

原创 肃马 淘系技术 4月14日

本文根据4月13日淘系技术前端团队出品的「阿里淘系用户体验优化前端实战系列直播」——《跨端体验度量的思考与实现》整理而成。

背景及现状
当今的前端领域,每当我们讨论一个页面的性能好坏与否时,我们所谈及的指标已由传统的 load 、domContentReady 等时间指标转向为讨论首次绘制时间、白屏时间、首屏时间等以用户为中心的度量指标,其各项指标的含义及重要性在此不再赘述。
其如“首次绘制”等内容已经存在 w3c 标准及相应的实现,而首屏时间做为用户体感上最为重要的指标之一却并未出现统一的业界标准及实现方式,公司内部多使用 UC 内核提供的 T2 时间为衡量标准。但在非 Android 端及非 UC 内核场景,则没有相对统一的实现。
据此有部分团队采用其它的替代指标,也另有部分业务团队则各自实现自己的首屏指标的采集方案,此种状况下采集方式及结果标准并不统一。相互之间也无法进行对比,在这种背景下,jstracker做为在淘系内覆盖度最广泛的监控平台,也在前端委员会性能度量统一的方向下进行了首屏时间度量的一系列工作。
基础理论
与其它指标相比,首屏时间在概念上更为抽象,也不存在 FP 或 LCP 等指标所用的“第一次渲染”及“最大渲染面积”这种稳定而明确的判定条件。对于首屏时间我们普遍所接受的仅有“首屏范围内”及“主要内容渲染完成”两个较抽象描述;其中“首屏范围”的概念较为自明,而“主要内容渲染完成”则较难找到明确的边界;
由此首屏时间的计算也产生了一系列不同的判断思路,常见的如通过 DOM 数量增量或渲染面积首屏占比等方案,但受限于不同场景下页面复杂度的不同与实现手段的不同准确率浮动较大,其中基于渲染面积方案相对基于DOM 的数量方案更为普遍的被大家所接受。
但在实际场景中对渲染停止条件的判定也不一致,通常不同业务线在使用中会划定 80%,85%,90% 等比率做为停止条件,导至不同业务甚至不同页面间的统计方式存在差异,除此外页面上的同一区域经常存在多次渲染,不同区块也经常存在“交”与“叠”的问题,由此也较易造成面积计算的失准;
在对数量繁杂的不同种类页面进行比对研究也参考了数个采集方案后,单纯从研发视角去定义“主要内容渲染完成”并找到判断首屏渲染完成规则被认定为一个比较困难的事情,为此而花费时间并非理性。
由此我们需要将视角由开发者视角转换为用户视角,放弃“主要内容渲染完成”这个概念,单纯的去看一个页面的展现过程。对用户可见的页面展现过程,只是一系列元素的涌现,内容的更新,一直到某个时刻页面内容稳定可以进行后续操作的过程,从而我们可以将“主要内容渲染完成”这个问题转换为“首屏范围内视觉稳定”;
问题转化后,我们可以很容易的想像出页面在渲染的时,除非动用一些特殊的控制去影响绘制过程和资源加载顺序,否则整个过程一定是一个由连续的高密度渲染向非连续的低密度渲染的变化过程,在理想情况下,当页面完成渲染完成后,这种变化应该到达“跌零”的状态。
如此我们需要跟踪的即不是绘制面积的占比,也非 DOM 数量的增量变化,而是内容变化导至可见界面变化的动作密度的连续性,当连续的高密度渲染下降到某一个程度时,我们就可以认为“页面稳定”了,这个时间点,即可以理解为用户体感的首屏时间。
▐ 渲染密度计算
在理解这个过程后,我们可以将从页面上监控到的变化过程量化后画在图表上,以便直观的看到高密度变动的整个过程,这里的记录终止条件为数据基本跌零,并持续 3 秒未发生面积占 5% 以上的渲染;受连续性的判断条件影响,此处不把更前面的小范围渲染做为终止条件,具体可见下文中关于连续性的判断条件的部分。
上图为淘宝 PC 首页的首屏渲染过程,X 轴为时间,Y 轴为每次渲染内容的首屏占比,可以看到 3.7 秒左右开始至 3.9s 结束后基本跌到 0 左右;
对比 performance 的渲染记录,我们可以找到 3.9s 左右的实际显示内容为最下面的 5 个按钮入口显示完成;
上图为商品详情页,我们可以找到在 2.8s 左右开始 3.08s 左右结束后基本跌零;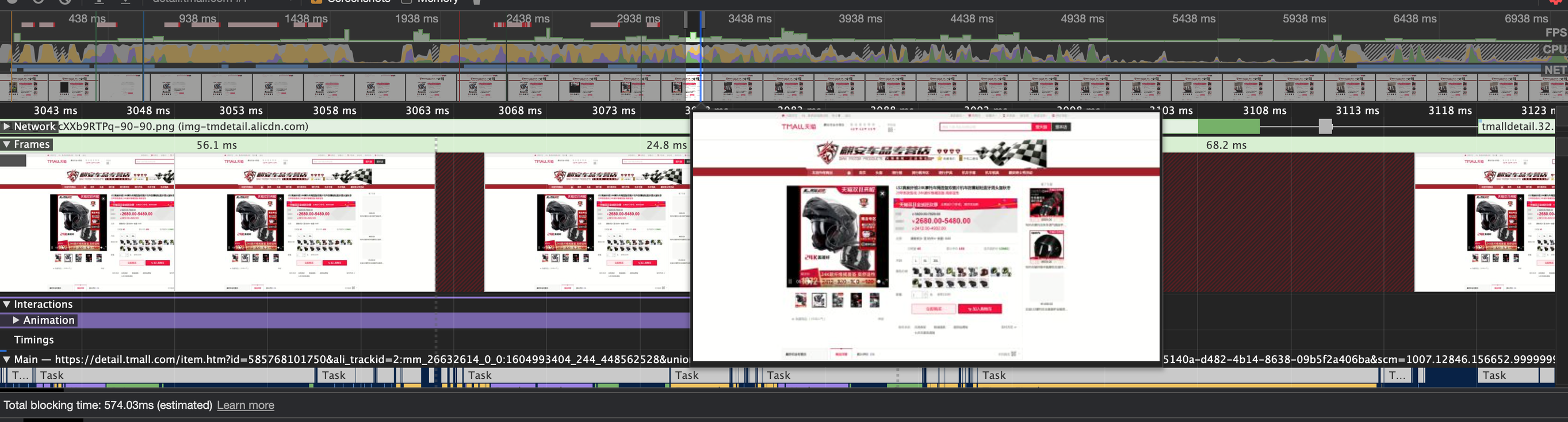
对应 performance 的渲染记录,我们可以看到这里右侧的推荐位置出现并渲染了第一和第二张图片;
H5 类页面,一般没有 PC 渲染层级的多和复杂,相对需要判断的栈较浅, badcase 也较 PC 页面少一些,示例中的 H5 页面首屏时间计算结果为 1.15s,相比 performance 记录略早 30 毫秒左右,是一个比较理想的结果。
▐ 连续性判断
前面的示例中,很重要的一个判断逻辑是对于渲染过程的连续性的判断,这个过程其实并不是以监控到的 DOM 更新的批次进行计算的,那样会导至计算的过程过于零碎,并且经常会捕捉到单纯的由页面中的活动组件如“倒计时组件”,“消息通知”,“轮播组件”等所产生的更新。
这类组件普遍的特征便是会持续的进行或大或小的更新动作,从而使判断逻辑掉入陷阱,而实际的页面监控过程中受到这些活动组件的影响,很多页面并不能完全的跌零,所以我们需要将原本跌零条件设置为只剩稳定的小面积更新时停止;
为了做到以上过程,我的做法是将页面完整的理解为一个整体,仅以监控到的 DOM 更新做为驱动,以200ms 进行聚合计算,200ms 是一个用户体验的经验值,即对于人的感觉来说能把断续动作认知为连贯动作的一个时间间隔;这样一方面使活动组件的更新混进整体页面的更新中,另一方面也减少了计算批次从而降低了计算量,以减少监控脚本本身对页面的影响;
在对每个时间片段进行面积统计及资源耗时的监控的过程中,每个片段会产生一个开始时间和结束时间,开始时间即该片段中最早的 DOM 元素被插入或修改的时间;结束时间即片段内所有 DOM 中用到的图片(含css所使用的图片)载入完成的时间。可以想像一下多个片段所形成的时序图像,如下的图表:
如果把每一格定义为 100ms,浅蓝色是不足 5% 的小面积更新,并定义以下时间的连续性判断条件:
- 被另一个片段包含,
- 起点在另外一个片段结束以前;
- 起点在另一个片段结束200ms以内;
则图片上的时序被划分为几个片段:
- B - L
- P - W
- Y
- AB - AC
- AF - AG
- AJ - AL
- AN - AQ
正向记录的过程并在达到静止条件时回溯,排除掉稳定的小面积更新片段即:AF - AG , AJ - AK , AN - AO,时间点则会到落段 AB - AC,并以 AC 的时间做为最终的首屏时间;
实现过程
以上大致描述了基本的判断原理和基础的条件规则,但实际实现过程中总会有些意外发现,例如:
- CSS 背景图,经常占用很大的视觉面积,但是没办法直接监控到;
- 毫秒级的倒计时,滚动消息等组件,均会产生间隔时间非常短且持续的 DOM 更新;
- 轮播图的非首张图片载入(无论延迟或非延迟);
- 延迟出现的页面辅助类元素,如 H5 页面普遍存在的拉起 APP 的按钮、通告、提醒等;
- 图片 src 替换(灰图,缓存图占位,大体积动图的静态预载图片),看上去视觉稳定但实际并未停止而导至监控时间的大幅延后;
- 页面异常停止,用户交互过早页面跳出,导至完全采集不到或大幅提前。
以上列出的仅是一部分已解决或部分解决的问题。目前为止,已解决的问题所用的方法基本可以描述为排除非关键渲染;另外有些尚未解决的问题和未完全覆盖的场景如:游戏类页面,需长时间载入的 SPA 应用页等尚需要未来去覆盖解决;
▐ 非关键渲染的排除
本质上回溯过程排除结尾的小面积渲染和过滤掉 5% 以下面积的渲染片段,也是排除非关键渲染的方式,但这里所要说的并非这种规则上的排除,而是为了处理上面列举的各种问题而采取的策略性的,基于开发经验的策略。
图片占位图,灰图是页面开发时非常常用的优化手段,但在监控首屏的过程中却造成了麻烦,我们无法知道某一次 src 变化的内容是灰图或实际图片,此类情况在处理时只能凭经验限制 src 的变更次数为 2 次,即一次灰图,后一次为实际图片。
另有一些页面直接利用旧图缓存做为页面内首次展示的内容,实际数据回来后再进行一波更新显示最新内容,对用户来说只是商品内容更新了一次并不是页面未载入完成,除非对页面进行打标,否则我们并不能真正的识别出这类页面,只能依据规则把第二次图片替换的完成时间做为图片的载入完成时间,进而计算资源显示完成时间;
另一类情况是页面中的辅助内容,目前移动端的页面,大部分都有换起 APP 的辅助内容,这类内容一般会在 load 事件后延迟几秒再插入页面,这些内容很可能混入正常的渲染过程被计算到首屏时间内;在另外一些场景,出现在页面上的可能是给用户的通知,浮层等内容,这类内容的尺寸大小,出现时间更为多样,相对于拉起 APP 的按钮更为不可控,在与几个相关业务团队进行沟通后,只能暂时使用排除 fixed 元素的方式粗暴解决,但考虑fixed 元素的一般使用频率和场景,这种方案目前来看并非不能接受;
这里想讨论的第三种情况,则是轮播,这类组件实现方式也更加复杂多样,而特征则更为模糊,如果不从页面的显示结果上看,我们并不能单从 DOM 元素,样式等内容区分这类内容,对此目前使用的方案是与排除滚动区域外元素相同的策略,即向上查找父元素的 overflow 属性,当发现存在 hide 或 scroll 时,则进行相对位置的计算,一但发现超出显示范围的内容则进行排除,如此可忽略大部分轮播造成的影响;
其它的一些状况各有处理方式,但很多都无法做到 100% 识别并完美处理,针对一些万难区别的内容,最终的一条路径就是人为打标,用来指定一些需要忽略的内容;
▐ 优化判断逻辑
对于任何页面上的脚本,“使用”便有“成本”是个不争的事实,无论是网络开销还是执行开销,都对页面性能存在影响,为此我们无法讨论不影响,只能客观的讨论如何更小的影响。
在整体逻辑上看,所有执行动作入口除脚本载入时的初始化动作外,仅有 MutationObserver 回调一处, 以淘宝首页的执行过程为例,根据其回调内容的次数和回调结构统计,每次需判断的量在一百次左右,这样的情况下,整体性能的开销基本在 DOM 的面积统计和位置判断上,约占了总执行量的 90% 以上,但本质上受 MutationObserver 回调以及上文中提到的在连续性判断时所做的量化动作其实已经保证了整个脚本的执行不会集中在一起,所以需要关心的只剩下快速排除不需要计算的内容,实现过程中对于遵循了以下几条原则:
- 隐藏节点,连同子节点一并忽略;
- 节点不在首屏内,则连同子节点一并忽略;
- 面积统计只计算边框最大面积,即直接以取最大位置的方式进行面积统计;
根据上文中的判断逻辑,基本可以较快的排除掉不需要计算的元素。
仍以第一个示例中的淘宝 PC 首页为例,可推断出整段功能的完整生命周期内总的执行时长约为采集到最后一个变更片段的完成时间再加空闲时间,则总时长约为 4.4s + 3s, 即 7.5s - 8s 左右,根据 performance 记录到的执行时长统计,总的执行时间约为 70ms ~ 80ms 左右,基本认为不影响感知;
效果验证
我们在算法的实验阶段借助了 T2 时间进行验证,T2 时间是 UC 内核提供的首屏时间,是在阿里内部被广泛认可的一个指标项,落点准确率可达到90%以上;我们挑选了监控平台中同时采集两个指标的 100 个页面,以同样的极值策略和统计策略进行了长期比对,目前两个指标均值和n50两个统计项的误差各自仅有不到 100ms,近 80% 以上样本误差在 500ms 以下,在非 badcase 的页面上直接对比样本指标值,我们可以看到整体上 JS 的计算结果会略快于内核提供的时间 20ms 左右,我们分析其原因是我们在js中由图片的load事件取得图片载入时间,而内核计算图片解码完成带来的误差。下面的两张图是两个不同页面的指标落点时间比对,sfsp 为 JS 计算的首屏时间,diff 值为 sfsp - t2;


其他
至此,实现首屏时间计算的整个算法过程原理和目前的准确性相关问题相信各位已经有了一个大致的了解,整体的实现并不复杂,只是一个思维方式的转换。更为复杂的问题是:首屏的时间并非只是一个性能监控的时间指标,我们可以认为是我们在页面中有了一个新的生命周期的时间点,基于这个时间点我们可以衍生出更多的体感指标和页面健康度指标,如更合理的网络利用情况,首屏内低效资源的发现等。我希望这个方法能切实的帮助到有需求的各位,也相信这是一个抛砖引玉的过程,各位一定会找到更好的实现方案,优化方法和利用的方式。

