一直以来对CockroachDB(CRDB for short)的设计和实现很感兴趣,最近抽时间研究了下,发现其在技术上还是领先了同类NewSQL产品不少的,个人感觉应该是目前最为先进的类Spanner分布式数据库系统,因此这篇文章会尽可能详细的讨论下其系统的多个方面,重点是事务和一致性相关。
paper中针对的是v.19.2.2版本,不过官方文档中是基于最新的v.21.1.7,两者在描述上有一些冲突的地方,而官方文档中会更为详尽些,因此本文的很多介绍将尽量将paper与官方reference结合,并以reference为准。
介绍
随着时代发展,大型跨国企业的事务型工作负载开始出现跨地理位置的趋势,同时他们也追求对数据放置位置的细粒度控制以及高性能。一般其需求有如下几点:
-
遵循所在地区的数据本地化合规要求,同时尽量保证数据的就近访问以提供高性能
-
为用户提供高可用的服务,容忍哪怕是region级的失效
-
为了简化上层应用的开发,提供SQL的操作接口和可串行化的事务语义
CRDB是面向具有全球级用户的企业或组织,基于云平台提供具有扩展性、高可用性、强一致性和高性能的OLTP事务型数据库。如其名字,其具有很强的容灾和自动恢复能力。为了满足以上提到的用户需求,它提供了以下几个主要功能:
-
容错和高可用: 通过多副本(通常是3-replicas)提供容错能力,通过自动化的快速恢复实现高可用能力
-
跨地理位置的分区策略和副本放置策略: CRDB本身是share-nothing架构,可以自动实现水平扩展,它内部基于一些启发式规则来决定数据的放置方式,用户也可以为数据设置分区方案,并从分区粒度上控制数据的放置位置
-
高性能事务: CRDB的事务协议非常严格且对性能做了大量优化,支持跨分区事务和可串行化的隔离级别并且不依赖任何特殊的硬件,只需要常规服务器和基于软件的时钟同步协议,因此可以做到跨云部署。
-
有先进的query optimizer和query execution engine,此外一个成熟的数据库产品所需要的辅助功能如 online schema change / backup and restore / fast import / JSON support等都有支持。
系统架构
本身是share-nothing的架构,每个node同时提供存储和计算能力。在任一节点内,系统实现了一种分层的架构如下:

-
SQL层
负责查询优化和执行,对下层的读写请求则转换为KV操作,一般情况下,在SQL层看来,下层是一个单体的KV存储(一些情况下会暴露出分布特性)
-
Transaction层
对上层提供事务语义的保证,对到达的KV操作提供隔离性和并发控制等
-
Distribution层
对上层提供一个全局单调递增的key space的抽象,所有的数据包括system data/user data都在这个key space内。CRDB采用了range partition的策略,连续的key range以64MB左右为单位进行切分,每个range也就是复制和迁移的基本数据单元(等同于TiKV中的Region)。
从key到Range的映射在system data中,是一个2层的index,同时在每个节点上都有一份cache,方便快速从key定位对应range。
64MB是一个适当的大小,迁移时不会产生大量快速,同时也可以提供不错的range scan的数据局部性。 和TiKV一样,range会根据size自动做split和merge,同时也可以split来避免热点或存储的不均衡。
-
Replication层
基于Raft完成多副本的共识,每个range构成一个raft group,复制的内容是kv请求执行的结果,基于command形成RSM。
在每个range内,存在一个leaseholder的概念,应该和raft leader是基本等价的,但不同的是leader如果想避免通过raft log做一致性读取,需要实现raft算法中的lease read功能,这个leaseholder就是为了这个功能而存在,只有leaseholder才能进行一致性读,并发起写操作。
在raft协议中,一个raft group中的前后lease间隔必须保证不会重叠,在CRDB中,这一点通过HLC来实现,具体后面请看这篇单独的文章,介绍了CRDB的一致性等问题:
https://ata.alibaba-inc.com/articles/213270
通过多副本CRDB实现了容错能力:
-
如果是短时间失效例如leader突然crash,raft group会自然选举出新leader并持续提供服务,重启后的原leader会rejoin到group中,并变为follower并追上必要的update logs。
-
如果是长时间失效,CRDB可以自动的补全under-replicated的Ranges,而新创建replica的放置策略也可以有多种:
-
手动指定: 对于每个节点可以添加必要的“标签”:系统配置,所在位置等,在创建table时,可以在schema中加入特殊的"region"列,并创建为分区表,这样对不同分区可以映射到不同的region中。
-
自动决定: CRDB内部会基于一系列启发式规则,总体上是保证系统负载的均衡。
-
-
Storage层
实现单node内的本地kV存储,目前使用的是RocksDB。
关于数据的放置策略,paper中具体给出了3种常用策略,基本上都是在性能和容错能力间做trade-off:
-
Geo-Partitioned Replicas
一个partition内的replica的复制不跨region,这样一个range的所有副本都固定在一个region内,这样可以符合数据本地化的合规要求,读写性能也会不错,但无法抵抗region level的失效
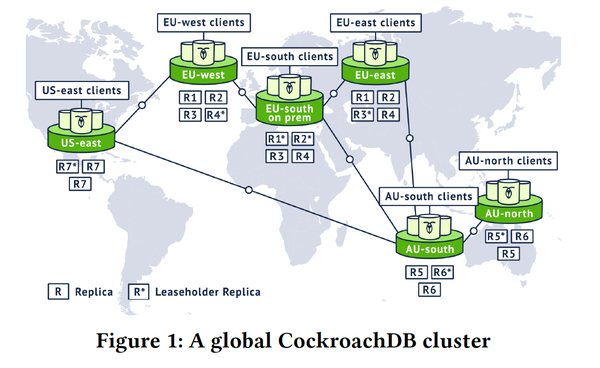
例如上图,同一个region内的所有replica都保留在该region内。
2. Geo-Partitioned Leaseholders
一个partition内的leader都固定在某个region内,但其他replica可以跨range复制,这样可以有不错的local read性能,但需要cross-region write,同时也提供了跨region的容灾能力
3. Duplicated Indexes
在CRDB中,所有的数据都以索引形式来组织,所以和MySQL类似,主表也是基于primary key的聚簇索引。如果读负载比较重,可以将二级索引在多个region间建立多份copy,这样各个region内都可以利用本地index做快速的读取,缺点则是写放大(多份index),因此比较适合数据很少变更的情况。
事务
事务是CRDB中最为亮眼的功能,在跨地域部署的前提下,它依然提供了serializable的最强隔离级别,以及近乎linearizability的线性一致性保障,同时还有不错的性能,可以说是相当牛逼。
首先介绍下CRDB为了事务的延迟和吞吐,做的几个主要的优化:
-
Write Pipelining
每个针对KV的写请求到达range leader时,leader会在本地先做evaluation,确定这个request在数据上会产生怎样的结果,这个结果就是要在多副本间复制的内容,一旦计算完成,就立即向“client”端(gateway node,接收用户请求的节点)返回一个叫做provisional ACK的东西,同时异步执行复制,gateway受到ACK后会发送后续的请求,这样请求的本地执行就和结果的复制并行了起来,形成pipeline。尽可能减少了操作延迟。
当然,gateway node作为事务的coordinator会跟踪所有in-flight(没复制完成)的操作集合。
-
Parallel commit
最直接的方式,当所有in-flight的写操作都复制完成时,coordinator发起commit的提交操作并完成复制,此时事务就算是提交完成了,但这意味着更多的round-trip和更大的延迟。为此CRDB采用了一个比较激进的方案:
当最后一个write操作回复provisional ACK后,coordinator立即发起请求,修改事务状态为staging + [所有pending write集合]。然后进入wait状态等待所有pending write操作都完成,一旦确认都完成就直接向客户端告知事务已提交,然后异步的将事务状态改为committed
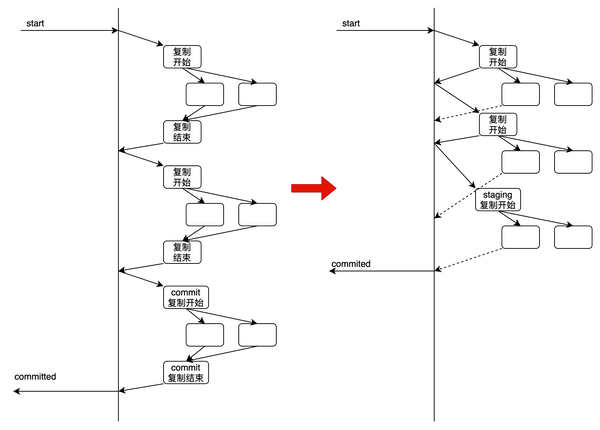
这样来看,实际的write操作和commit操作都形成了流水线,可以很好的减少复制的延迟,理论上如果写足够快,2轮的复制延迟(一轮是所有write操作,一轮是staging状态)内,事务就可以完成提交,当然缺点也很明显,由于staging -> commit的状态是异步修改的,有可能其他并发事务在查看该事务状态是看到的仍是staging,那么需要去确定所有pending的write opertions是否已经完成,如果完成就等同于commit状态。

实际上,通过这种原子性修改事务状态的方式,也实现了分布式事务的原子提交,所有写入数据的可见性也是原子性的switch。
CRDB的事务只支持可串行化的隔离级别,采用了MVTO的并发控制方式,每个事务被分配唯一的时间戳,事务基于时间戳的顺序建立在串行化历史中的先后顺序,也就是说,一个事务所有的读写操作,都在这个时间戳上“原子性瞬时”完成。
关于事务的部分我会更多参考官方文档的介绍,按照架构层次从上到下介绍整体流程:
-
SQL
client的请求首先到达集群中某个node,称为gateway node,它负责SQL的解析优化等,并在execution engine中转换为对于的KV操作,注意这里没有range的概念。
-
Transaction
事务层会在gateway中建立TxnCoordSender,它负责整个事务的执行,TxnCoordSender基于gateway本地的时间戳为事务设置初始ts(既是read ts也是commit ts)。
事务层会把执行层下发的类似put/get的KV请求,打包为BatchRequest,发送到下层。
为了记录事务状态,TxnCoordSender会在事务的第一个write操作所在的range上写入一条额外的记录transaction record。这个记录保持了事务的状态,变化序列是pending -> staging -> committed/aborted。
同时为了维持事务的活跃性,TxnCoordSender会周期性的下发heartbeat到transaction record。
注:
CRDB对于transaction record的处理有一个lazy的优化,即只在必要时才写入事务状态记录,由于这只是个优化,具体细节不再讲解,有兴趣可以参考CRDB documents
-
Distribution
分布层的处理仍然在gateway node上,会建立DistSender,针对上层下发的BatchRequest,利用前面提到的key -> range的二级索引结构将BatchRequest拆解为针对各个range的BatchRequest,然后并行的向所有range的leader下发,如前面所说的write pipeling,一个BatchRequest一旦收到provisional ACK就立即下发下一个。
-
Replication
Range leader在收到request后要依次执行以下操作:
-
检测rw冲突
为了避免rw冲突,需要检查当前的write ts是否小于目标key的最近read ts,如果小于则违反了事务的串行化顺序(晚的读操作已经发生,早的写操作还没有进行),这是不能允许的,这样也就保证了
-
任何已读的历史都不会被更改
-
读总是获取最近的已提交版本。
为了能够检测该冲突,每个range会维护一个timestamp cache,记录每个key的最近read ts。每个对key的读操作都会更新该timestamp cache。同时timestamp cache还负责一件事:记录一个事务的时间戳是否被"push"过,这个后面会介绍。
2. 加读写latch
到latch manager中获取该key的latch,注意latch不是事务锁,只负责规避对同一key的并发操作冲突,操作完成后(复制完成)即可释放,这样保证了一个逻辑对象的读、写操作是依次完成的。
3. 对请求本地执行(evaluate)
无论请求是read/write,都要先到storage layer对并发事务的write intent做冲突检测。
write intent是事务尚未提交的写操作,在事务提交前,它写入的KV中除了正常的MVCC value外,还包含一个pointer,指向该事务的transaction record,这样其他事务可以从write intent获取到事务状态,如果没有该pointer,则认为这是一个普通的多版本value,版本由其commit ts决定。
write intent起到了预写入值 + 独占锁的意义,这里锁是指事务锁,任一时刻只有一个事务能够写入write intent,代表了对数据的最新写入!
假设txnB遇到txnA的write intent,处理流程如下:
txnB读取/写入,遇到A的intent,到transaction record上判断事务的状态:
-
commited,则这已经是一个普通value,帮助消除其pointer信息
-
aborted,忽略该intent并帮助删除
-
pending,需要判断事务活跃性
-
事务已不活跃(与TxnCoordSender的heartbeat没有更新),视为aborted处理
-
事务活跃,这里要看下write intent的时间戳
-
write intent的时间戳小于txnB ts
-
如果是read,这里需要等待,因为read是要保证读取最近已提交数据的,因此如果跳过该intent读取更早版本,可能忽略掉这个本应该看到的提交。
-
如果是write,也需要等待因为无法判断write intent事务最终会以哪个时间戳提交(可能被向后push),如果被push到了一个比txnB的ts更晚的时间戳,则txnB当前本质上是应该执行的,因此要等待来判断会不会出现这种情况。
-
-
write intent的时间戳大于txnB ts
-
如果是read,忽略该intent,读取更早版本数据
-
如果是write,则当前事务abort掉,以更大的时间戳restart
-
-
-
-
staging,先验证事务是否已提交,如果已提交按commited处理,否则按照pending处理
遇到write intent的情况在CRDB中称为transaction conflict,在处理完conflict后,之前遇到的intent将不复存在,看下对非write intent的处理:
-
read
-
读到ts更大的已提交value,跳过
-
读到比ts更小的已提交value,则可以读取
-
如果已提交value的wts和当前事务的read ts有不确定区间的重合(有偏差的HLC时间戳),则无法确定该value是否可见, 向后push读事务的时间戳 到不确定区间之后,然后读取该数据。
这种向后push时间戳的策略实际是对abort -> restart的一种优化,为了保证事务的原子性,在commit ts被push后,要做一个read refresh的操作:
假设commit ts从ts1被推到ts2,需要验证[ts1 -> ts2]时间范围内,之前事务所有已经读取的值,是否发生了变化!这个从直觉上很好理解,如果值发生了变化,在ts1上发生的事务与ts2上发生的事务就不再等价了,那么对于已完成的写操作,为什么不需要验证呢?其实也很简单,因为写入的都是write intent,而intent本身就代表了对key的最新操作,是独占的,不会有其他事务有更新的write intent或者write,因此不必验证。
对于这种由于时间戳的不确定区间而后推事务的情况,read refresh操作是立即进行,验证成功才能继续后续操作。
-
write
前面已经介绍了rw冲突的检测,如果发现write ts比timestamp cache中的最近read ts更大,则没有问题,如果更小,则当前write事务的时间戳要被后推到比read ts更大。
如果遇到的已提交value的ts比当前write ts更小,则没有问题,正常覆盖。
如果已提交value的ts比当前write ts更大或者两者处于不确定区间,则类似wr冲突的情况,当前事务的ts要被后推到大于已提交value的ts。
这里提到的push操作,并不是立即做read refreshing检测的,而是在事务发起commit时完成(为何不立即检测??)
paper中对于事务的协调算法和leader上对操作的处理算法,如下两图所示:
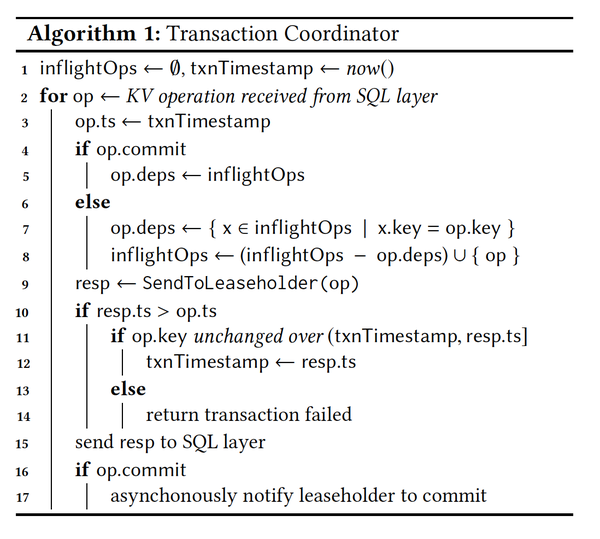
可以看到pipelining write的处理和如果出现push(第10行)的refresh验证

处理流程遵循了上面介绍的get latch -> evaluate -> replicate -> release latch的流程,但没有展开具体evaluate的过程,不过evaluate返回的信息中表明了可能发生时间戳的push。
-
commit
-
首先判断自己是否被abort了(被更高优先级事务abort或者一度不再活跃),如果abort则结束并清理。
-
如果判断自己被push过,则执行read refreshing,成功则继续,否则事务abort并重启。
-
以上两个检查通过后,则进入快速commit流程:
DistSender获取各个BatchRequest的ACK后,会向TxnCoordSender汇总所有的in-flight write操作和所有读操作的结果,TxnCoordSender在向transaction record记录staging状态时,会把in-flight writes同时记录下来。当等待确定所有in-flight write复制完成后,向client返回提交成功。然后异步改变transaction状态为commit,并对write intent做cleanup,清理Pointer使其称为普通的MVCC value。
到此主要的事务处理流程已经介绍完了,总的来看,处理流程是比较标准的,先检测了rw冲突,然后是wr/ww冲突,当并发冲突解决后,再考虑timestamp ordering算法中不允许出现的过晚读/过晚写问题,从而保证各个事务对于一个key的操作是依次串行执行,且物理执行顺序与事务的时间戳保持一致,也就是说,对于单key事务来说,CRDB可以提供线性一致性的最强保证。
时钟同步与一致性模型
关于CRDB的HLC-based时钟机制,以及它所能提供的一致性保证,在单独一篇文章中进行了详细的分析,请参看:
https://ata.alibaba-inc.com/articles/213270
这里就不再赘述了,官方有篇不错的文章也很值得一看:
https://www.cockroachlabs.com/blog/consistency-model/
SQL层
关于SQL层paper中介绍的不多,总的来说,其对外提供了PostgreSQL的方言和通信协议。
-
Query Optimizer
采用了Cascades的优化器框架,并利用DSL定义了一系列的transformation rules,例如:
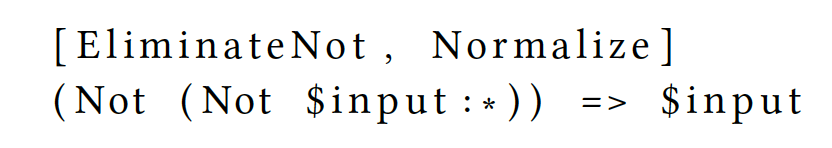
这样一条DSL定义了match pattern 和 replace pattern,描述如果operator tree中的算子满足箭头左侧形式,则可以转换为箭头右侧的形式。CRDB是用go写的,DSL也会编译成go code。
transformation rules分为两类
-
Normalization rules,也就是重写,认为这类转换是一定要执行的,原来的plan tree不再保留,CRDB中目前有290+的Normalization rule
-
Exploration rules,不一定会产生更有计划,例如join ordering,join method等,这种转换会保留原始plan tree,并基于cost选择更优plan,CRDB中目前有29条Exploration rule
实现了统一的search算法,会交错去apply两种rules,直到探索了所有转换。
前面也提到,SQL层一般是不感知下层的分布信息的,看做一个单体的KV store,但在optimize时有一些特殊情况:
有些情况下可以利用schema中的partition信息进行一些特定优化,如:存在idx(region, id),可以静态改写query
SELECT * From t where id = 5;
=>
SELECT * From t where id = 5 AND (region = 'east' or region = 'west');使其可以利用上这个idx。
或者在存在duplicate index时,在考虑不同index副本的访问cost时,考虑其分布信息。
-
Query Planning and Execution
执行有两种模式
-
gateway mode : 所有SQL计算都在gateway节点内完成,这种适合扫描数据量较小的情况,很多TP应用的查询属于这类
-
distributed mode:也就是MPP模式,在这种模式下,会有一个专门的physical planning阶段,将optimizer产生的单机计划,转换为分布式的DAG plan,其中要觉得算子的并行执行方式,以及数据分发方式,类似下图:
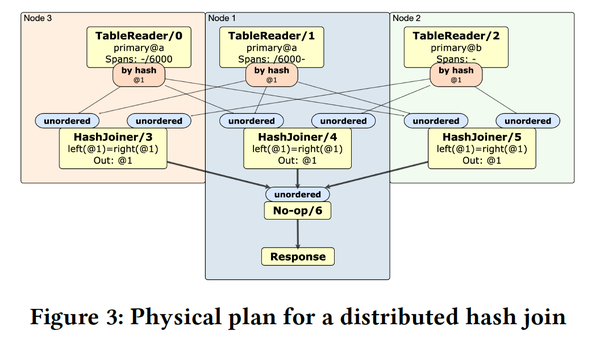
关于CRDB的优化器,youtube上有个不错的视频,是本paper的一作Rebecca Taft在cmu的talk,大家有兴趣可以看下:CockroachDB's Query Optimizer (Rebecca Taft, Cockroach Labs)
在每个data stream的内部,CRDB还支持两种不同的执行模式,根据input cardinality和plan complexity决定:在每个data stream的内部,CRDB还支持两种不同的执行模式,根据input cardinality和plan complexity决定:
-
row-at-a-time,经典的iterator模型,支持所有的SQL算子计算
-
vector-at-a-time,向量化执行模型,支持部分SQL算子,当data从KV中读取出来后,要先转换为column format的vector,流经各算子后,再发送给end user之间转换回行格式,每个算子的实现支持了selection vector的输入。
-
Schema change
CRDB的online schema change参考了F1的方案,具体细节paper中没有讲,可以参考F1的paper,大概来说,每个schema的变更被拆解为一系列的versions,通过控制集群在任一时间点上,任两个node一定处于两个相邻versions之间,则可以允许集群的各个node在不同时间点异步的完成向新schema的转换,同时仍可对外提供服务。
经验总结
从2015年成立以来,CRDB Lab在多年的设计、开发中总结了一系列的经验或者收获,概述如下:
-
Raft Made Live
虽然raft的paper给出了比较明确、详细的实现细节,但工程实践中仍然有很多可以优化的点:
-
将同一个node上所有range leader向follower的heartbeat统一,从而大量减少无数range之间heartbeat带来的网络开销
-
Joint Consensus,raft paper中原始的实现方案在执行group成员变更中有个限制,每次只能增加或移除1个成员,这样就会在过程中存在两种情况:

上面是先做移除,可以看到group内只有2个member,无法保证quorum
下面是先做增加,group内变为了4个member,这是的quorum变为了3,一旦region3失效了,quorum将被打破。
因此两种中间状态都存在可用性问题。
为此CRDB实现了Join Consensus机制,也就是说,在group成员变更时,需要同时满足old / new两种configuration,任何写操作都要同时在两个raft group下达成quorum才能成功。
具体细节可以参考CRDB官网:
https://www.cockroachlabs.com/blog/joint-consensus-raft/
值得一提的是,TiDB5.0的release中,也实现了Joint Consensus。
-
去除Snapshot Isolation
CRDB事务的设计初衷就是基于MVTO的可串行化事务,支持SI对于他们来说开发成本很高,带来的性能收益却没有那么大,因为需要对每个read操作加事务锁(?为啥?),对原有设计破坏的比较厉害,因此他们放弃了对SI的支持。
-
Version Upgrades的坑
在做滚动升级中,有可能一个raft group中的多个node处于不同的软件版本,在早期实现中复制的是request,然后各个replica各自执行evaluate并apply结果,但这样可能导致不同replica得到不同执行结果(不同版本二进制),因此后续改为了先在leader做evaluate,然后复制结果。
-
Follow the workload
CRDB提供这种功能,希望能够让leader自适应的跟随user位置的变化来调整自身的locality,从而始终保持较低的访问延迟,但实践证明这个方案很少被使用,用户决定对于特定负载进行手动的调优并固化下来已经可以达到非常好的效果,而且这种自适应的策略在通用系统中也很难表现良好,经常无法保证性能的可预期性,而这对于用户来说是至关重要的。
总结
在我来看,CRDB在NewSQL的OLTP型数据库系统中已经领先了其他竞品不少,通过大量的激进优化和开发积累,它建立了很多技术优势:
-
比较先进的query optimizer和executor,支持mpp的并行执行方式,单个执行流中也可以执行向量化的执行。
-
先进的事务模型,提供了最为严格的隔离级别和几乎接近完美的一致性模型,同时还能利用大量优化来保证足够好的性能和扩展性,现在看来除了对热点并发事务的处理不够理想外,其扩展性和事务吞吐、延迟都还是很不错的
-
自动维护能力,包括热点打散,负载均衡,自动恢复机制等,减轻了运维负担
-
跨地理位置部署的能力和灵活的数据放置策略
类似的系统如YugabyteDB,TiDB,甚至Kudu,虽然各自实现了其中的一些功能,甚至实现的更好,但综合来看,作为一款分布式大规模OLTP数据库产品,短时间内应该没有哪款产品可以超越。

