到的 uid 信息在临时域名下发系统中进行数据匹配,确定用户本次使用了临时域名下发系统,并下发了对应的域名;
- 实现抽奖操作;
抽奖核心实现
在抽奖操作的过程中,也是对当前系统进行了初步的评估,设定了一个简单的,易于实现的,可以针对小规模抽奖活动的抽奖功能:

关于这一部分,Django项目的实现方法:
@csrf_exempt
def prize(request):
uid = request.POST.get("uid", None)
if not uid:
return JsonResponse({"Error": "Uid is required."})
temp_url = "<获取uid的合法性和有效性,重要判断依据>?uid=" + str(uid)
if json.loads(urllib.request.urlopen(temp_url).read().decode("utf-8"))["Response"] == '0':
return JsonResponse({"Error": "Uid is required."})
token = randomStr(10)
# 获取当日奖品
prizes = {}
for eve_prize in PrizeModel.objects.filter(date=time.strftime("%Y-%m-%d", time.localtime())):
prizes[eve_prize.name] = {
"count": eve_prize.count,
"rate": eve_prize.rate
}
# 构建抽奖池
prize_list = []
for evePrize, eveInfo in prizes.items():
temp_prize_list = [evePrize, ] * int((100 * eveInfo['rate']))
prize_list = prize_list + temp_prize_list
none_list = [None, ] * (100 - len(prize_list))
prize_list = prize_list + none_list
pre_prize = random.choice(prize_list)
# 数据入库
try:
UserModel.objects.create(uid=uid,
token=token,
pre_prize=pre_prize,
result=False)
except:
try:
if not UserModel.objects.get(uid=uid).result:
return JsonResponse({"Result": "0"})
except:
pass
return JsonResponse({"Error": "Everyone can only participate once."})
if not pre_prize:
return JsonResponse({"Result": "0"})
user_id = UserModel.objects.get(uid=uid, token=token).id
users_count = UserModel.objects.filter(pre_prize=pre_prize, id__lt=user_id, date=time.strftime("%Y-%m-%d", time.localtime())).count()
# 是否获奖的最终判断
if users_count >= prizes.get(pre_prize, {}).get("count", 0):
return JsonResponse({"Result": "0"})
UserModel.objects.filter(uid=uid, token=token).update(result=True)
return JsonResponse({"Result": {
"token": token,
"prize": pre_prize
}})
系统安全设定
当用户中奖之后,系统会生成一个token,该token与uid的组合,是用来判断用户是否中奖的重要依据,这里可能涉及到一个问题:什么有了uid,还要增加一个token来进行组合判断呢?其实原因很简单的,提交中奖信息和查询中奖信息,如果是通过uid来直接进行处理的,那么很有可能会有用户通过遍历等手段,非法获取到其他用户提交过的信息,而这一部分信息很有可能涉及到用户提交的收货地址等,所以为了安全,增加了一个token,在一定程度上,提升了被暴力遍历的复杂度。而这一部分的方法也很简单:
@csrf_exempt
def information(request):
uid = request.GET.get("uid", None)
token = request.GET.get("token", None)
if None in [uid, token]:
return JsonResponse({"Error": "Uid and token are required."})
userInfor = UserModel.objects.filter(uid=uid, token=token)
if userInfor.count() == 0:
return JsonResponse({"Error": "No information found yet."})
if not userInfor[0].result:
return JsonResponse({"Error": "No winning information has been found yet."})
if request.method == "GET":
return JsonResponse({
"Result": {
"prize": userInfor[0].pre_prize,
"name": userInfor[0].name,
"phone": userInfor[0].phone,
"address": userInfor[0].address
}
})
elif request.method == "POST":
name = request.POST.get("name", None)
phone = request.POST.get("phone", None)
address = request.POST.get("address", None)
if None in [name, phone, address]:
return JsonResponse({"Error": "Name, phone and address are required."})
userInfor.update(name=name,
phone=phone,
address=address)
return JsonResponse({"Result": "Saved successfully."})
整个流程是:
- 通过用户的
uid和token进行相关用户信息的获取; - 如果请求方法是GET方法,那么则直接返回用户的中奖信息(指的是收货信息);
- 如果请求方法是POST方法,则允许用户进行中奖信息的修改(指的是收货信息);
其他安全方面的补充:
- 如何保证用户的token等信息的唯一性以及不可伪造性,这一部分在浏览器端是不太容易实现的,因为用户可能换浏览器,但是对于用户的在函数计算平台的函数服务中就相对容易实现了,所以采用域名下发阶段,对指定时间段下发过的域名信息进行记录,再在后期进行对比,以保证用户确实通过Serverless Devs开发者工具进行了项目部署,下发了临时域名,并在规定的时间内参加了活动;(当然,如果用户注册了多个阿里云账号,进行该活动的参加,这个时候是被允许的)
- 如何保证奖品不会被超发,这一部分在该系统中,采用了一个比较”笨“的方法,但是也是针对小型平台更容易实现的方法,即先给用户一个奖品标记,然后再根据用户奖品在数据库中的时序位置,进行最终中奖信息的判断,例如,用户中奖一个机械键盘,在数据库中是中机械键盘的第6位置,但是一共只有5个机械键盘,所以此时会对用户的中奖信息二次核对并标记未中奖。(当然,这种做法针对小规模活动是可以的,但是针对大型活动是不可取的,因为用户是否中奖这件事情,会导致多次数据库的读写操作,在一定程度上是不合理的)
- 用户中奖之后,提交了奖品邮寄信息,如何保证该信息的安全性,不被其他人暴力遍历出来也是值得关注的问题,此处采用增加了一个随机token,以增加被暴力遍历出来的复杂度,进一步保障安全;
部署准备工作
本次部署无需域名,使用函数计算生成的自定义域名即可,依然需要安装好 Serverless Devs 工具,本次只需开通函数计算即可。
操作步骤
摇奖后台的部分模板还在准备中,仅演示部署前端和数据层的服务。
步骤1:秘钥配置
步骤2:初始化
使用serverless devs 命令行工具执行:
s init blindbox-game
进入引导式操作:

步骤3:构建部署
修改一下相关的配置信息,执行s deploy
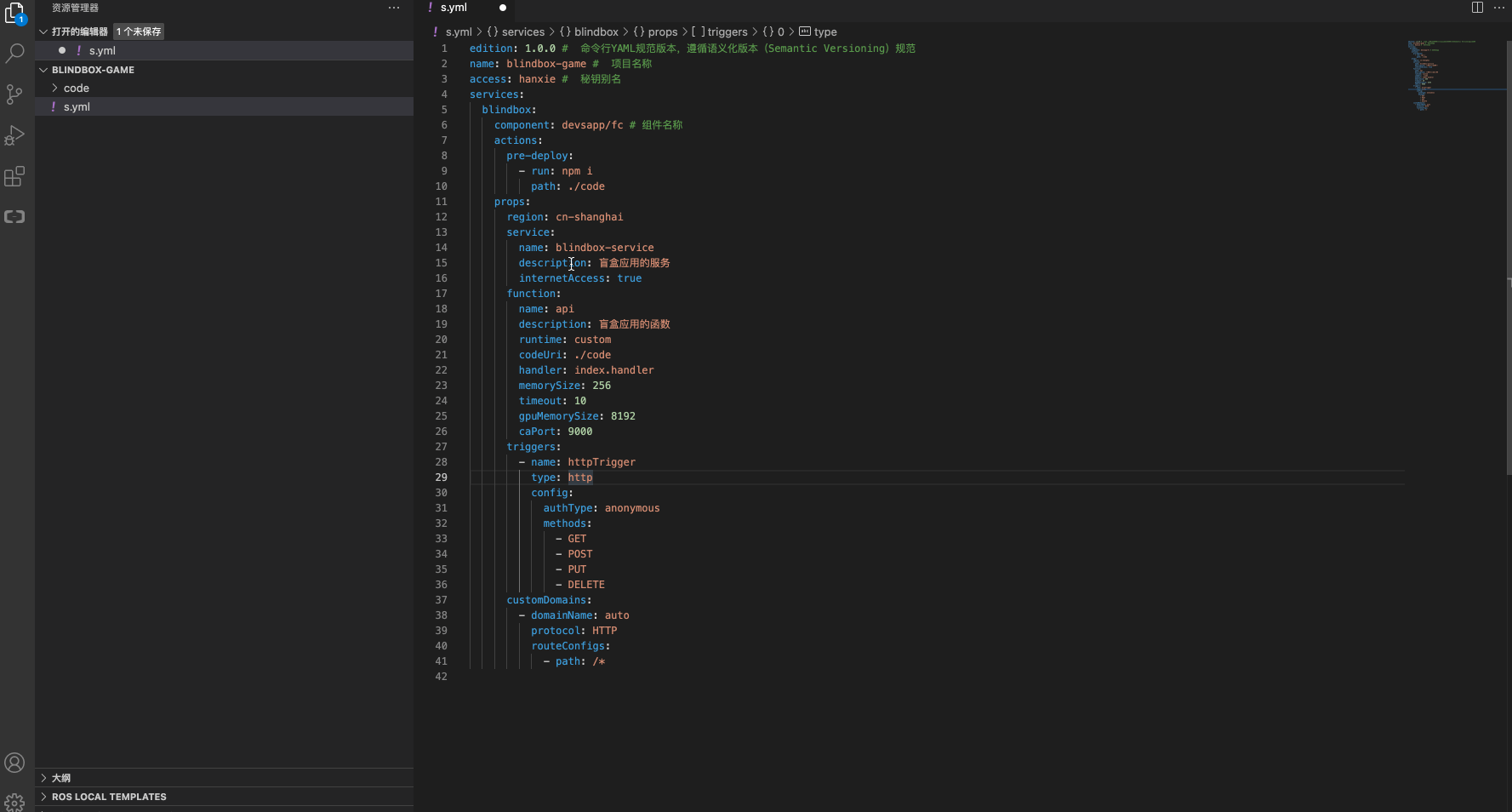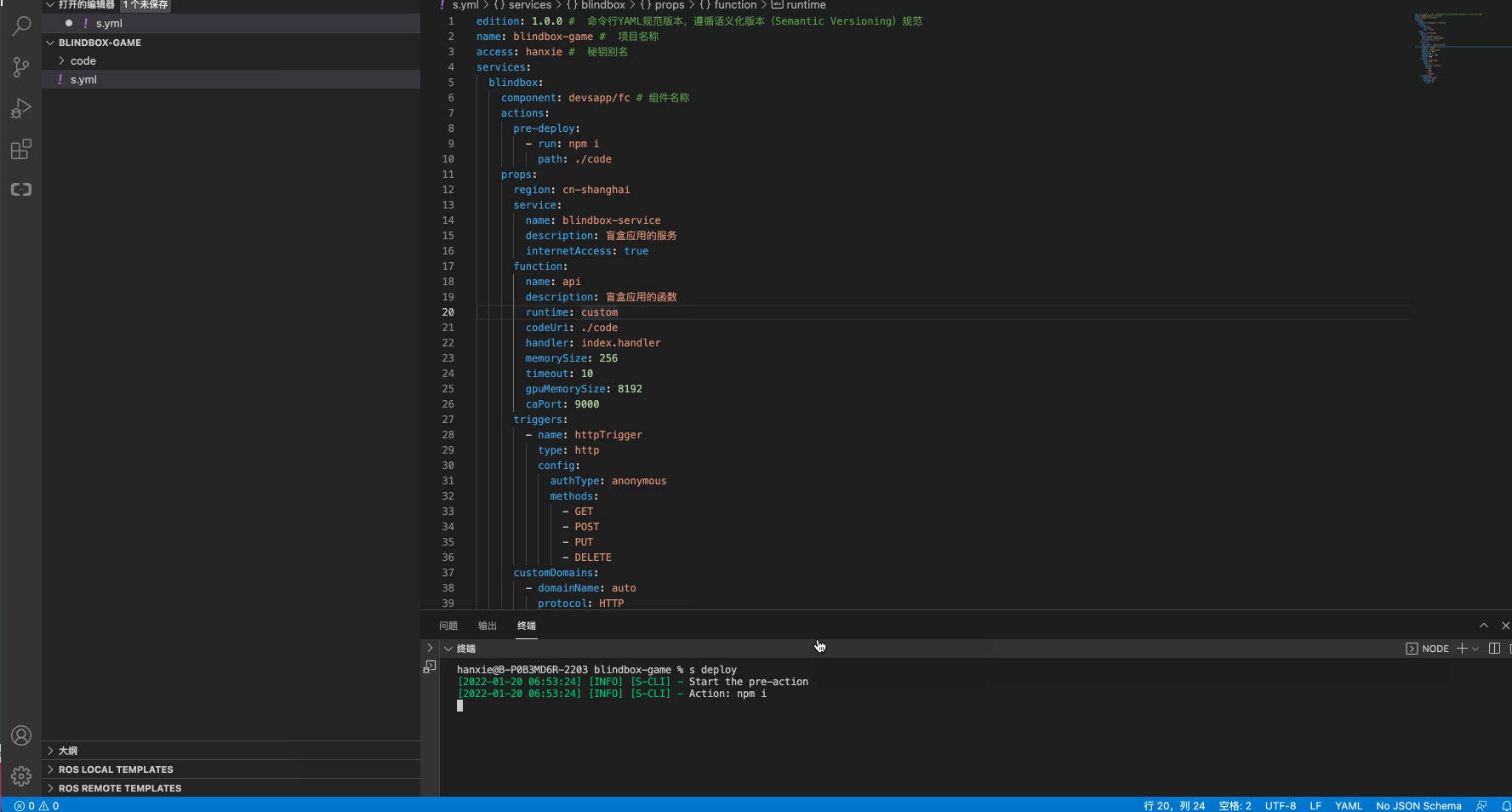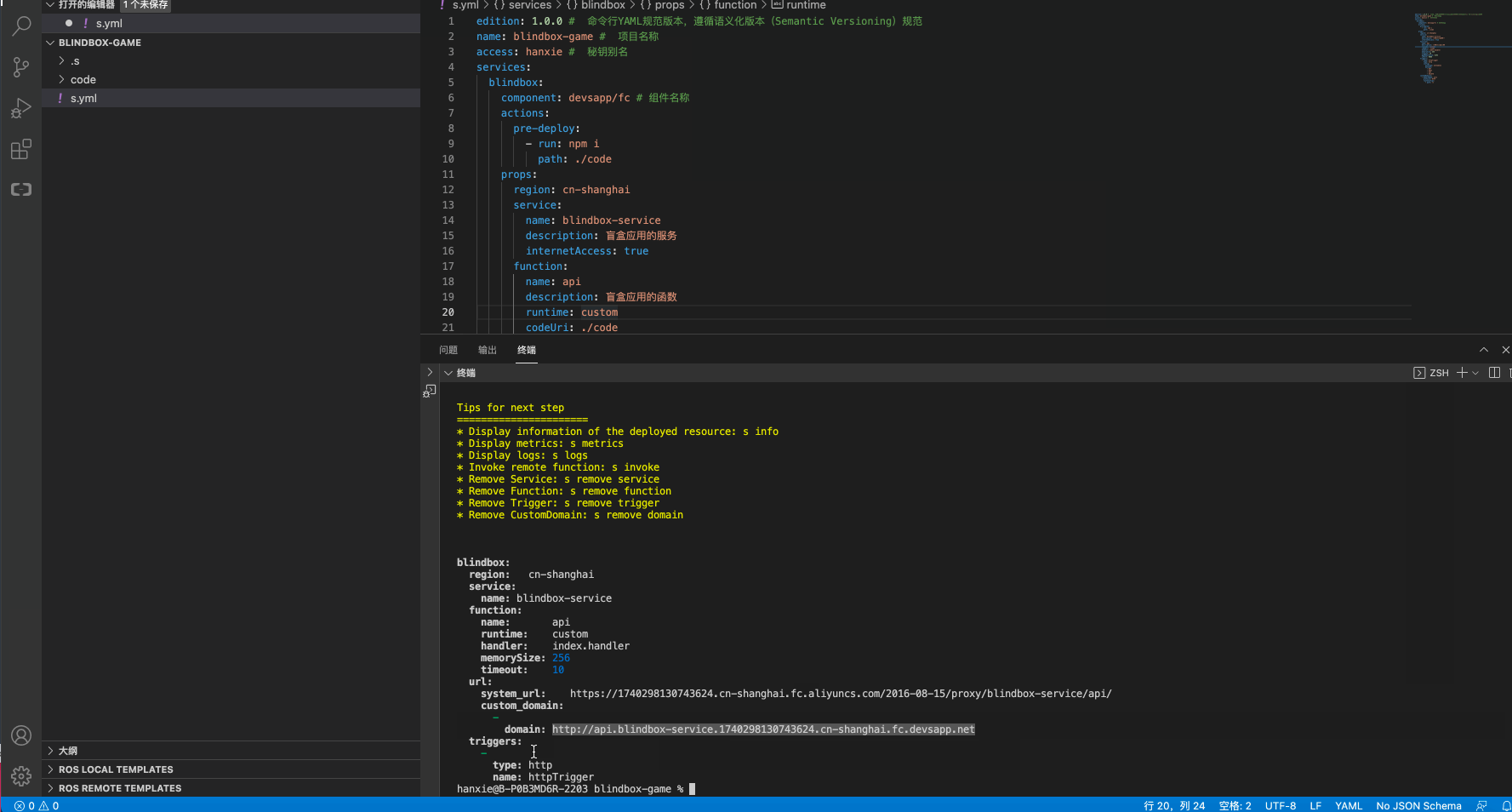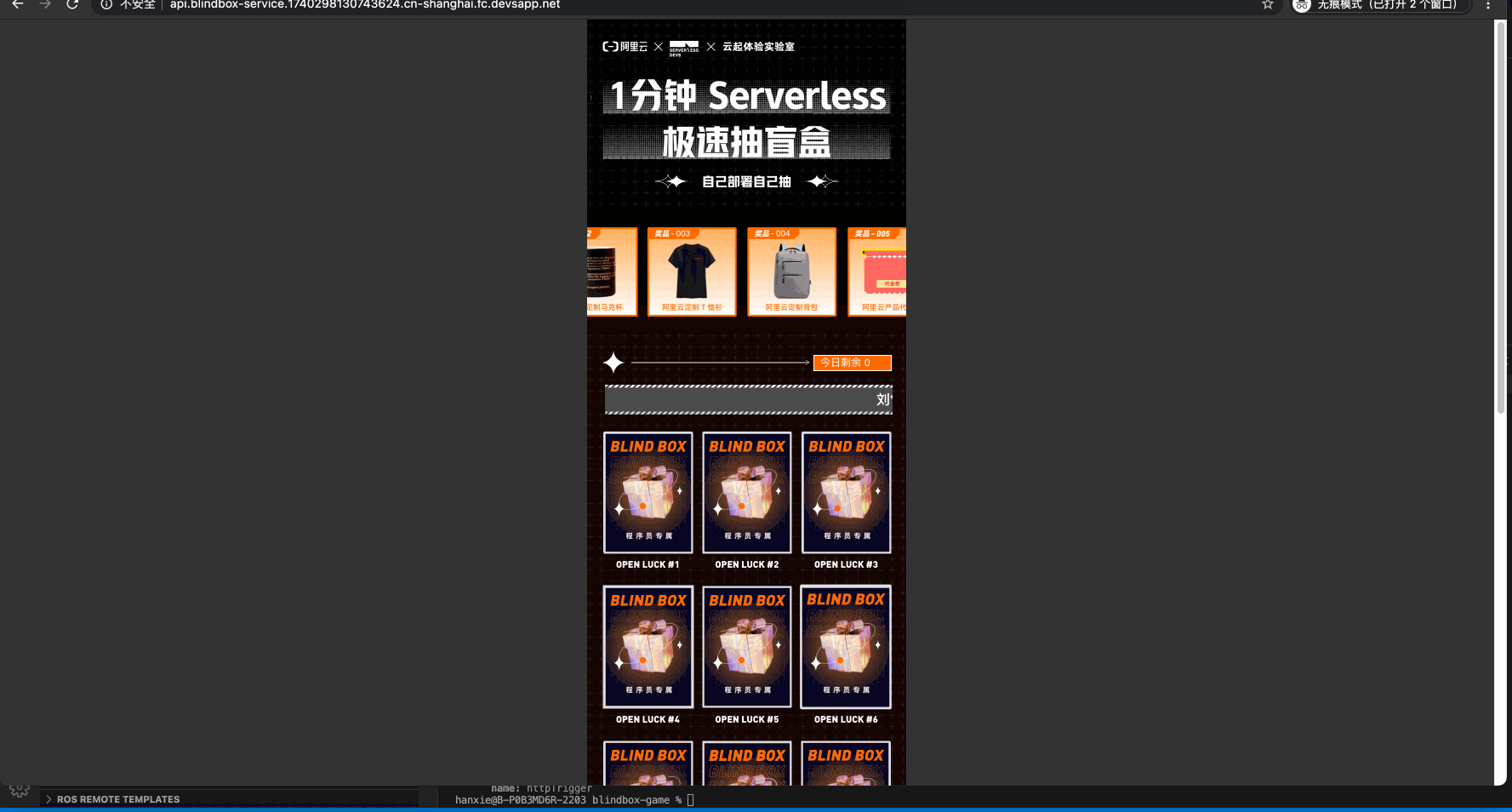
效果查看
函数部署情况:

页面效果:

摇奖部分的应用模板正在准备中,后续也会统一在这个应用模板给大家提供展示。
结语
上面实践结束后关于低代码和 Serverless 这个话题想跟大家再展开一下,以下部分并会以理论性为主,希望能够给读者带来不一样的收获。
开发者视角的 Serverless + 低代码
就我自身而言的话,明确的结论是我并不排斥两者的相容,反而非常期待这两者结合能够进一步让我的工作更加高效,安全。
本次活动我的最大感触是,如果低代码平台能够跟 Serverless 无缝衔接就好了,比如我在低代码上调用接口现在只能构建发到线上之后才能测试,这点天然集成好的平台优势就会很明显。另外就是发布构建好前端之后还得再去跟后端接口组装,这个如果是统一平台的话搞完需求就可以一键发布,会省不少事。不过这里也比较矛盾,因为我也担心一旦低代码的前端跟 Serverless 的后端耦合在一起就会变得不灵活,被服务商锁定。
供应商视角的 Serverless + 低代码
可以看到现在云服务商的 Serverless 和低代码的服务商在互相融合。比如低代码平台领导者 outsystem 早在 2016 年就开始使用 AWS 的服务,比如 Lambda 等为他们的客户提供原生 APP 服务的构建。
以 serverless & model-driven application 作为主体服务的低代码平台 Trillo 则是以 Google 云服务构为基础帮助他们的用户构建 Serverless 服务和前端应用,当然国内外的各家云厂商也没闲着 Azure 将自家的低代码产品 Power Apps 融入了 Serverless 的能力形成 Serverless Power Apps,将二者的优势做了充分融合。
Aws 将前端的集成都交给了伙伴,自身更专注于服务侧的 Serverless 集成,并且推出了 Step Functions Workflow Studio 产品将 Serverless 跟自家几乎所有的产品串联到了一起。
国内腾讯推出了微搭低代码平台,也是主打 Serverless + 低代码,在小程序场景发力,各厂商的跟进也说明了对这个领域的重视。
打造 Serverless + 低代码平台的设想
Serverless + 低代码平台的价值是比较明确的,效率,安全,成本都是它的关键词。那么假设我们要去建设这样的平台需要做哪些方面的考虑呢?
首先是从平台能力上,应该要做到能够覆盖一个应用开发从前到后的方方面面。比如:
- 数据建模
- 数据模型 API 化
- 使用 Serverless 构建后端应用逻辑
- 支持部署 Long-Runing 的后端服务
- 可扩展的外部服务集成
- 文件存储
- 逻辑编排
- 各种安全能力比如身份验证,权限控制等
- UI 编排
- CI/CD
- 应用可观测
这里可以简单理一下这个平台的功能设计,依托于云厂商的基础设施构建相应的能力。

相关的低代码能部分的能力有一些相关的开源产品,这里可以分享给大家:
- ui 页面搭建https://github.com/alibaba/designable
- 数据库建模https://gitee.com/robergroup/chiner
- 流程编排https://github.com/i5ting/imove
另外跟云基础设施打通部分可以考虑利用 Serverless Devs 的 Iac 能力,尤其是目前在跟 FC 的集成上成熟度比较高,可以很方便的对函数全生命周期进行管理。
当然以上仅是笔者的一些设想,我深知实现这样的系统绝非易事,这里也只是抛转引玉用。
追求生产效率的提升始终是企业生产的重要话题,Serverless 和低代码在各自的技术领域上有着独立的分工,却也有着共同的提高生产效率的特性,学会同时掌握利用好这两个生产力工具或许会是从事信息产业同学的重要竞争力。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。