生产者吞吐量与存储数据
许多消息系统的隐藏危险之一是,对于在内存中保留的数据,它们工作的很好。但当数据备份不消耗(因此需要存储在磁盘上)时,它们的吞吐量下降一个数量级(或更多)。这意味着只要您的消费者保持消息队列及时清掉,事情就可以正常运行。但是一旦它们滞后,整个消息层将备份未消耗的数据。备份导致数据进入磁盘,这反过来会导致性能下降到一个速率,这意味着消息传递系统不能再跟上传入的数据,并把它们备份或者直接挂掉。这是非常可怕的,因为在许多情况下,队列的终极目的是优雅地处理这样的情况。
由于Kafka对于未消费的消息,总是保证O(1)的性能。
为了测试这个实验,让我们运行一段更长的时间,并在存储的数据集增长时绘制结果:
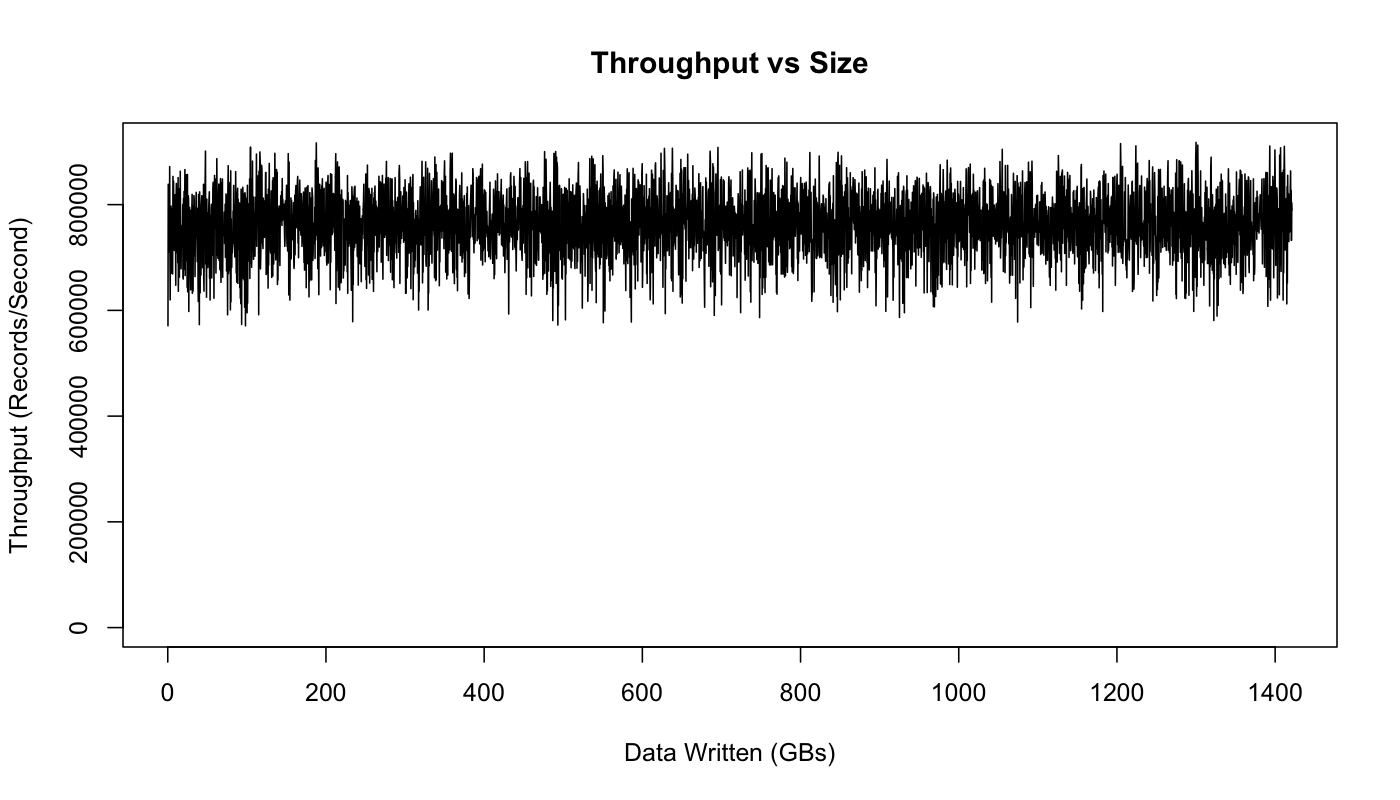
该图实际上显示了性能方面的变化,但跟数据大小没有影响,写入TB数据后跟最初写入几百MB性能一样好。
这种差异是由于Linux的I / O管理设施批处理数据,然后定期刷新。我们在Kafka生产集群配置上设置得更好。http://kafka.apache.org/documentation.html#hwandos
消费者吞吐量
现在让我们将注意力转向消费者吞吐量。
注意,复制因子不会影响此测试的结果,因为消费者只能从一个副本读取,无视副本数量。同样,生产者的确认级别也不重要,因为消费者只读取完全确认的消息(即使生产者不等待完全确认)。这是为了确保消费者看到的任何消息是在leader切换(如果当前leader失败)之后。
单个消费者
90452条记录/秒(89.7 MB /秒)
第一次测试,我们将在一个线程从我们的6分区3副本主题消费5000万条消息。
kafka的消费者是非常高效的。它通过从文件系统直接获取日志块来工作。它使用sendfile API直接通过操作系统传输,而无需通过应用程序复制此数据的开销。这个测试实际上是从日志头部开始,所以它正在做真正的I / O读取。然而,在生产环境中,消费者几乎完全从操作系统页面缓存中读取,因为它正在读取刚刚由一些生产者写入的数据(因此仍然被缓存)。实际上,如果您在生产服务器上运行I / O stat,看到即使消耗了大量数据,也没有任何物理读取。
对于期望的Kafka,消费者廉价是很重要的。一方面,副本自身就是消费者,所以让消费者便宜,使得复制便宜。另外,这样可以将数据处理变成一种廉价的操作,因此我们不需要紧紧控制可扩展性。
三个消费者
2615968个记录/秒(249.5 MB /秒)
让我们重复同样的测试,但是运行三个并行的消费者进程,每个进程在不同的机器,并且消耗同一主题。
如预期的那样,基本是线性扩展。(不奇怪,因为我们的模型中的消费者是如此简单)。
生产者和消费者
795064记录/秒(75.8 MB /秒)
上述测试只包括生产者和消费者独立运行。现在我们来做更符合实际情况的事情,一起运行。实际上,在技术上已经这样做了,因为我们的副本复制是把服务器当作消费者来实现的。
我们来运行测试。对于此测试,我们将在六分区3副本主题上运行一个生产者和一个消费者,这些主题将开始为空。生产者使用异步复制。报告的吞吐量是消费者吞吐量(生产者吞吐量的上限)。
正如我们预期的那样,结果基与只有生产者的情况相同 – 消费者相当便宜。
消息大小的影响/
之前报告的是100字节的小消息。较小的消息是消息系统更难的问题,因为它们会放大系统记录的开销。改变记录大小,在按照条数/秒和MB /秒中绘制吞吐量来证明。
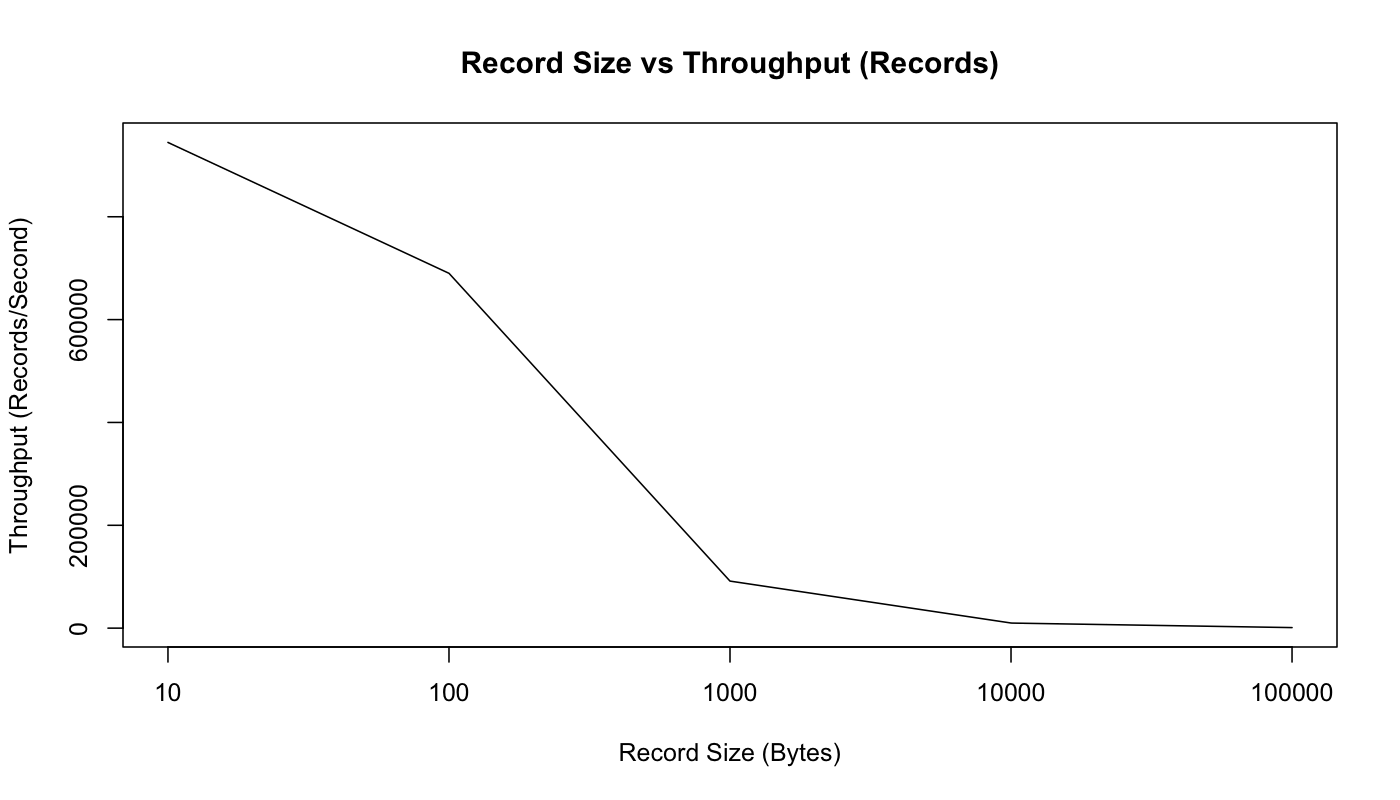
正如预期,这个图表显示由于数据变大,我们每秒可以发送的记录的原始记录条数减少。但是,如果在MB /秒图中,随着消息变大,实际用户数据的总字节吞吐量增加: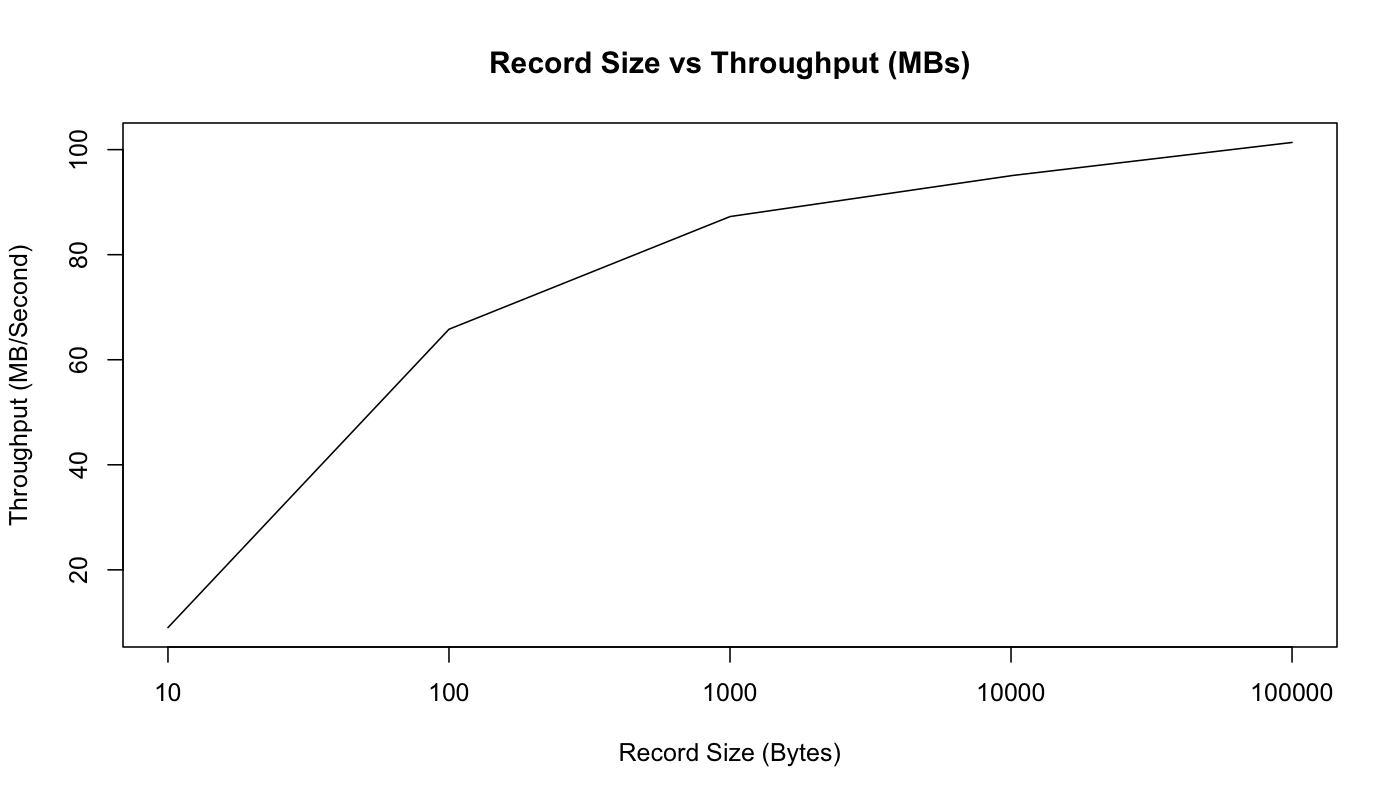
使用10个字节的消息,实际上被CPU来限制,因为是获取锁和发送消息入队操作,不能最大限度地发挥网络性能。然而,从100字节开始,网络开始饱和(尽管MB / sec持续增加,因为固定大小的字节与发送总字节占比的越来越小)。
端到端延迟
2ms(中位数)
3毫秒(99百分位数)
14毫秒(99.9百分位数)
关于吞吐量,我们已经谈到了很多,但是什么是消息传递的延迟?
也就是说,我们发送给消费者的消息需要多长时间?
对于这个测试,我们将创建生产者和消费者,并针对生产者向kafka集群发送消息需要多长时间,被消费者接收进行多次计时。
注意,Kafka只有所有同步副本确认消息时,才向消费者发出消息。无论是使用同步还是异步复制,这个测试将给出相同的结果。因为该设置只影响生产者的确认。
重复测试
如果你想在自己的机器上尝试这些基准测试,完全没问题。正如我所说,我大多只是使用我们与Kafka一起提供的预装性能测试工具,并且主要使用服务器和客户端的默认配置。您也可以在此处查看有关配置和命令的更多详细信息https://gist.github.com/jkreps/c7ddb4041ef62a900e6c。
