

前言
本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。
此外,阿里云和 Apache Spark 及 Delta Lake 的原厂 Databricks 引擎团队合作,推出了基于阿里云的企业版全托管 Spark 产品——Databricks 数据洞察,该产品原生集成企业版 Delta Engine 引擎,无需额外配置,提供高性能计算能力。有兴趣的同学可以搜索` Databricks 数据洞察`或`阿里云 Databricks `进入官网,或者直接访问 https://www.aliyun.com/product/bigdata/spark了解详情。
译者:韩宗泽(棕泽),阿里云计算平台事业部技术专家,负责开源大数据生态企业团队的研发工作。

Delta Lake技术系列 - 湖仓一体(Lakehouse)
——整合数据湖和数据仓库的最佳优势

目录
- Chapter-01 什么是湖仓一体?
- Chapter-02 深入探讨 Lakehouse 和 Delta Lake 的内部工作原理
- Chapter-03 探究 Delta Engine
本文介绍内容
Delta Lake 系列电子书由 Databricks 出版,阿里云计算平台事业部大数据生态企业团队翻译,旨在帮助领导者和实践者了解 Delta Lake 的全部功能以及它所处的场景。在本文中,Delta Lake 系列-湖仓一体( Lakehouse ),重点介绍湖仓一体。
后续
读完本文后,您不仅可以了解 Delta Lake 提供了什么特性,还可以理解这些特性是如何带来实质性的性能改进的。

什么是数据湖?
Delta Lake是一个统一的数据管理系统,可为云数据湖带来数据可靠性和快速分析能力。Delta Lake 可以在现有数据湖之上运行,并且与 Apache Spark API 完全兼容。
在Databricks 公司内部,我们已经看到了 Delta Lake 如何为数据湖带来可靠性保证,性能优化和生命周期管理。 使用 Delta Lake 可以解决以下问题:数据格式错误,数据合规性删除或对个别数据进行修改。同时,借助 Delta Lake,高质量数据可以快速写入数据湖,通过云服务(安全且可扩展)部署以提高数据的利用效率。

Chapter-01 什么是湖仓一体?

在过去的几年里,Lakehouse 作为一种新的数据管理范式,已独立出现在 Databricks的许多用户和应用案例中。在这篇文章中,我们将阐述这种新范式以及它相对于之前方案的优势。
数据仓库在决策支持和商业智能应用程序方面拥有悠久的历史。 自1980年代末创建以来,数据仓库技术一直在发展,MPP 架构使得系统能够处理更大规模的数据量。
尽管仓库非常适合结构化数据,但是许多现代企业必须处理非结构化数据,半结构化数据以及具有高多样性、高速度和高容量的数据。数据仓库不适用于许多此类场景,并且成本效益并非最佳。
随着公司开始从许多不同的来源收集大量数据,架构师们开始构想一个单一的系统来容纳许多不同的分析产品和工作任务产生的数据。
大约十年前,我们开始建立数据湖——一种多种格式的原始数据的存储数据库。数据湖虽然适合存储数据,但缺少一些关键功能:它们不支持事务处理,不保证数据质量,并且缺乏一致性/隔离性,从而几乎无法实现混合追加和读取数据,以及完成批处理和流式作业。 由于这些原因,数据湖的许多功能尚未实现,并且在很多时候丧失了数据湖的优势。
很多公司对各类数据应用包括 SQL 分析、实时监控、数据科学和机器学习的灵活性、高性能系统的需求并未减少。AI 的大部分最新进展是基于更好地处理非结构化数据(如 text、images、video、audio )的模型,但这些恰恰是数据仓库未针对优化的数据类型。一种常见的解决方案是使用融合数据湖、多个数据仓库以及其他的如流、时间序列、图和图像数据库的系统。但是,维护这一整套系统是非常复杂的(维护成本相对较高)。此外,数据专业人员通常需要跨系统进行数据的移动或复制,这又会导致一定的延迟。
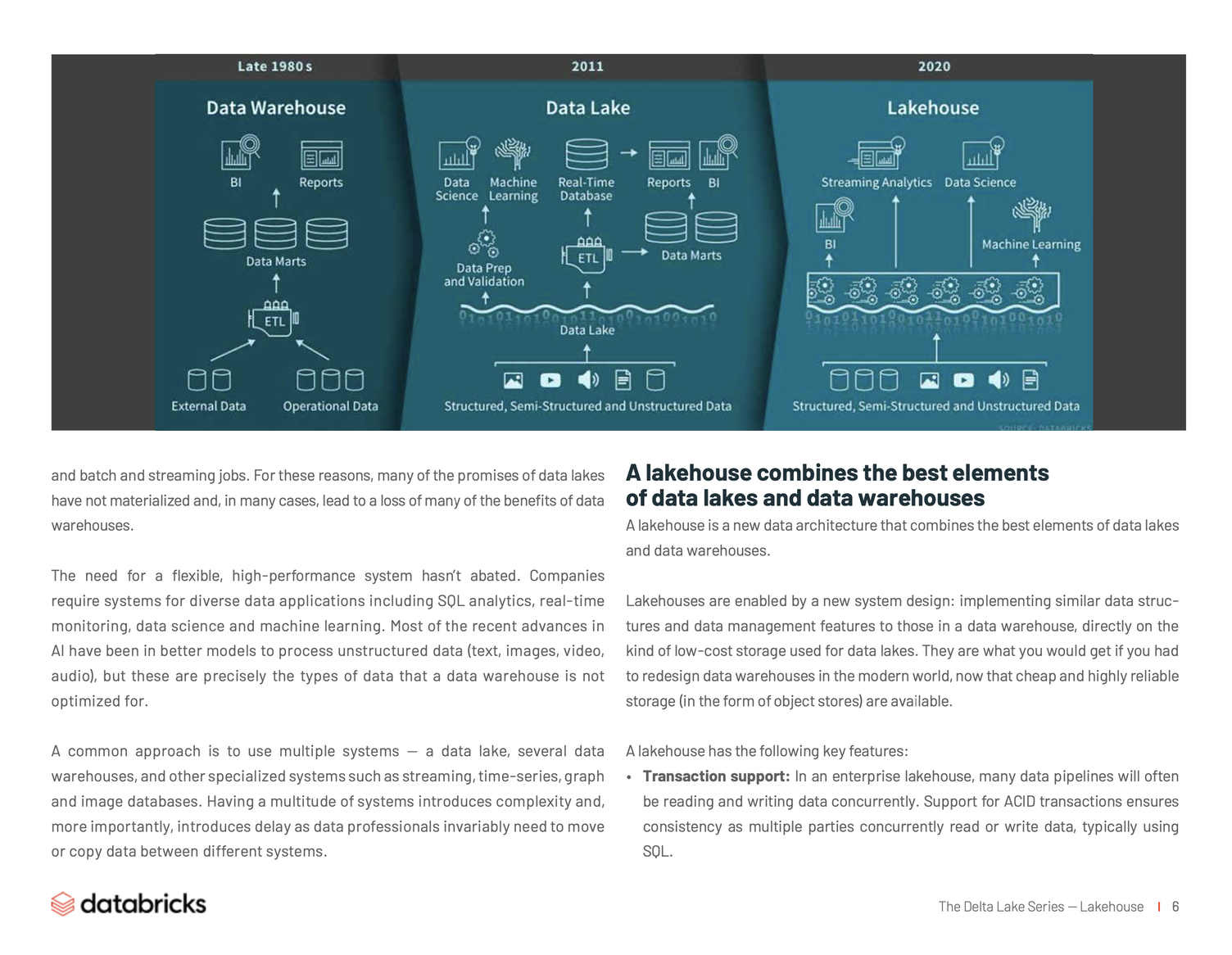
湖仓一体整合了数据湖和数据仓库二者的优势
Lakehouse 是一种结合了数据湖和数据仓库优势的新范式,解决了数据湖的局限性。Lakehouse 使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果你现在需要重新设计数据仓库,现在有了廉价且高可靠(以对象存储的格式)的存储可用,不妨考虑使用 Lakehouse。

Lakehouse有如下关键特性:
- 事务支持:Lakehouse 在企业级应用中,许多数据管道通常会同时读取和写入数据。通常多方同时使用 SQL 读取或写入数据,Lakehouse 保证支持ACID事务的一致性。
- 模式实施和治理:Lakehouse 应该有一种支持模式实施和演变的方法,支持 DW 模式规范,例如 star /snowflake-schemas。该系统应该能够推理数据完整性,并且应该具有健壮的治理和审核机制。
- BI支持:Lakehouse 可以直接在源数据上使用BI工具。这样可以减少陈旧度和等待时间,提高新近度,并且降低必须在数据湖和仓库中操作两个数据副本的成本。
- 存储与计算分离:事实上,这意味着存储和计算使用单独的群集,因此这些系统能够扩展到更多并发用户和更大数据量。 一些现代数据仓库也具有这种属性。
- 兼容性:Lakehouse 使用的存储格式是开放式和标准化的,例如 Parquet,并且它提供了多种 API,包括机器学习和 Python/R 库,因此各种工具和引擎都可以直接有效地访问数据。
- 支持从非结构化数据到结构化数据的多种数据类型:Lakehouse 可用于存储,优化,分析和访问许多新数据应用程序所需的数据类型,包括图像,视频,音频,半结构化数据和文本。
- 支持各种工作场景:包括数据科学,机器学习和 SQL 分析。这些可能依赖于多种工具来支持的工作场景,它们都依赖于相同的数据存储库。
- 端到端流式任务:实时报告是许多企业的日常需要。对流处理的支持消除了对专门服务于实时数据应用程序的单独系统的需求。
这些是 Lakehouse 的关键特征。企业级系统需要更多功能。安全和访问控制工具是基本需求。尤其是根据最近的隐私法规,包括审核,保留和沿袭在内的数据治理功能已变得至关重要,诸如数据目录和数据使用量度等数据发现工具也需要被启用。使用Lakehouse,上述企业特点只需要在单套系统中被部署、测试和管理。

阅读以下研究 Delta Lake:基于云对象存储的高性能 ACID 表存储
摘要:
云对象存储(例如阿里云 OSS)是一些现有的最大、最具成本效益的存储系统,它是存储大型数据仓库和数据湖的主要选择。具有局限性的是,它们作为键值存储的实现方式使其很难实现 ACID 事务和高性能,因为元数据操作(例如列出对象)非常昂贵,并且一致性保证受到限制。在本文中,我们介绍了 Delta Lake,这是最初由Databricks 开发的基于云对象存储的开源 ACID 表存储层。 Delta Lake 使用 Apache Parquet 压缩格式的事务日志来为大型表格数据集提供 ACID 属性,时间旅行和快速的元数据操作(例如,能够快速在数十亿个分区中搜索查询)。它还利用此设计来提供高级功能,例如自动数据布局优化、更新、缓存和审核日志。我们可以从 Apache Spark,Hive,Presto,Redshift 和其他系统访问 Delta Lake 表。Delta Lake 部署在数以千计的 Databricks 客户中,这些客户每天处理 EB 级数据,最大的实例管理 EB 级数据集和数十亿个对象。
作者:Michael Armbrust, Tathagata Das, Liwen Sun, Burak Yavuz, Shixiong Zhu, Mukul Murthy, Joseph Torres, Herman van HÖvell, Adrian Ionescu, Alicja Łuszczak, Michał Szafra ń ski, Xiao Li, Takuya Ueshin, Mostafa Mokhtar, Peter Boncz, Ali Ghodsi, Sameer Paranjpye, Pieter Senster, Reynold Xin, Matei Zaharia
原文Inner workings of the lakehouse.

早期案例
Databricks 统一数据平台在架构上支持 lakehouse。阿里巴巴的 DDI 服务,已经与Databricks 集成,实现了类似 Lakehouse 的模式。其他托管服务(例如 BigQuery 和Redshift Spectrum)具有上面列出的一些 LakeHouse 功能特性,但它们是主要针对 BI和其他 SQL 应用。对于想要构建和实现自己系统的公司,可参考适合构建 Lakehouse的开源文件格式( Delta Lake,Apache Iceberg,Apache Hudi )。
将数据湖和数据仓库合并到一个系统中意味着数据团队可以更快地移动数据,因为他们能够使用数据而无需访问多个系统。在这些早期的 Lakehouse中,SQL 支持以及与BI 工具的集成通常足以满足大多数企业数据仓库的需求。实例化视图和存储过程是可以使用的,但是用户可能需要采用其他机制,这些机制与传统数据仓库中的机制不同。后者对于“升降场景”尤为重要,“升降场景”要求系统所具有的语义与旧的商业数据仓库的语义几乎相同。
对其他类型的数据应用程序的支持是怎样的呢? Lakehouse 的用户可以使用各种标准工具( Apache Spark,Python,R,机器学习库)来处理非 BI 工作,例如数据科学和机器学习。 数据探索和完善是许多分析和数据科学应用程序的标准。Delta Lake 旨在让用户逐步改善 Lakehouse 中的数据质量,直到可以使用为止。
尽管可以将分布式文件系统用于存储层,但对象存储更适用于 Lakehouse。对象存储提供了低成本,高可用性的存储,在大规模并行读取方面表现出色,这是现代数据仓库的基本要求。
从BI到AI
Lakehouse 是一种新的数据管理体系结构,在机器学习覆盖各行各业的时代,它可以从根本上简化企业数据基础架构并加速创新。过去,公司产品或决策中涉及的大多数数据都是来自操作系统的结构化数据。而如今,许多产品都以计算机视觉和语音模型,文本挖掘等形式集成了AI。 为什么要使用 Lakehouse 而不是数据湖来进行AI? Lakehouse 可为您提供数据版本控制、治理、安全性和 ACID 属性,即使对于非结构化数据也是如此。
当前 Lakehouse 降低了成本,但是它们的性能仍然落后于实际投入和部署多年的专用系统(例如数据仓库)。用户可能会偏爱某些工具( BI工具,IDE,notebook ),因此 Lakehouse 还需要改进其 UX 以及与流行工具的连接器来吸引更多用户。随着技术的不断成熟和发展,这些问题都将得到解决。 随着技术进步,Lakehouse 将缩小这些差距,并且同时保留更简单,更具成本效益和更能服务于各种数据应用程序的核心属性。

Chapter02 深入探讨 Lakehouse 和 Delta Lake 的内部工作原理
Databricks 写了一篇博客,概述了越来越多的企业采用 Lakehouse 模式。该博客引起了技术爱好者的极大兴趣。尽管许多人称赞它为下一代数据体系结构,但有些人认为湖仓一体与数据湖是一回事。最近,我们的几位工程师和创始人写了一篇研究论文,描述了使湖仓一体架构与数据湖区分开的一些核心技术挑战和解决方案,该论文已在The International Conference on Very Large Databases (VLDB) 2020接受并发表,“Delta Lake: High-Performance ACID Table Storage Over Cloud Object Stores”。
十多年前,云为数据存储开辟了新的发展方向。像 Amazon S3 这样的云对象存储已成为世界上一些最大,最具成本效益的存储系统,这使它们成为更有吸引力的数据存储仓库和数据湖平台。但是,它们作为键值存储的性质使得许多公司所需的 ACID 事物特性变得困难。而且,昂贵的元数据操作(例如列出对象)和受限的一致性保证也影响了性能。

基于云对象存储的特点,出现了三种方案:
Data lakes (数据湖)
Data lakes 将表存储为对象集合的文件目录(即数据湖),通常使用列式(例如Apache Parquet )存储。 这是一种独特的方法。因为表只是一组对象,可以通过多种工具进行访问,而无需使用其他数据存储系统,但是这样会导致性能和一致性问题。 性能上由于事务执行失败导致隐藏的数据损坏的情况时有发生,最终导致查询不一致,等待时间长,并且基本的管理功能(如表版本控制和审核日志)不可用。
Custom storage engines (自定义存储引擎)
第二种方法是定制存储引擎,例如为云构建的专有系统,如 Snowflake 数据仓库。 这些系统可以提供单一的数据源,通过在独立且高度一致的服务中管理元数据,从而可以避免数据湖的一致性挑战。 但是,所有 I/O 操作都需要连接到此元数据服务,这可能会增加云资源成本并降低性能和可用性。 此外,要实现现有计算引擎(例如 Apache Spark,Tensorflow 和 Pytorch )的连接器还需要进行大量工程化工作,这对于使用各种计算引擎的数据处理团队而言可能是一个挑战。非结构化数据会加剧工程上的挑战,因为这些系统通常针对传统的结构化数据类型进行了优化。最令人不能接受的是,专有元数据服务将客户锁定在特定的服务提供商中,如果客户将来决定采用新服务,他们将不得不面对始终高昂的价格和费时的迁移成本。

Lakehouse (湖仓一体)
Delta Lake 是一种云对象存储之上的开源 ACID 表存储层。好比我们寻求建造一辆汽车,而不是寻找更快的马。湖仓一体是一种新架构,结合了数据湖和数据仓库的优势。它不仅拥有更好的数据存储性能,而且在存储和使用数据的方式上发生了根本性的变化。新的系统设计支持 Lakehouse:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果您想要设计新的存储引擎,那么这种价格低廉且可靠性高的存储(以对象存储的形式)就是您所想要的。
Delta Lake 使用压缩到 Parquet 中的预写日志,以 ACID 方式维护数据表的部分对象信息,该日志也会存储在云对象存储中。这种设计允许客户端一次更新多个对象,以可串行化的方式用另一个对象替换对象的一个子集,从而可以获得很高的并行读/写性能。该日志还为大型表格数据集提供了显着更快的元数据操作。
Delta Lake 还提供了:时间旅行(数据版本控制支持回滚),自动优化小文件,更新支持,缓存和审核日志。这些功能共同提高了在云对象存储中处理数据的可管理性和性能,最终为 Lakehouse 架构打开了大门。该架构结合了数据仓库和数据湖的关键功能,创建了更好,更简单的数据架构。

如今,Delta Lake 已被成千上万的 Databricks 客户以及开源社区中的许多组织所使用,每天处理数十亿字节的结构化和非结构化数据。这些用例涵盖了各种数据源和应用程序。存储的数据类型包括来自企业OLTP系统的更改数据捕获( CDC )日志,应用程序日志,时间序列数据,图形,用于报告的聚合表以及用于机器学习的图像或特征数据。这些应用程序包括 SQL 分析工作(最常见),商业智能化,流处理,数据科学,机器学习和图形分析。总体而言,Delta Lake已证明它非常适合大多数使用结构化存储格式(例如 Parquet 或 ORC )和许多传统数据仓库工作负载的数据湖应用程序。
在这些用例中,我们发现客户经常使用 Delta Lake 来大幅简化其数据架构,他们直接针对云对象存储运行更多工作负载。更多时候,他们通过创建具有数据湖和事务功能的 Lakehouse 来替换消息队列(例如 Apache Kafka ),数据湖或云数据仓库(例如 Snowflake,Amazon Redshift )提供的部分或全部功能。
在上述这篇文章的研究中,作者还提供了以下介绍:
• 对象存储的特征和挑战
• Delta Lake 的存储格式和访问协议
• Delta Lake 目前的特征,优势和局限性
• 当下常用的核心用例和专用用例
• 性能实验,包括 TPC-DS 性能
通过本文,您将更好地了解 Delta Lake,以及它如何为低成本云存储中的数据启用类似于 DBMS 的性能和管理功能。您还将了解到 Delta Lake 的存储格式和访问协议是如何帮助它变得易于操作,高可用并能够提供对象存储的高带宽访问。

Chapter03 探究 Delta Engine

Delta 引擎将与 Apache Spark 100%兼容的矢量化查询引擎联系在一起,通过利用现代CPU体系结构对 Spark 3.0的查询优化器和缓存功能进行了优化,这些功能是作为Databricks Runtime 7.0的一部分推出的。这些功能加在一起,可以显着提高数据湖(尤其是由 Delta Lake支持的数据湖)上的查询性能,从而使客户可以更轻松地采用和扩展 Lakehouse 体系结构。
扩展执行性能
过去几年中最大的硬件变化趋势之一是 CPU 时钟速度已趋于平稳。 其具体原因不在本章的讨论范围之内,但重要的是,我们必须找到新的方法来以超出原始计算能力的速度去更快地处理数据。 一个最有效的方法是提高可以并行处理的数据量。 但是,数据处理引擎需要专门设计以利用这种并行性。
此外,随着业务步伐的加快,留给研发团队提供良好的数据建模的时间越来越少。为了更好的业务敏捷性而进行的较差的建模会导致较差的查询性能。因此,这不是理想的状态,我们希望找到使敏捷性和性能最大化的方法。

提出高查询性能的 Delta Engine
Delta Engine 通过三个组件来提高 Delta Lake 的 SQL 和 DataFrame 工作负载的性能:一个改良好的查询优化器,一个位于执行层和云对象存储之间的缓存层,一个用C++ 编写的本机矢量执行引擎。
改进的查询优化器通过更优化的统计信息扩展了 Spark 3.0中已有的功能(基于成本的优化器,自适应查询执行和动态运行时过滤器),从而使星型架构工作负载的性能提高了18倍。
Delta Engine 的缓存层会自动选择要为用户缓存的输入数据,并以更高效的 CPU 格式对代码进行转码,从而更好地利用NVMe SSD的更高存储速度。几乎所有工作负载的扫描性能最高可提高5倍。
事实上,Delta Engine 的最大创新点是本地执行引擎,它解决了当今数据团队所面临的挑战,我们将其称为 Photon(众所周知,它是一个引擎中的引擎)。这个完全重构的 Databricks 执行引擎的构建旨在最大限度地提高现代云硬件中新变化带来的性能。它为所有工作负载类型带来了性能改进,同时仍与开源 Spark API 完全兼容。

Delta Engine 入门
通过将这三个组件链接在一起,客户将更容易理解 Databricks 是如何将多个部分的代码聚合在一起进行改进,从而大大提高在数据湖上进行分析的工作负载的性能。
我们对 Delta Engine 为客户带来的价值感到兴奋。它在时间和成本的节约方面具有很大价值。更重要的是在 Lakehouse 模式中,它支持数据团队设计数据体系结构以提高统一性和简化性,并取得很多新进展。
有关 Delta Engine 详情,请观看 Spark + AI Summit 2020上的主题演讲:Delta Engine: High-Performance Query Engine for Delta Lake。

后续
您已经了解了 Delta Lake 及其特性,以及如何进行性能优化,本系列还包括其他内容:
- Delta Lake 技术系列-基础和性能
- Delta Lake 技术系列-特性
- Delta Lake 技术系列-Streaming
- Delta Lake 技术系列-客户用例(Use Case)
获取更详细的 Databricks 数据洞察相关信息,可至产品详情页查看:
https://www.aliyun.com/product/bigdata/spark
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,技术专家直播,只为营造纯粹的 Spark 氛围,欢迎关注公众号!
扫描下方二维码入 Databricks 数据洞察产品交流钉钉群一起参与交流讨论!


