
一、高可用拓扑
可以设置 HA 集群:
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存;
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行;
在设置 HA 集群之前,应该仔细考虑每种拓扑的优缺点。
1、堆叠(Stacked) etcd 拓扑
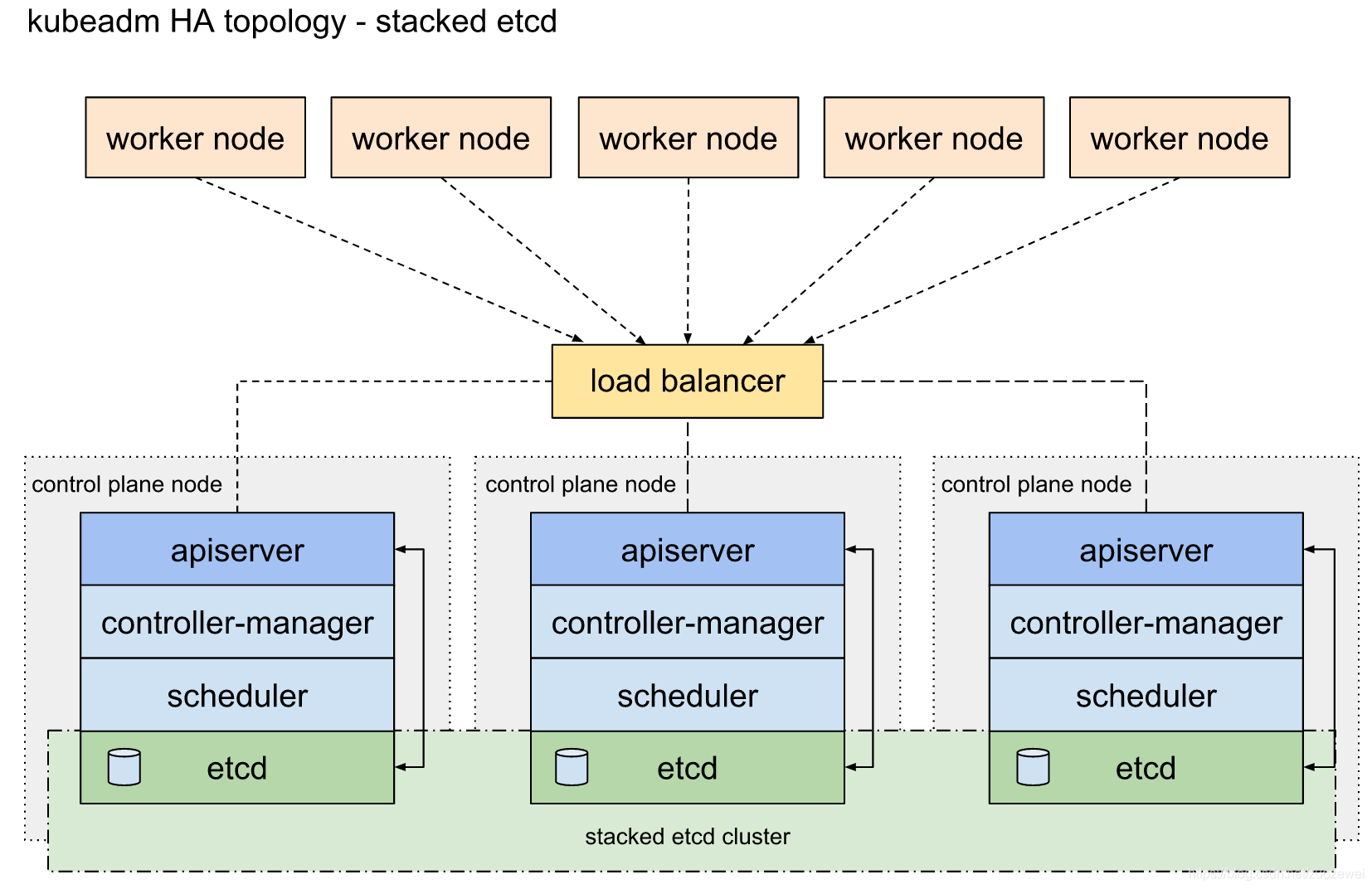
主要特点:
- etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
- 每个控制平面节点运行 kube-apiserver,kube-scheduler 和
kube-controller-manager实例。 - kube-apiserver 使用 LB 暴露给工作节点。
- 每个控制平面节点创建一个本地 etcd 成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
- 简单概况:每个 master 节点上运行一个 apiserver 和 etcd, etcd 只与本节点 apiserver 通信。
- 这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群,设置起来更简单,而且更易于副本管理。
- 然而堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失,并且冗余会受到影响。可以通过添加更多控制平面节点来降低此风险。应该为 HA 集群运行至少三个堆叠的控制平面节点(防止脑裂)。
- 这是 kubeadm 中的默认拓扑。当使用
kubeadm init和kubeadm join --control-plane时,在控制平面节点上会自动创建本地 etcd 成员。
2、外部 etcd 拓扑
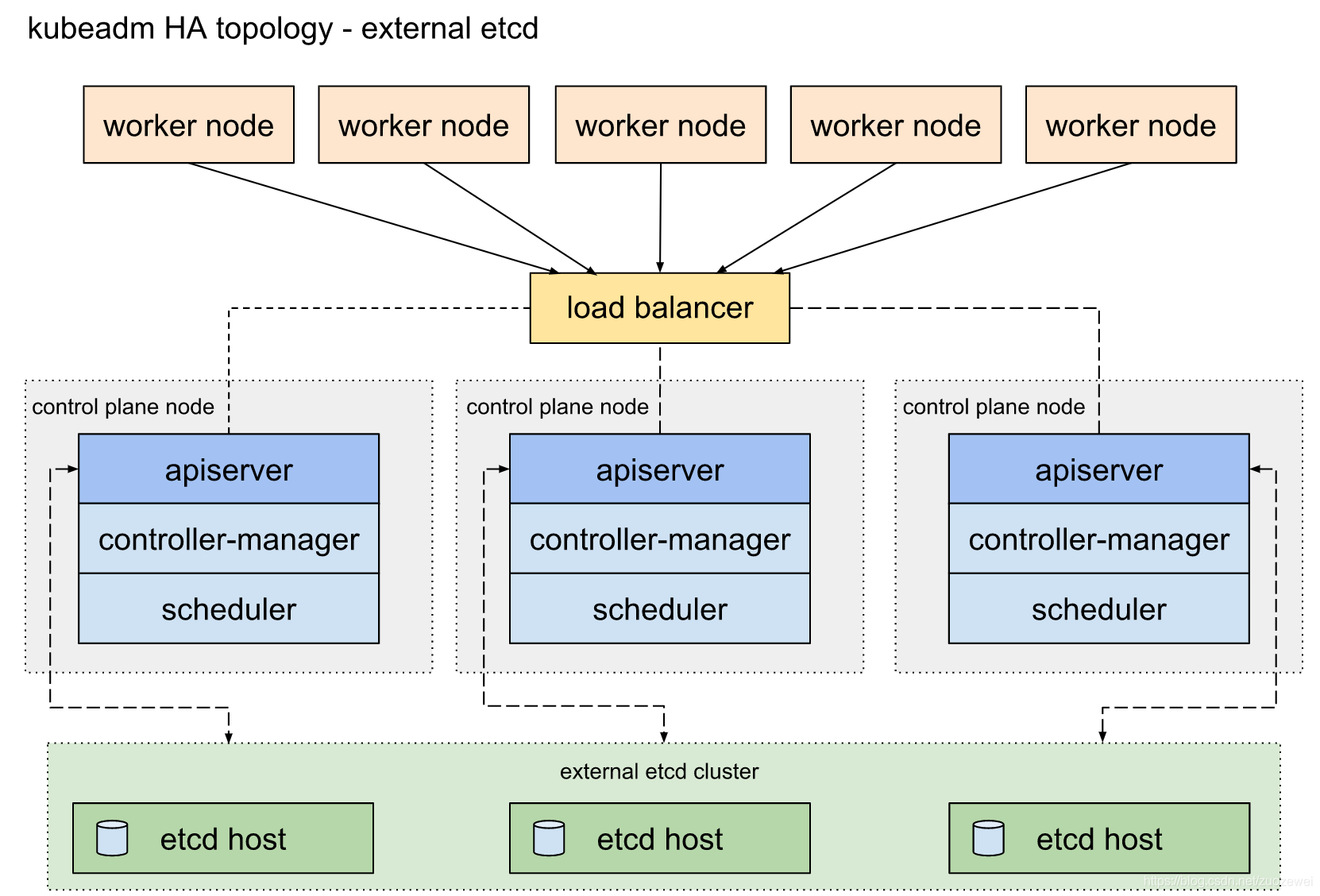
主要特点:
- 具有外部 etcd 的 HA 集群是一种这样的拓扑,其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
- 就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都运行 kube-apiserver,kube-scheduler 和
kube-controller-manager实例。 - 同样 kube-apiserver 使用负载均衡器暴露给工作节点。但是,etcd 成员在不同的主机上运行,每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
- 简单概况: etcd 集群运行在单独的主机上,每个 etcd 都与 apiserver 节点通信。
- 这种拓扑结构解耦了控制平面和 etcd 成员。因此,它提供了一种 HA 设置,其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
- 但是,此拓扑需要两倍于堆叠 HA 拓扑的主机数量。具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。
- 需要单独设置外部 etcd 集群。
3、小结
官方这里主要是解决了高可用场景下 apiserver 与 etcd 集群的关系,以及控制平面节点防止单点故障。但是集群对外访问接口不可能将三个 apiserver 都暴露出去,一个节点挂掉时还是不能自动切换到其他节点。官方只提到了一句“使用负载均衡器将 apiserver 暴露给工作节点”,而这恰恰是部署过程中需要解决的重点问题。
Notes: 此处的负载均衡器并不是 kube-proxy,此处的 Load Balancer 是针对 apiserver 的。
最后,我们总结一下两种拓扑:
- 堆叠(Stacked) etcd 拓扑:设置简单,易于副本管理 ,不过存在耦合失败风险。如果节点发生故障,则 etcd 成员和控制平面实例有丢失的可能,推荐测试开发环境;
- 外部 etcd 拓扑:解耦了控制平面和 etcd 成员,不会像堆叠的 HA 拓扑那样有影响集群冗余的风险,不过需要两倍于堆叠 HA 拓扑的主机数量,设置相对复杂,推荐生产环境。
二、部署架构
以下是我们在测试环境所用的部署架构:
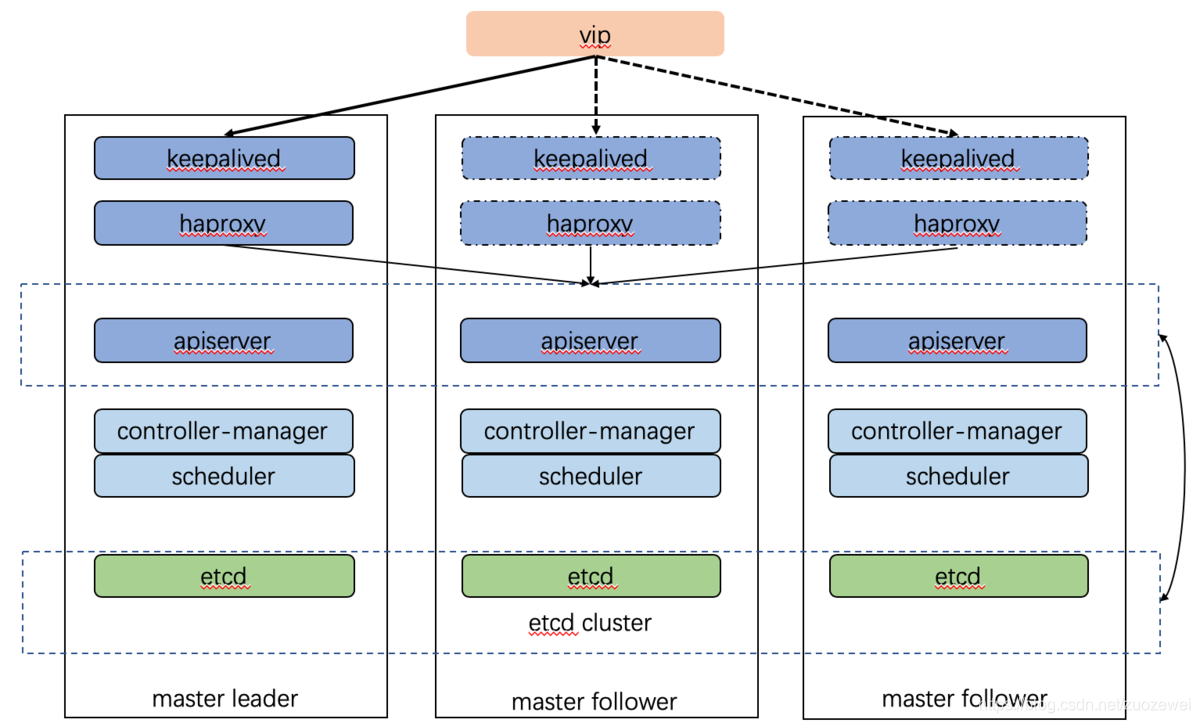
这里采用 kubeadm 方式搭建高可用 k8s 集群,k8s 集群的高可用实际是 k8s 各核心组件的高可用,这里使用主备模式:
| 核心组件 | 高可用模式 | 高可用实现方式 |
|---|---|---|
| apiserver | 主备 | keepalived + haproxy |
| controller-manager | 主备 | leader election |
| scheduler | 主备 | leader election |
| etcd | 集群 | kubeadm |
- apiserver 通过 keepalived+haproxy 实现高可用,当某个节点故障时触发 keepalived vip 转移,haproxy 负责将流量负载到 apiserver 节点;
- controller-manager k8s 内部通过选举方式产生领导者(由
--leader-elect选型控制,默认为 true),同一时刻集群内只有一个 controller-manager 组件运行,其余处于 backup 状态;- scheduler k8s 内部通过选举方式产生领导者(由
--leader-elect选型控制,默认为 true),同一时刻集群内只有一个scheduler组件运行,其余处于 backup 状态;- etcd 通过运行 kubeadm 方式自动创建集群来实现高可用,部署的节点数为奇数,3节点方式最多容忍一台机器宕机。
三、环境示例
主机列表:
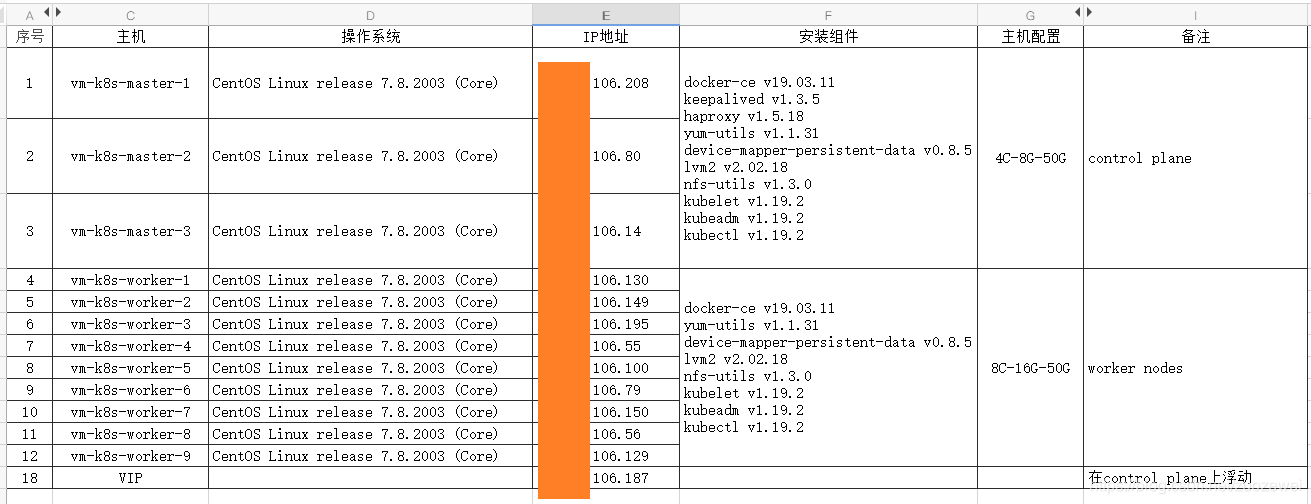
这里共有 12 台主机,3 台 control plane,9 台 worker。
四、核心组件
1、haproxy
haproxy 提供高可用性,负载均衡,基于 TCP 和 HTTP 的代理,支持数以万记的并发连接。
haproxy 可安装在主机上,也可使用 docker 容器实现。文本采用第一种。
创建配置文件 /etc/haproxy/haproxy.cfg,重要配置以中文注释标出:
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# https://www.haproxy.org/download/2.1/doc/configuration.txt
# https://cbonte.github.io/haproxy-dconv/2.1/configuration.html
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
# chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
# user haproxy
# group haproxy
# daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:9443 ## 监听9443端口
# bind *:443 ssl # To be completed ....
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp # 模式tcp
balance roundrobin # 采用轮询的负载算法
# k8s-apiservers backend # 配置apiserver,端口6443
server k8s-master-1 xxx.16.106.208:6443 check
server k8s-master-2 xxx.16.106.80:6443 check
server k8s-master-3 xxx.16.106.14:6443 check
分别在三个 master 节点启动 haproxy。
2、keepalived
keepalived 是以 VRRP(虚拟路由冗余协议)协议为基础, 包括一个 master 和多个 backup。 master 劫持 vip 对外提供服务。master 发送组播,backup 节点收不到 vrrp 包时认为 master 宕机,此时选出剩余优先级最高的节点作为新的 master, 劫持 vip。keepalived 是保证高可用的重要组件。
keepalived 可安装在主机上,也可使用 docker 容器实现。文本采用第一种。
配置 keepalived.conf, 重要部分以中文注释标出:
! Configuration File for keepalived
global_defs {
router_id k8s-master-1
}
vrrp_script chk_haproxy {
script "/bin/bash -c 'if [[ $(netstat -nlp | grep 9443) ]]; then exit 0; else exit 1; fi'" # haproxy 检测
interval 2 # 每2秒执行一次检测
weight 11 # 权重变化
}
vrrp_instance VI_1 {
state MASTER # backup节点设为BACKUP
interface eth0
virtual_router_id 50 # id设为相同,表示是同一个虚拟路由组
priority 100 # 初始权重
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.106.187 # vip
}
track_script {
chk_haproxy
}
}
- vrrp_script 用于检测 haproxy 是否正常。如果本机的 haproxy 挂掉,即使 keepalived 劫持vip,也无法将流量负载到 apiserver。
- 我所查阅的网络教程全部为检测进程, 类似
killall -0 haproxy。这种方式用在主机部署上可以,但容器部署时,在 keepalived 容器中无法知道另一个容器 haproxy 的活跃情况,因此我在此处通过检测端口号来判断 haproxy 的健康状况。 - weight 可正可负。为正时检测成功
+weight,相当与节点检测失败时本身 priority 不变,但其他检测成功节点 priority 增加。为负时检测失败本身 priority 减少。 - 另外很多文章中没有强调 nopreempt 参数,意为不可抢占,此时 master 节点失败后,backup 节点也不能接管 vip,因此我将此配置删去。
分别在三台节点启动 keepalived,查看 keepalived master 日志:
Dec 25 15:52:45 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Script(chk_haproxy) succeeded # haproxy检测成功
Dec 25 15:52:46 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Changing effective priority from 100 to 111 # priority增加
Dec 25 15:54:06 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Transition to MASTER STATE
Dec 25 15:54:06 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Received advert with lower priority 111, ours 111, forcing new election
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Entering MASTER STATE
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) setting protocol VIPs. # 设置vip
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:07 k8s-master-1 avahi-daemon[756]: Registering new address record for 172.16.106.187 on eth0.IPv4.
Dec 25 15:54:10 k8s-master-1 kubelet: E1225 15:54:09.999466 1047 kubelet_node_status.go:442] Error updating node status, will retry: failed to patch status "{\"status\":{\"$setElementOrder/conditions\":[{\"type\":\"NetworkUnavailable\"},{\"type\":\"MemoryPressure\"},{\"type\":\"DiskPressure\"},{\"type\":\"PIDPressure\"},{\"type\":\"Ready\"}],\"addresses\":[{\"address\":\"172.16.106.187\",\"type\":\"InternalIP\"},{\"address\":\"k8s-master-1\",\"type\":\"Hostname\"},{\"$patch\":\"replace\"}],\"conditions\":[{\"lastHeartbeatTime\":\"2020-12-25T07:54:09Z\",\"type\":\"MemoryPressure\"},{\"lastHeartbeatTime\":\"2020-12-25T07:54:09Z\",\"type\":\"DiskPressure\"},{\"lastHeartbeatTime\":\"2020-12-25T07:54:09Z\",\"type\":\"PIDPressure\"},{\"lastHeartbeatTime\":\"2020-12-25T07:54:09Z\",\"type\":\"Ready\"}]}}" for node "k8s-master-1": Patch "https://apiserver.demo:6443/api/v1/nodes/k8s-master-1/status?timeout=10s": write tcp 172.16.106.208:46566->172.16.106.187:6443: write: connection reset by peer
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth0 for 172.16.106.187
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:11 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:54:12 k8s-master-1 Keepalived_vrrp[12562]: Sending gratuitous ARP on eth0 for 172.16.106.187
查看 master vip:
[root@k8s-master-1 ~]# ip a|grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 172.16.106.208/24 brd 172.16.106.255 scope global noprefixroute dynamic eth0
inet 172.16.106.187/32 scope global eth0
可以看到 vip 已绑定到 keepalived master
下面进行破坏性测试:
暂停 keepalived master 节点 haproxy:
[root@k8s-master-1 ~]# service haproxy stop
Redirecting to /bin/systemctl stop haproxy.service
查看 keepalived k8s-master-1 节点日志:
Dec 25 15:58:31 k8s-master-1 Keepalived_vrrp[12562]: /bin/bash -c 'if [[ $(netstat -nlp | grep 9443) ]]; then exit 0; else exit 1; fi' exited with status 1
Dec 25 15:58:31 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Script(chk_haproxy) failed
Dec 25 15:58:31 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Changing effective priority from 111 to 100
Dec 25 15:58:32 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Received advert with higher priority 111, ours 100
Dec 25 15:58:32 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) Entering BACKUP STATE
Dec 25 15:58:32 k8s-master-1 Keepalived_vrrp[12562]: VRRP_Instance(VI_1) removing protocol VIPs.
可以看到 haproxy 检测失败,priority 降低,同时另一节点 priority 比 k8s-master-1 节点高, k8s-master-1 置为 backup
查看 k8s-master-2 节点 keepalived日志:
Dec 25 15:58:35 k8s-master-2 Keepalived_vrrp[3661]: VRRP_Instance(VI_1) Transition to MASTER STATE
Dec 25 15:58:35 k8s-master-2 Keepalived_vrrp[3661]: VRRP_Instance(VI_1) Received advert with lower priority 111, ours 111, forcing new election
Dec 25 15:58:36 k8s-master-2 Keepalived_vrrp[3661]: VRRP_Instance(VI_1) Entering MASTER STATE
Dec 25 15:58:36 k8s-master-2 Keepalived_vrrp[3661]: VRRP_Instance(VI_1) setting protocol VIPs.
Dec 25 15:58:36 k8s-master-2 Keepalived_vrrp[3661]: Sending gratuitous ARP on eth0 for 172.16.106.187
Dec 25 15:58:36 k8s-master-2 avahi-daemon[740]: Registering new address record for 172.16.106.187 on eth0.IPv4.
可以看到 k8s-master-2 被选举为新的 master。
五、安装部署
1、安装 docker / kubelet
参考上文 使用 kubeadm 安装单master kubernetes 集群(脚本版)
2、初始化第一个 master
kubeadm.conf 为初始化的配置文件:
[root@master01 ~]# more kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.16.4
apiServer:
certSANs: #填写所有kube-apiserver节点的hostname、IP、VIP
- k8s-master-1
- k8s-master-2
- k8s-master-3
- k8s-worker-1
- apiserver.demo
.....
controlPlaneEndpoint: "172.27.34.130:6443"
networking:
podSubnet: "10.244.0.0/16"
初始化 k8s-master-1:
# kubeadm init
# 根据您服务器网速的情况,您需要等候 3 - 10 分钟
kubeadm init --config=kubeadm-config.yaml --upload-certs
# 配置 kubectl
rm -rf /root/.kube/
mkdir /root/.kube/
cp -i /etc/kubernetes/admin.conf /root/.kube/config
# 安装 calico 网络插件
# 参考文档 https://docs.projectcalico.org/v3.13/getting-started/kubernetes/self-managed-onprem/onpremises
echo "安装calico-3.13.1"
kubectl apply -f calico-3.13.1.yaml
3、初始化第二、三个 master 节点
可以和第一个Master节点一起初始化第二、三个Master节点,也可以从单Master节点调整过来,只需要:
- 增加 Master 的 LoadBalancer
- 将所有节点的
/etc/hosts文件中 apiserver.demo 解析为 LoadBalancer 的地址 - 添加第二、三个Master节点
- 初始化 master 节点的 token 有效时间为 2 小时
这里我们演示第一个Master节点初始化2个小时后再初始化:
# 只在 第一个 master 上执行
[root@k8s-master-1 ~]# kubeadm init phase upload-certs --upload-certs
I1225 16:25:00.247925 19101 version.go:252] remote version is much newer: v1.20.1; falling back to: stable-1.19
W1225 16:25:01.120802 19101 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
5c120930eae91fc19819f1cbe71a6986a78782446437778cc0777062142ef1e6
获得 join 命令:
# 只在 第一个 master 节点上执行
[root@k8s-master-1 ~]# kubeadm token create --print-join-command
W1225 16:26:27.642047 20949 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
kubeadm join apiserver.demo:6443 --token kab883.kyw62ylnclbf3mi6 --discovery-token-ca-cert-hash sha256:566a7142ed059ab5dee403dd4ef6d52cdc6692fae9c05432e240bbc08420b7f0
则,第二、三个 master 节点的 join 命令如下:
# 命令行中,前面为获得的 join 命令,control-plane 指定的为获得的 certificate key
kubeadm join apiserver.demo:6443 --token kab883.kyw62ylnclbf3mi6 \
--discovery-token-ca-cert-hash sha256:566a7142ed059ab5dee403dd4ef6d52cdc6692fae9c05432e240bbc08420b7f0 \
--control-plane --certificate-key 5c120930eae91fc19819f1cbe71a6986a78782446437778cc0777062142ef1e6
检查 master 初始化结果:
[root@k8s-master-1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master-1 Ready master 2d v1.19.2
k8s-master-2 Ready master 2d v1.19.2
k8s-master-3 Ready master 2d v1.19.2
4、初始化 worker节点
针对所有的 worker 节点执行:
# 只在 worker 节点执行
# 替换 x.x.x.x 为 ApiServer LoadBalancer 的 IP 地址
export MASTER_IP=x.x.x.x
# 替换 apiserver.demo 为初始化 master 节点时所使用的 APISERVER_NAME
export APISERVER_NAME=apiserver.demo
echo "${MASTER_IP} ${APISERVER_NAME}" >> /etc/hosts
# 替换为前面 kubeadm token create --print-join-command 的输出结果
kubeadm join apiserver.demo:6443 --token kab883.kyw62ylnclbf3mi6 --discovery-token-ca-cert-hash sha256:566a7142ed059ab5dee403dd4ef6d52cdc6692fae9c05432e240bbc08420b7f0
检查 worker 初始化结果:
[root@k8s-master-1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master-1 Ready master 2d v1.19.2
k8s-master-2 Ready master 2d v1.19.2
k8s-master-3 Ready master 2d v1.19.2
k8s-worker-1 Ready <none> 2d v1.19.2
k8s-worker-2 Ready <none> 2d v1.19.2
k8s-worker-3 Ready <none> 2d v1.19.2
k8s-worker-4 Ready <none> 2d v1.19.2
k8s-worker-5 Ready <none> 2d v1.19.2
k8s-worker-6 Ready <none> 2d v1.19.2
k8s-worker-7 Ready <none> 2d v1.19.2
k8s-worker-8 Ready <none> 2d v1.19.2
k8s-worker-9 Ready <none> 2d v1.19.2
本文资料:
参考资料:

