背景说明
Principal(主体)是系统中的身份,如hadoop namenode等被赋予身份的人或事物。在Hadoop中,通常为集群中的每个服务和计算机创建不同的主体,例如hdfs/node1、hdfs/node2、...等等。这些主体将用于运行在node1、node2等上的所有HDFS守护程序。
Kerberos用户Principal有两部分组成:username@company.com。只有基于主机的服务主体有3个部分 (额外的部分是运行服务的主机),如principal=hive/cdh-master@COMPANY.COM。
在beeline connect字符串中,您应该始终对要连接的HiveServer2实例使用hive服务主体。另一种选择是使用 _ HOST而不是特定的主机名,该主机名将扩展为正确的主机。
三段式(即基于主机的服务主体)的Principal有几个问题:
- 当重启集群后,需要重新生成keytab文件,导致运维成本和复杂度增加
- 客户出于安全考虑,在生产环境中往往使用的是两段式principal如:
XXX@DATAPHIN.COM。
因此Dataphin从V2.9版本开始支持二段式Principal的配置。以下的配置支持Hadoop计算源以及Hadoop相关的数据源,但仅以Hadoop数据源为例。
配置说明
前置条件:
① 集群已经做好Kerberos相关的配置
② 已经准备好用户Principal的keytab文件
HDFS
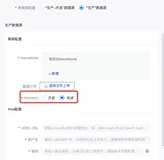
在创建HDFS数据源连接时支持简单模式和Kerberos模式。简单方式在此不再赘述。若需使用二段式Principal进行认证,则
- 开启Kerberos认证
- 使用用户Principal的keytab文件
- 填入用户Principal

Hive
Hive的连接方式目前Dataphin支持三种场景:简单模式,Kerberos(二段式及三段式),ZooKeeper HA模式。对于简单方式使用username和password方式登录,不再赘述。
配置Hive 数据源时,JDBC URL的Principal需要是Server级别的Principal,但是使用用户Principal及其keytab文件如:
jdbc:hive2://cdh-master:2181,cdh-worker01:2181,cdh-worker02:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk;principal=hive/cdh-master@DATAPHIN.COM

Impala
保持与三段式的Kerberos Principal相同,JDBC URL如:
jdbc:impala://cdh-master:21050/default;AuthMech=1;KrbServiceName=impala;KrbRealm=DATAPHIN.COM;KrbHostFQDN=cdh-master
Keytab使用用户Principal的Principal。如下图所示:

HBase
- 连接地址:hbase.zookeeper.quorum的地址,如:cdh-worker02:2181,cdh-master:2181,cdh-worker01:2181
- 配置文件:可选上传hbase-site.xml
- Kerberos:设置为开启
- KDC Server:输入KDC的地址或切换为krb5文件
- KeytabFile:上传用户的Keytab文件,可用kinit生成
- Principal:设置用户Principal