本篇内容
分享人: 慕明 阿里云智能 技术专家
视频地址:https://yqh.aliyun.com/live/detail/21708
本篇主要通过五个部分介绍MaxCompute Tunnel
- MaxCompute Tunnel技术原理
- MaxCompute Tunnel丰富的生态
- Tunnel功能简介
- SDK的使用方式
- 最佳实践
一、MaxCompute Tunnel技术原理

MaxComputeTunnel-技术原理
产品定位
Flink
DataWorks
DataHub
ODPSCMD
MaxComputeAPI层组件
SDK
控制流
数据流
数据通道服务
Frontend集群
Tunnel集群
API层
基础功能
MC对外数据读写的唯一接口
计算集群
执行层
控制集群
完善的权限校验及格式检查
高性能存储层直接读写
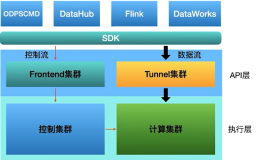
上图是架构图,可以看到对外的服务提供了一个统一的SDK,然后集成到所有的外部服务里。在服务端,提供的服务可以大概分为API层和执行层。API层有两个集群 Frontend集群会负责控制流的介入,Tunnel集群负责数据。在执行层分为控制集群和计算集群,控制集群会负责资源管控,meta的管理,和权限管理这些功能,计算集群就负责实际的计算和存储。
可以看到,Tunnel是属于API层的一个组件,专门负责数据的上传和下载。为什么这么做, 是因为这是一个大数据的系统,所以在MaxCompute上跑一个SQL其实就发了一条控制指令。由于目标的场景是一个大数据量的查询,比如说十亿条这种量级的,这是一个规模比较大的操作,如果在这个场景下想做数据的同步,就不能像MySQL传统输入一样通过insert into,因为insert into走控制集群这个链路是非常浪费资源的,同时也会有一些限制。一次一行的效率特别低,因此设计了分开的控制流和数据流。
Tunnel集群负责的功能是在SDK层提供了Tunnel的API,让用户可以通过一个结构化的方式去访问数据。另外,Tunnel是对外放出来的唯一的数据接口,会对用户写进来的数据做格式检查和权限校验,控制数据安全。同时会保证用户通过Tunnel写出来的数据用SQL可读,不用担心比如SQL读不了写进来的数据,或者写的数据和SQL读出来的值有差异。
另外一点,Tunnel是直接访问存储层的,MaxCompute在底层的存储是一个分布式文件系统,Tunnel是直接访问这个文件系统的,这样在性能上就有了保证。也就是说,Tunnel在理想情况下是可以保证单并发达到10兆每秒的吞吐能力,通过假并发也是可以水平扩展整个吞吐能力。
二、MaxCompute Tunnel丰富的生态
MaxCompute有非常丰富的生态,推荐首先要看一下有什么工具,或者有哪些服务可以做,建议优先使用一些成熟的服务,尽量不要自己先写代码。

丰富的生态
MaxComputeTunnel
SDK
MaxCompute
KAFKA
SLS
JavaSDK,链接
DataHub
Compute
Cluster
PythonSDK,链接
BLINK
SPARK
工具
Compute
Tunnel
Cluster
DataWorks
DTS
MC客户端,链接
Compute
MaxComputeStudio,链接
Cluster
UserApplication
MMA2.0迁移工具,链接
官方的SDK有Java SDK和Python SDK。
另外,官方还提供了三种工具。MaxCompute客户端是一个命令行工具,在数据同步这方面支持用户把一个本地文件上传到MaxCompute里面,也可以通过下载一张表到一个本地文件上。MaxCompute Studio是一个idea插件,它也支持文件上传下载这样的方式。MMA2.0迁移工具是最近推出的一个工具,可以帮助用户把数据从现有的大数据系统里迁移到MaxCompute上,这些工具都是基于SDK开发的,都是通过SDK传输。
除了工具以外,MaxCompute在第三方服务上也是集成的,比如云上的数据通道图,SLS(阿里云的日志服务),DataHub(数据通道),他们都是原生就支持MaxCompute投递的,Kafka也是有官方的插件。
流计算方面,Blink,Spark也都是有MaxCompute同步插件的。数据同步服务方面,DataWorks的数据同步,实时同步和离线同步,都是支持MaxCompute同步的。
总结一下,如果有数据同步的需求,最好先看一下现有的服务是不是可以满足需求。如果觉得都满足不了,想要自己开发的话,可以看一下SDK是可以有哪些功能,和使用上的一些注意事项。
三、Tunnel功能简介

MaxComputeTunnel-功能简介
批量下载
流式上传
批量上传
批量数据通道,链接
支持
支持
支持
Table
批量上传
HashClustered
支持
规划中
不支持
Table
批量下载
RangeClustered
支持
不支持
不支持
Table
流式数据通道,链接
Transactional
支持
支持
规划中
Table
流式上传
查询结果
支持
上图是Tunnel总体功能的表格。现在有两套API,分批量数据通道和流式数据通道。
批量数据通道目标的场景单并发的吞吐量很大,这种理想的场景是传量大的数据,一次一批,QPS和并发都不能特别高,但是单并发的吞吐量可以做得很大,这个在API上也有一些优化。
流式数据通道是新提供的一种服务,因为现在的上游服务大多数都是一些流式服务灌进来的,也就是说单并发可能流量没有那么大,但是都是比较细碎的数据,这种情况如果用批量数据通道会遇到很多限制。最明显的就是小文件问题,用批量数据通道写特别碎的数据进来会产生大量的碎片文件,跑SQL查询就会非常慢,用Tunnel下载也会非常慢。针对这种场景平台提供了流式数据通道服务,通过流式数据上来可以写得特别碎,一行写一次也可以,不需要担心小文件的问题,也不用担心并发的问题,并发可以无限多。流式数据通道是不限并发的,但是批量是限并发的。
从表格中可以看到,通过Tunnel是可以访问这几种资源的:普通表,Hash Clustered表,Range Clustered表和Transactional表,最后是查询结果,这些都是可以下载的;普通表两种上传都支持;Hash Clustered表和Range Clustered表并不适合Tunnel去写,因为数据在存储上需要做一个系统,而且会排序,而Tunnel集群规模没有计算机集群那么大,没有这个能力去做排序。因此,这种表一般经典的用法就是先写一张普通表,然后通过SQL做一个insert overwrite,生成一张Hash Clustered表或者Range Clustered表。
流式上传在架构上做了升级,有一个异步处理的机制,会把用户写进来的数据在后台进行加工,所以后面会支持Hash Clustered表。
Transactional表是说,MaxCompute的普通表是不支持update或者delete的,系统最近在SQL上支持了这个语法,就是用户可以update,也可以delete,也可以支持transaction。批量上传的API现在是支持Transactional表,但是只支持append,也称为insert into,它是不能从Tunnel的API上去update的。流式的也正在规划中,后续可能会连update也一起完成。批量的可能不会做update这个功能,但是批量的现在就可以append这种Transactional表。
查询结果就是说,如果跑一个SQL,在odpscmd客户端或者DataWorks上对查询结果有1万条的限制。但是这个查询结果可以通过Tunnel下载,就不受条数限制,可以下载完整的查询结果到本地。
总而言之,如果使用SDK的话,就可以做到表格里的这些功能。
四、SDK的使用方式
1)基本配置

MaxComputeTunnel-基础配置
pubuicstaticvoidmain(stringargs)
账号信息
出出85BSS3SS8GBSREE
ACCOUNTSCCOUNTNEALIYUNACCOUNTCACCESSDCESSKEY;
AccessID
odpsodpsneodps(account):
ODPS域名
OdPsSeTEndpoint(odpsEndpoint)
odps.setDefaultProjectCoroject):
可支持跨project访问控制
tryf
AccessKey
TABLETUNNeLtUnneLneWTabLeTunneiCodps);
Tunnel域名,可选参数
tunneL.Setendpoint(tunneLEndpoint);
PartitionSpecartitionpnar
enPartitionpeart
Tabterume.streauploausesioplo
odpsEndpoint,链接
table,partitionSpec);
TabLeSchenaschenauploadsessiongetschem
TABLETUNNELSERECORPACkPACkUPLOAdSerPackO;
RECORDRECORDUPLOADSESSIONNEWRECORDO
Tunnelendpoint,链接
For(Int1schema.gecounO
hiteCpuck.setoatastz0crc
pack.append(record):
可选参数(自动路由)
pack.flushO:
Systeaout.printin(upLoadsuccess");
Ch(TUnneLExceptione)
e.printstackTraceO;
catcH(IOExCEPTIone)
DefaultProject
printstackTraceO:
如果想开发的话有哪些东西需要配置,不管上传、下载,还是流式上传,这些配置都是一样的。首先需要创建一个ODPS对象和一个Table Tunnel对象。如果想用SDK跑SQL,要创建ODPS;TableTunnel是Tunnel入口的一个类,所有的功能都是从这个类发起的。
然后看具体的配置项,图中左侧列举的是比较关键的几个。Access ID和Access Key就是账号信息,阿里云通过这个来表示一个账号。
ODPS Endpoint是服务的一个入口,现在在公共云上应该有21个region,包括金融云和政务云,中国有7个,海外有14个。每个region的endpoint是不一样的,使用时需要找到自己购买的region服务,并正确填写endpoint进去。
Tunnel Endpoint是可选的,如果不填,系统会通过所填的ODPS endpoint自动路由到对应的Tunnel endpoint上。在公共云上的网络环境比较复杂,分公网域名和内网域名,内网域名还分经典网络和VBC,也许会有路由的endpoint网络不通这种场景,这个时候平台提供了一个接口,用户可以把能访问的Tunnel endpoint填进来,这样就会优先用所填的Tunnel endpoint而不会用路由的,但99%的情况下是不用填。
Default project这个参数是在弹内经常用的。MaxCompute的权限管理非常丰富,比如如果在公共云上有多个project,想要控制数据在跨project流动的话,就可以通过这个参数来配置。ODPS里设置的Default Project可以理解为是原project,下面的create Stream Session里面又有一个project,即要访问数据所在的project。如果这两个project不一样,系统会检查这个权限,用户是否可以访问目标project的数据。如果跑SQL,它也会根据原project来控制资源的使用。如果只有一个,这两个填成一样的就可以。
一般来说,Access ID,Access Key, 和ODPS Endpoint是必选的,Tunnel Endpoint可选,Default project如果只有一个只填一个就行了。
2)具体的上传接口
接下来展示具体的上传接口。首先看批量上传。
【批量上传】

MaxComputeTunnel-批量上传(示例)
pubuicstaticvoldmain(stringargs)
功能点
ALIyUnACCOUnt(cCEssIoE
ACCOUNTACCOUNTE
odpsodpsAneaodpsCoccount):
OdPSSETEndPOINTC(OdPSURD):
有状态并发(BlockID)
odpssetDetauitProjectCoroject);
tryt
BlockID重复使用会导致数据覆盖
TABLETUNNELtunneLnETabteTunnei(odps);
Commit成功数据可见
TUnNELSEtEndpoint(tunneiurD);
PartitionspecpartitionpecnePartitione
Uplosdsessonplodse
taby/.partitionspee):
Syoteut.inttnsesiottoon
支持lnsertlnto语义
TabLeschenaschenauploadsession.getscheaO:
姓9999月6230
RECOREARItEreEOROARtEpLoadsesonRecorutero;
RECORDREcoRDUpLoadSescr
支持lnsertoverwrite语义
FORInt+B:scHeageoLuO.z)
TOR(1NT120118:1+0)
recordkriterriteecord)
wrte不可重试,港到推错需要重新openWriter
使用限制
dose成功数据写成功,close不可重试
recordkritercloseO.
UpLoadsesson.coitn
检查block列表是否与服务端一致,可不填
Syste.out.printntupLoadsuccess);
Uploadsession内20000B
0Block
CATCH(TUNNELEXCEPTIOn
commit成功数据可见
儿建议盟试一定次数.
e.printstackiraceO;
BlockID重复会导致数据覆盖
commit可重试,赛等操作
CAtch(IOExcEpTion
这童试一定次数.
GSR月6
e.printstackTraceO;
Uploadsession24小时过期
空闲连接120秒超时
上图中可以看到,批量上传的流程是先创建一个upload session (第31行),然后open writer,用writer去写数据,然后close,再upload session加commit。
Upload session可以理解为是一个会话的对象,类似于transaction的概念。这次上传是以upload session为单位的,即最终upload session commit成功了这些数据才是可见的。在一个upload session内部可以open多个writer,并且多个writer可以并发上传,但是writer是有状态的,需要给它指定一个不重复的block ID,避免产生覆盖。Upload session也是有状态的,没有commit就不可见; 如果commit成功了,这个session就结束了,暂时就不能再去open writer。Writer的实现原理是open一个writer请求,系统会发一个HTP请求到服务端,然后保持这个长链接,写数据时平台会实时地把数据写到服务端,writer是写一个临时目录。根据这个机制可以看到,如果writer或者close失败了,就相当于这个长连接断了。所以writer和close这两个接口是不能重试的,如果writer中间有任何阶段失败了,就需要重新写。
除了正常的commit之外,MaxCompute还支持让用户检查数据正确性。比如用户open了五个writer,commit的时候可以把这五个ID当成例子上传确认。如果检查到服务端与这个例子不一致,commit就会报错。
总结一下,基本的功能点有:
批量上传是有状态并发;
commit成功后数据才可见;
支持insertOverwrite, 也支持InsertInto语义。
Insert overwrite指commit的时候支持使用某个upload session的数据直接overwrite掉一整个分区或者一张表,类似SQL的Insert和Overwrite的功能。
这个功能也有使用限制。
第一,一个upload session不能超过2万个Block。
第二,Block ID会导致数据覆盖。
第三,upload session 24小时过期,因为writer数据是写在存储的临时目录的,临时数据有回收周期,超过24小时, writer写过的数据就有可能被回收掉,这个就限制了upload session的生命周期。
第四,如果open了一个writer但是不写数据,就相当于占了一个空闲链接,服务端会把这个链接直接断掉。
【流式上传】
接下来看一下流式上传的接口。前文中有提到,流式上传是在API上做了简化,还去掉了并发的限制和时间的限制。

eTunnel-流式上传(示例)
MaxComputeT
n(stringargs[)
main(
PUBiiSToTIcVo10日
功能点
ALIYUNACCOUNT(ACCESICESS
ACCOuntaccountEne
odpsodpsanenodps(account);
SPB3A3338SGSRE
ODPSSetEndpoint(odpsEndpoint);
无状态并发
odps.setDefaultProject(roject);
tryf
TABLETUNNELTUNNELNEWTaBLETUNNeI(ODPS;
tunneL.SetEndpoint(tunneLEndpoint);
RecordPackFlush成功数据可见
PartitionspeepartitionspecePartitionspecattn
Tabtetumtreautodo
tabte,partitionpec)
仅支持lnsertlnto语义
TabLeScHemaschemaupLoadessongetce
TABLETUNNELSTERECORPACKPACKUPLOADSESSIONNERECORPACKO
RECORDrecordupLoadSessneecord
For(Int11schena.getcotun
增量数据异步zorderby排序
咖itoCoackttakr
pack.append(record)i
tlush成功数据可见
PackFLushO;
fIOSH成功后pack对象可复用内存,避免GC
Systen.out.printin("upluass
使用限制
CATCH(TUNNELEXCEPTIoNe)
pack对象可以放在异步线程fush,
e.printstackTraccO)
避免i请求hang住业务逻辑
catch(IOExcEpTione)
表/分区加锁(停止写入15-60分钟解锁)
eprintstackTraceO:
DDL(drop/rename)感知延迟(0~60秒)
图中可以看到,接口是CreateStreamUploadSession,写数据的从writer改成了RecordPack。所谓的pack其实相当于一个内存里的buffer,可以用pack.append(record),比如判断size只需要判断这个buffer足够大或者条数足够多,然后再flush就可以了(42到44行)。Pack并不是写网络的,而是写内存的。因此,不同于writer,flush是可以重试的,因为数据都在内存里。并且Pack也没有状态,不需要关心writer的Block ID等等。另外,因为flush成功后数据就可见了,所以session也没有commit这种状态。因此,如果要开发分布式服务,这个相比批量上传就简化很多,没有太多的限制,只需要确保本机内存是否够大就好了。
同时系统还支持了内存的复用,即flush过以后的pack是可以复用的。系统会把上次写满的内存留住,避免产生GC。流式上传只支持InsertInto,因为在API上没有另外的接口,所以InsertOverwrite语义现在是不支持的。另外,流式服务是支持异步数据处理的,也就是除了保证用户通过流式写上来的数据可读之外,服务端还有一个机制能识别出来新写进来的数据和存量数据,可以对新写出来的数据做一些异步的处理,比如zorder by排序和墨纸。
ZorderBy排序是指一种数据的组织方式,可以把存在MaxCompute的数据按某些规则重新组织一遍,这样查询的时候效率会非常高。墨纸是指支持把数据在后端重新写一遍,把一些很碎的数据重新组织成存储数据存储效率较高的数据文件。在这个基础上还可以做一些排序和其他的处理,后续会再加更多的功能。
流式上传也会有一些限制。首先在写的时候,系统会对这个表加锁,流式写的时候其他的操作是不能写的,比如InsertInto和Insert Overwrite是会失败的,要把流式停掉之后才能正常写。另外,DDL有一些延迟,如果要drop table或者rename table的话,可能drop完还能成功写几条数据,会有最多60秒的延迟。如果有这种场景,建议先把流式停掉再去drop或者rename。
【批量下载】
接下来介绍批量下载的接口。

MaxcomputeTunnel-批量下载(示例)
功能点
pubLIGSTATIEvOIDIN(STRInGAR9SH
ACCOUNTACCOUNTNEALIYUNACCOUNTCOCCESDCESSKY
OdpsodpsnEEODPS(ACCOUNT):
有状态并发(range)
odpsSeTEndpoint(odpsUr);
odps.setDeFauiTProjeet(oroect);
TABLETUNNELTUNNELENETABLETUNNEL(ODPS;
record粒度切分
tunneL.SetEndpoint(tunneLury)://设置tunneiurl.
PartitionspecpartitionpecnePartitionspecartition);
tryf
支持列裁剪
出名86别80
Tabtetome.bmmlodso
partitionSpee);
SySTeNOutrint(sessionStatusis
支持查询结果下载
+downLoadsessiongetstatusO.totng
获取总行数
LONGCOUntdOWnLOadSessoncorcoun
Syste.out.printinCRecordcountcount)
RECORDREADERREEORAREADEROOMLOADSESSIONOPENRECORAREADErCC
使用限制
ader(start:e.count):
REcordrecord;
咖iLe(CcecordrecordReader.reaDO)nuL1)
Record粒度分片下载
CoNsUNeRECordCecordomdeongeceO
DownloadSession24小时过期
recordReadercloseO:
CatCH(TUnNELEXCEPTIONe
空闲连接120秒超时
86母8员
eprintstackTraceO;
cATCH(IOExCEDTIONE1)
Project级别并发限流
el.printstacktraceO:
性能受碎片文件影响
图中可以看到,TableTunnel创建了一个叫downloadSession的对象。可以得到record Count,指一个分区或者一张表的总行数。下面是open reader,可以和批量上传对应起来: reader和writer; uploadSession和downloadSession。Openreader是按record来区分的,比如有1000行,可以分十个100行并发下载。Download支持列裁剪,也就是可以下载其中几列。下载查询结果就把TableTunnel入口类改成InstanceTunnel,odps也是一样,53行就不是project, table了,是一个InstanceID。
使用限制方面,和批量上传类似,DownloadSession限制也是24小时,因为它也有临时文件。同样空闲链接120秒超时,另外还有Project级别并发限流,性能受碎片文件影响。
五、最佳实践

MaxComputeTunnel-最佳实践
高并发场景
批量下载
并发
批量上传
QPS
流式上传
批量上传有并发限流及commit抢锁
高
高
不推荐
推荐
不推荐
批量下载有并发限流
高
推荐
不推荐
不推荐
高QPS场景-小块写
高
推荐
低
不推荐
推荐
批量上传会产生大量碎片文件,SQL性能下
低
低
推荐
推荐
推荐
降
推荐
规划中
Transaction
其它
推荐
不支持
lnsertOverwrite
Transaction语义-流式上传不支持
lnsertOverwrite语义-流式上传不支持
从图中可以看到,如果并发很高,不推荐走批量接口,因为并发限流是project级别的,如果上传或者下载的限额打满,整个project的批量上传都会失败。
这种接口推荐把并发降下来,然后充分利用并发约10兆每秒的吞吐能力。流式因为架构上的原因,是不受并发限制的。QPS不建议批量上传,因为碎片文件的问题,不建议用特别高的QPS来用批量的接口写数据。 如果QPS和并发都不高,使用这三种方式都不会很受限制。
另外有几个场景,transaction现在支持批量上传,流式上传后续会跟进。目前流式上传不支持Insert Overwrite,可能后面也不一定会开发,因为这个场景明显是一个批量的语义。
以上就是关于MaxCompute Tunnel技术原理及开发实践的介绍。
更多关于大数据计算产品技术交流,可扫码加入 “MaxCompute开发者社区” 钉钉群进行咨询。

MaxCompute开发者社区2群
扫一扫,快速加入我们的企业/组织/团队