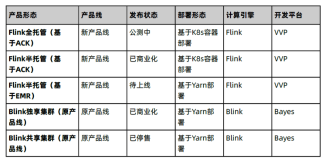
下面是关于Apache Flink(以下简称Filnk)框架和流式计算的概述。为了更专业、更技术化的介绍,在Flink文档中推荐了一些“概念性”的文章。
1、无穷数据集的持续计算
在我们详细介绍Flink前,复习一下当我们计算数据选择运算模型时,很可能会遇到的一个更高级别的数据集类型。下面有两个观点经常容易混淆,很有必要去澄清它们。
(1)两种数据集类型:
①无穷数据集:无穷的持续集成的数据集合。
②有界数据集:有限不会改变的数据集合。
很多现实中传统地认为有界或者批量的数据集合实际上是无穷数据集,不论这些数据是存储在HDFS的一系列目录中还是在那些基于日志的系统中(如 Apache Kafka)。
包含无边界数据集的场景,举例如下:
①终端用户用手机或者web应用做的交互。
②物理传感器提供的测量数据。
③金融市场产生的数据。
④服务器上的日志数据。
(2)两种数据运算模型
①流式:只要数据一直在产生,计算就持续地进行
②批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
用任意一种运算模型去计算任何一种数据集是可能的,尽管这种选择不是最佳的。比如,批处理长期应用于处理无穷数据集,尽管存在视窗、状态管理和无序数据等潜在的风险问题。
Flink 是基于直观地去处理无穷数据集的流式运算模型:流式运算会一直计算持续生成的数据。数据集与运算模型的对应,在准确性和性能上有很大的优势。
2、功能特点:为什么选择Flink?
Flink是一个开源的分布式流式处理框架:
①提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
②它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
③大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
更早的时候,我们讨论了数据集类型(有界 vs 无穷)和运算模型(批处理vs流式)的匹配。Flink的流式计算模型启用了很多功能特性,如状态管理,处理无序数据,灵活的视窗,这些功能对于得出无穷数据集的精确结果是很重要的。
- Flink保证状态化计算强一致性。”状态化“意味着应用可以维护随着时间推移已经产生的数据聚合或者,并且Filnk的检查点机制在一次失败的事件中一个应用状态的强一致性。
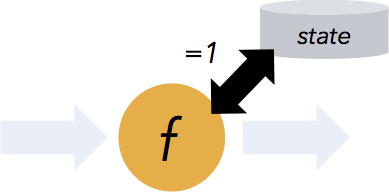
- Flink支持流式计算和带有事件时间语义的视窗。事件时间机制使得那些事件无序到达甚至延迟到达的数据流能够计算出精确的结果。

- 除了提供数据驱动的视窗外,Flink还支持基于时间,计数,session等的灵活视窗。视窗能够用灵活的触发条件定制化从而达到对复杂的流传输模式的支持。Flink的视窗使得模拟真实的创建数据的环境成为可能。

- Flink的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证。Flink以零数据丢失的方式从故障中恢复,但没有考虑可靠性和延迟之间的折衷。
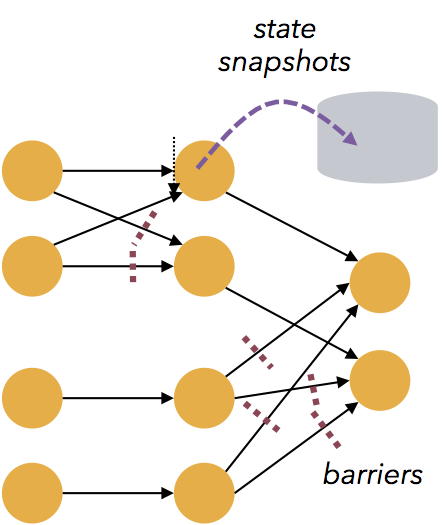
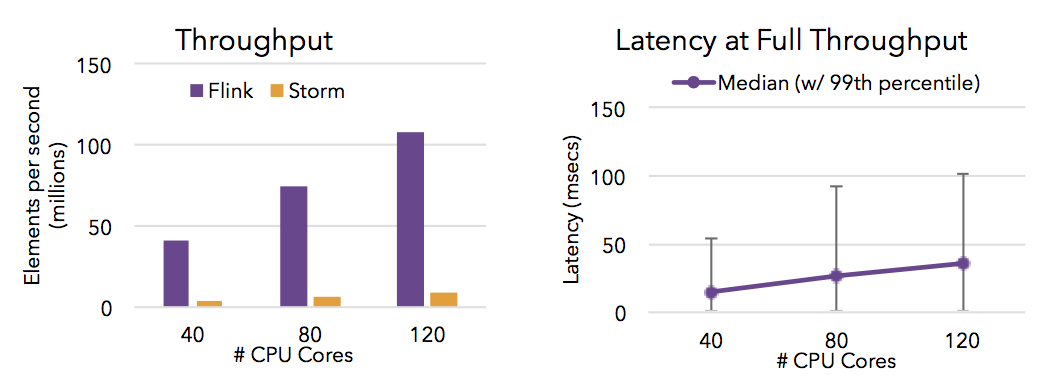
- Flink能满足高并发和低延迟(计算大量数据很快)。下图显示了Apache Flink 与 Apache Storm在完成流数据清洗的分布式任务的性能对比。
- Flink保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据。
- Flink被设计成能用上千个点在大规模集群上运行。除了支持独立集群部署外,Flink还支持YARN 和Mesos方式部署。
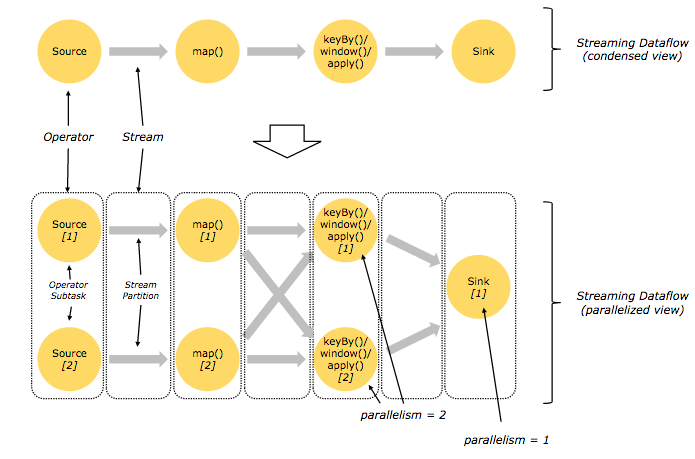
3、Flink,流模型和有界数据集
当你阅读Flink的文档时,可能会发现文章中既有面向无穷数据集的数据流api,也有面向有界数据的数据集api。
此前的写作,我们介绍了直观上适合无穷数据集的流式运算模型(持续地执行处理,一次一个事件)。所以有界数据集是如何与流式运算范例相关呢?
这是Flink 数据集API所呈现的。Flink内部将有界数据集作为“有限的流”处理,这种方式使得Flink在如何管理有界与无穷数据集上仅仅有非常少的差异。
所以用Flink去处理有界数据和无穷数据是可能的,这两个Api运行在相同的分布式流式运算引擎。这是一个简单又高效的模型。
4、从下至上,Flink整体结构
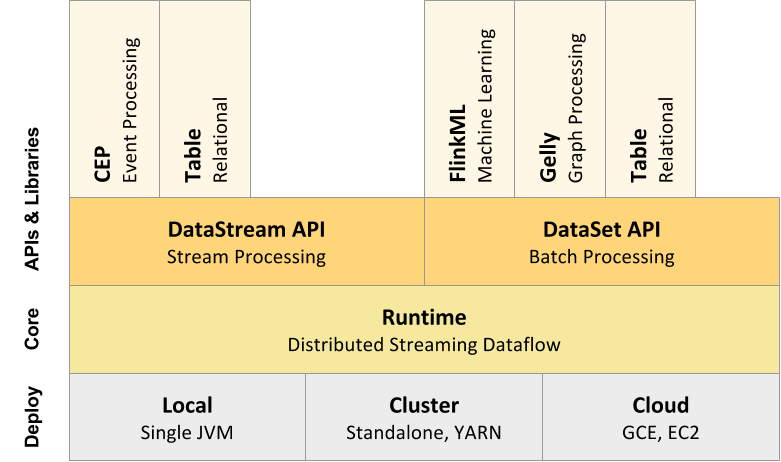
(1)部署模式
Flink能部署在云上或者局域网中,能在独立集群或者在被YARN或Mesos管理的集群上运行。
(2)运行期
Flink的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理,这跟批次处理有很大不同。这个保证了上面说的那些Flink弹性和高性能的特性。
(3)API
- Flink的数据流API适合用于那些实现在数据流上转换的程序(例如:过滤,更新状态,定义视窗,聚合)
- Flink的数据集API适合用于那些实现在数据流上转换的程序(例如:过滤,映射,加入,分组)
- 表Api适合于关系流和批处理,能轻松嵌入Flink的数据集APi和数据流API的类SQL表达式的语言(java和Scala)
- 流式SQL允许在流和多表上执行SQL查询。这个句法是基于 Apache Calcite。
(4)代码库
Flink还包括用于复杂事件处理,机器学习,图形处理和Apache Storm兼容性的专用代码库。
5、Flink和其他的框架
从最基本的水平上看,一个Flink程序由下面几部分组成:
- 数据源:Flink处理的输入的数据。
- 转化:Flink对数据进行处理的步骤。
- 接收器:Flink将处理之后的数据发送的地点。

一个发展挺好的生态系统对于进出一个Flink程序的数据作高效移动是非常必要的,Flink支持范围广泛的用于数据源和连接器的第三方系统的连接。如果想学习更多,这里收集了Flink生态系统的信息。
6、后续
总而言之,Apache Flink是一个开源流处理框架,可以消除通常与开源流引擎相关联的“性能与可靠性”折衷,并在两个类别中始终保持一致。 接下来介绍,我们建议您尝试我们的快速入门,下载最新的稳定版本的Flink,或查看文档。
我们鼓励您加入Flink用户邮件列表,并与社区分享您的问题。 我们在这里帮助您充分利用Flink。