
背景
随着云原生的普及,各家公司都通过K8S实现了服务的容器化,极大的简化了开发运维人员的工作,是目前最为常用的基础服务。同时,K8S集群中的各项基础服务能够通过metrics接口导出Prometheus格式的多种指标,方便观察当前系统状态,及时发现问题。用户将K8S集群指标采集到日志服务SLS时序存储之后,可以随时查看系统历史及当前指标,还可以通过SLS内置仪表盘或者Grafana构建监控大盘,方便观察系统情况。但是随着系统规模以及负载成倍增加,复杂的指标查询以及监控大盘的渲染开始变慢,进而影响操作体验。
指标预聚和

指标预聚合指在后台定时运行批处理任务,按照一定的规则将多条系统指标合并为一条,减少所需指标计算涉及到的数据量,加快计算结果的产出。因而在观察指标确定的情况下,使用指标预聚合可以很好的解决前面遇到的问题。我们以CPU指标利用率的计算为例:

可以获取到K8S的两项指标:CPU累计使用时长container_cpu_usage_seconds_total以及CPU配额container_spec_cpu_quota。为了计算单位事件内CPU的利用率:
- 计算单位时间累计利用率: container_cpu_usage_minutes_total: sum(rate(container_cpu_usage_seconds_total{image!=""}[5m])) by (namespace,pod_name);
- 计算单位时间内的总CPU配额:container_spec_cpu_cores: (sum(container_spec_cpu_quota{image!=""}/100000) by (namespace,pod_name));
- 计算单位的CPU利用率:container_cpu_usage: container_cpu_usage_minutes_total: container_cpu_usage_minutes_total / container_spec_cpu_cores * 100
整条链路冗长而且速度慢,我们可以通过预先计算container_cpu_usage_minutes_total和container_spec_cpu_cores来加快计算速度。
本文主要介绍第一种方案,可以实现:
- 降低分析延迟:预计算多项常用系统指标,加快计算速度;
- 优化数据存储:只存储关心的聚合指标,定期清理详细指标;
原理即为使用SLS提供的ScheduledSQL服务,在后台定时运行SQL计算任务,将统计结果存入时序存储。
K8S指标
K8S指标众多,首先需要确定常用的监控指标,得到预聚合计算表达式。本文选取了Prometheus Operator中部分常用指标的计算表达式,更多的指标用户可以根据需求自行构建。
指标名称 |
说明 |
cpu_resource_request_percentage |
CPU Request水位 |
mem_resource_request_percentage |
Mem Request水位 |
kubelet_running_pod_percentage |
Pod水位 |
api_service_success_percentage |
APIServer请求成功率 |
CPU Request水位
* | select promql_query_range('(sum(kube_pod_container_resource_requests_cpu_cores))/(sum(kube_node_status_allocatable_cpu_cores)) * 100') from metrics limit 1000
Mem Request水位
* | select promql_query_range('(sum(kube_pod_container_resource_requests_memory_bytes))/(sum(kube_node_status_allocatable_memory_bytes)) * 100') from metrics limit 1000
Pod水位
* | select promql_query_range('(sum(kubelet_running_pod_count)-33)/(sum(kube_node_status_allocatable_pods)-330) * 100') from metrics limit 1000
APIServer请求成功率
* | select promql_query_range('sum(irate(apiserver_request_count{job="apiserver", code=~"20.*"}[5m]))/sum(irate(apiserver_request_count{job="apiserver"}[5m]))') from metrics limit 1000
ScheduledSQL实践
计算配置
资源池有免费(Project 级别 15 并行度)、增强型(收费,但资源可扩展,适用于大量计算且有 SLA 要求的业务场景)两种,按照你的需求来设置即可。

写入模式
写入模式有三种选择,当源为日志库时,可以选择日志库导入日志库以及日志库导入时序库;当源为时序库时,可以选择时序库导入时序库。因为K8S指标为时序库,计算结果为时序数据,所以此处选择时序库导入时序库。
结果指标名
指定计算结果的指标名称,默认选择metric列的值作为指标名称。此处需要注意,如果metric列的结果包含多种不同的指标名称,将会全部重命名为此处配置的指标名称。因为该例子中的指标名称为null,所以配置为cpu_resource_requests。
哈希列
如果时序库中同一label的数据写入到固定的hard中,可以增强局部性,提升查询效率。因此可以选择常用的过滤标签,作为哈系列,使给定标签相同的指标存入同一shard中。此处留空。
附加labels
为计算结果添加额外的属性,方便后续查询,此处留空。
调度配置
设置 SQL 每 5 分钟执行一次,每次执行处理最近 5 分钟窗口的数据。
注意:
1. 设置延迟执行参数,上游时序库的数据到来可能延迟,建议设置大一些的值做等待来保证计算数据的完整性。
2. SQL运行超过指定次数或指定时间后,这一次的SQL实例会失败并继续下一个实例的调度。

任务管理
在SLS控制台可以查看之前创建的ScheduledSQL作业。

在作业管理页面内,可以查看到每一次执行的实例列表。
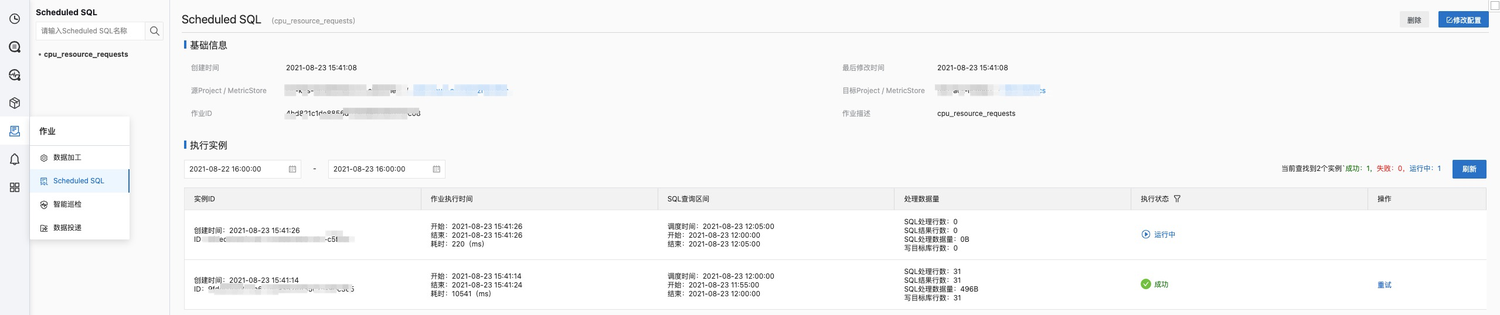
每个实例信息中有 SQL 查询区间,如果任务失败(权限、SQL 语法等原因)或 SQL 处理行数指标为 0(数据迟到或确实没有数据),可以对指定实例做重试运行(失败告警功能开发中)。
效果
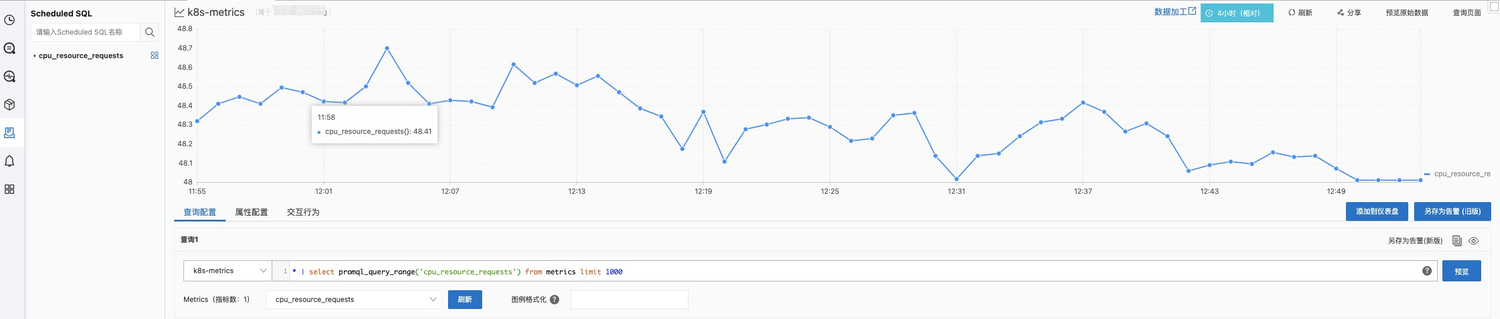
计算完成之后,可以在时序库中查询结果指标。
CPU Request水位
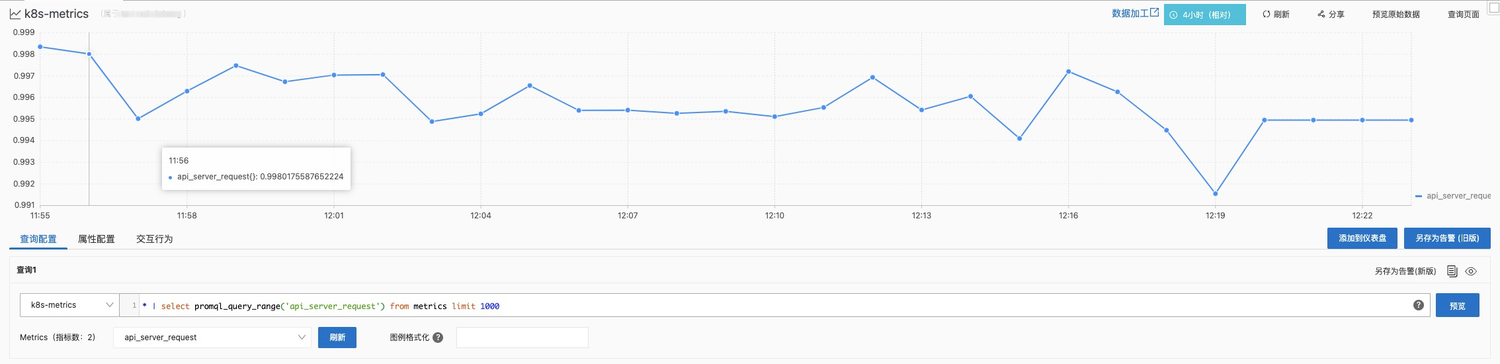
API Server请求成功率
总结
通过SLS提供的ScheduledSQL功能,用户可以轻松聚合时序数据,存入到SLS的时序库中,满足用户监测系统指标的需求。

