
企业的实时数据除了存储在大数据引擎中,还有很多非结构化的日志数据,通过阿里云的Elasticsearch,用全托管的方式提供低成本的冷热存储方案,轻松助力企业搭建统一的云上全观测运维监控平台,实现海量数据的实时监控分析,提高自动化运维管理效率。DataWorks数据集成提供了 “MySQL一键实时同步至Elasticsearch” 的解决方案,可以将MySQL中的数据库,通过一次性的简单配置,全增量一体化同步到Elasticsearch,达到数据实时落入ElasticSearch,实时可以用于分析的效果。如果您只需要将业务库数据离线全量或者增量搬迁到Elasticsearch中,也可以将MySQL数据库,通过一次性的简单配置,全增量一体化离线同步到Elasticsearch中。DataWorks数据集成采用自研高性能引擎,在相同的机器规格情况下,同步性能更高,价格更优惠!
目前独享数据集成资源组首月5折!立即前往购买>>
数据集成问题答疑请钉钉扫码加群咨询:
方案简介
本方案是整库全增量实时/离线同步 至Elasticsearch(目前支持的源数据库类型为MySQL,后续更多类型持续增加中)。在DataWorks数据集成界面下,单击 “一键实时同步至Elasticsearch” 新建同步任务,再通过完成“设置同步来源和规则”、“设置目标表”、“DDL消息处理规则”、“运行资源设置”这样4步简单的产品化配置,就可以将指定类型的数据库中全部表或者部分表的数据实时同步到Elasticsearch里。或者单击“整库离线同步至Elasticsearch”新建离线同步任务,再通过完成“设置同步来源和规则”、“设置目标索引”、“同步规则设置”、“运行资源设置”实现数据离线同步到Elasticsearch里。
适用场景
“一键实时同步至Elasticsearch”适用于业务库需要保持业务数据库数据实时更新至ElasticSearch的场景,供上层应用做实时数据检索分析或者后续数据开发。“整库离线同步至Elasticsearch”适用于将业务库数据全量或者增量搬迁到Elasticsearch中。
优势特点
整库级别同步:
- 不需要一个个建立表到索引的同步,支持以库为单位,选择其中所有表或者部分表进行同步
高效实时同步:
- 支持数据实时同步至ElasticSearch,灵活配置DDL规则
多种同步方式:
- 离线同步支持全量、增量以及全量和增量结合的方式,同时支持周期性调度设置
配置简单:
- 避开纷繁复杂的同步任务、建索引配字段、相互依赖、参数对齐等操作,只需简单的产品化的功能配置。
操作步骤
步骤一:创建同步解决方案任务(实时/离线)
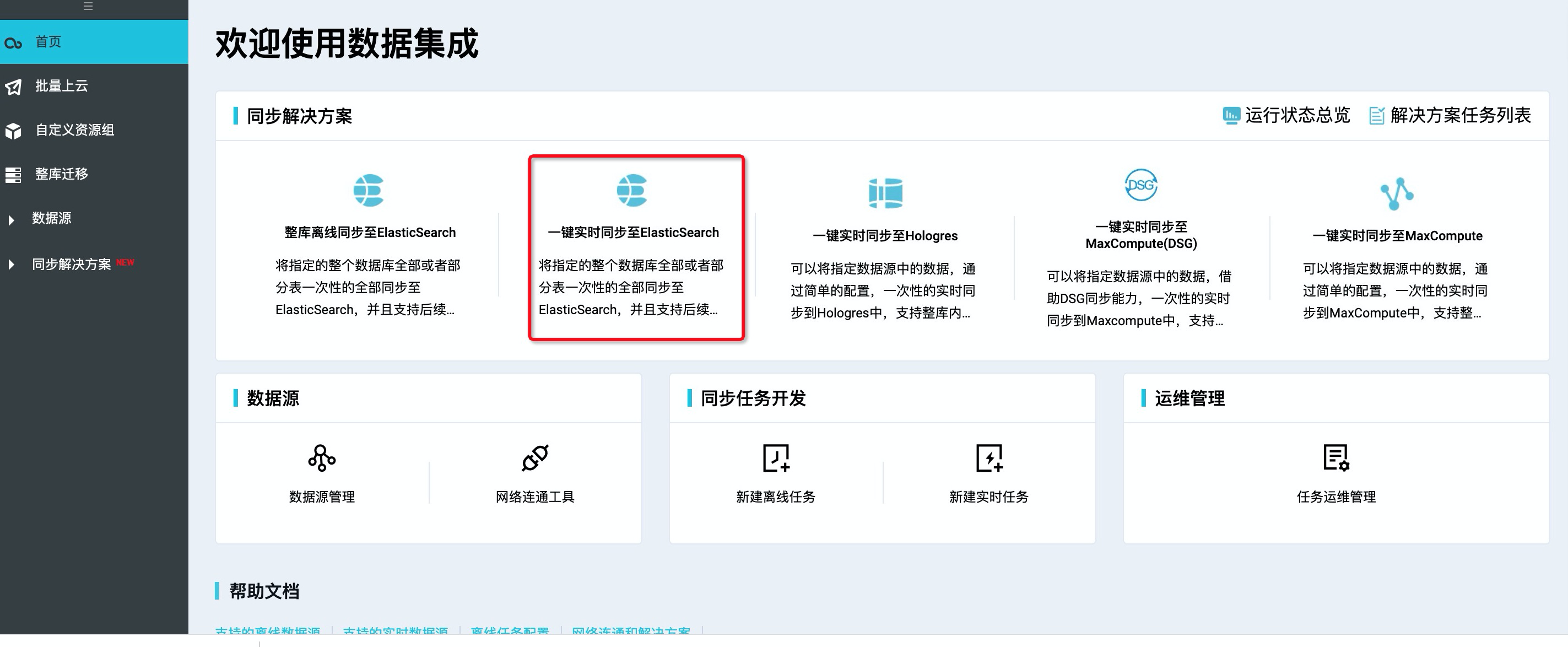
1.登录并进入"数据集成"页面,单击“一键实时同步至Elasticsearch”新建实时同步任务或者单击“整库离线同步至Elasticsearch”新建离线同步任务。
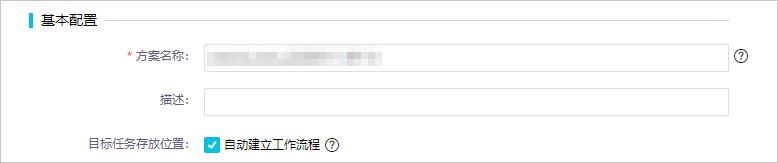
2.完成方案名称等基本信息配置。在基本配置区域,配置各项参数。
| 参数 | 描述 |
|---|---|
| 方案名称 | 同步解决方案的名称,最多支持50个字符。 |
| 描述 | 对当前方案进行简单描述,最多支持50个字符。 |
| 目标任务存放位置 | 默认创建一个新的业务流程,所有任务均以clone_database_源端数据源名称+to+目标数据源名称的命名方式存放至数据集成目录下。您也可以取消自动建立工作流程,在选择位置下拉列表中指定存放目标任务的路径。 |
步骤二:选择来源数据源并配置同步规则
1.在数据来源区域,选择类型和数据源(仅支持选择MySQ类型的数据源)
2.在选择同步的源表区域,选中需要同步的源表  图标,将其移动至已选源表。
图标,将其移动至已选源表。
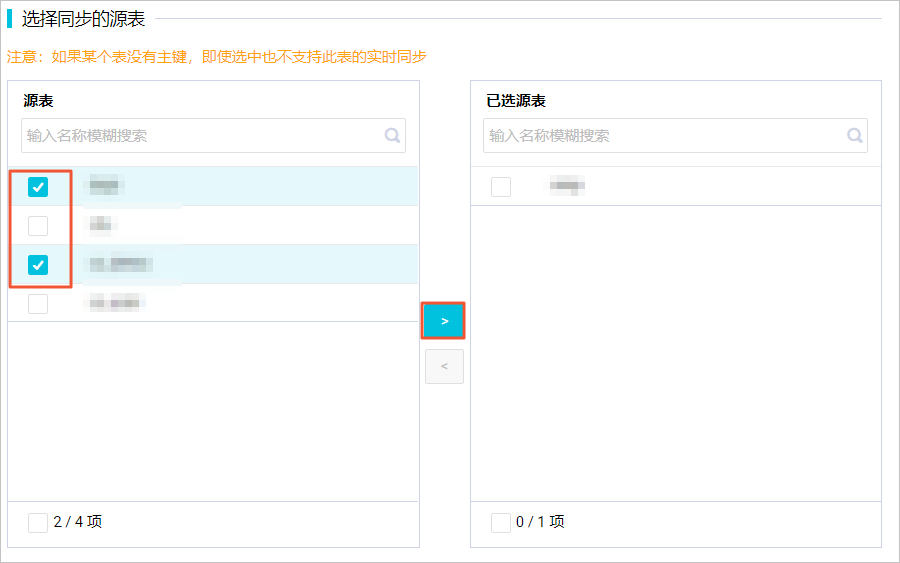
该区域会为您展示所选数据源下所有的表,您可以选择整库全表或部分表进行同步。
注意 如果选中的表没有主键,将无法进行实时同步。
3.在设置同步规则区域,单击添加规则,选择相应的规则进行添加。同步规则包括表名转换规则和目标表名规则:
- 表名转换规则:转换表名为目标表名,进行字符串替换。
- 目标表名规则:支持对转换后的表名添加前缀和后缀。
4.单击下一步。
步骤三:选择目标数据源并配置目标表格式
1.在设置目标表/设置目标索引页面,选择目标**Elasticsearch数据源**。
2.单击刷新源表和**Elasticsearch索引映射**,创建需要同步的源表和目标Elasticsearch索引的映射关系。
3.查看任务的执行进度和表来源。
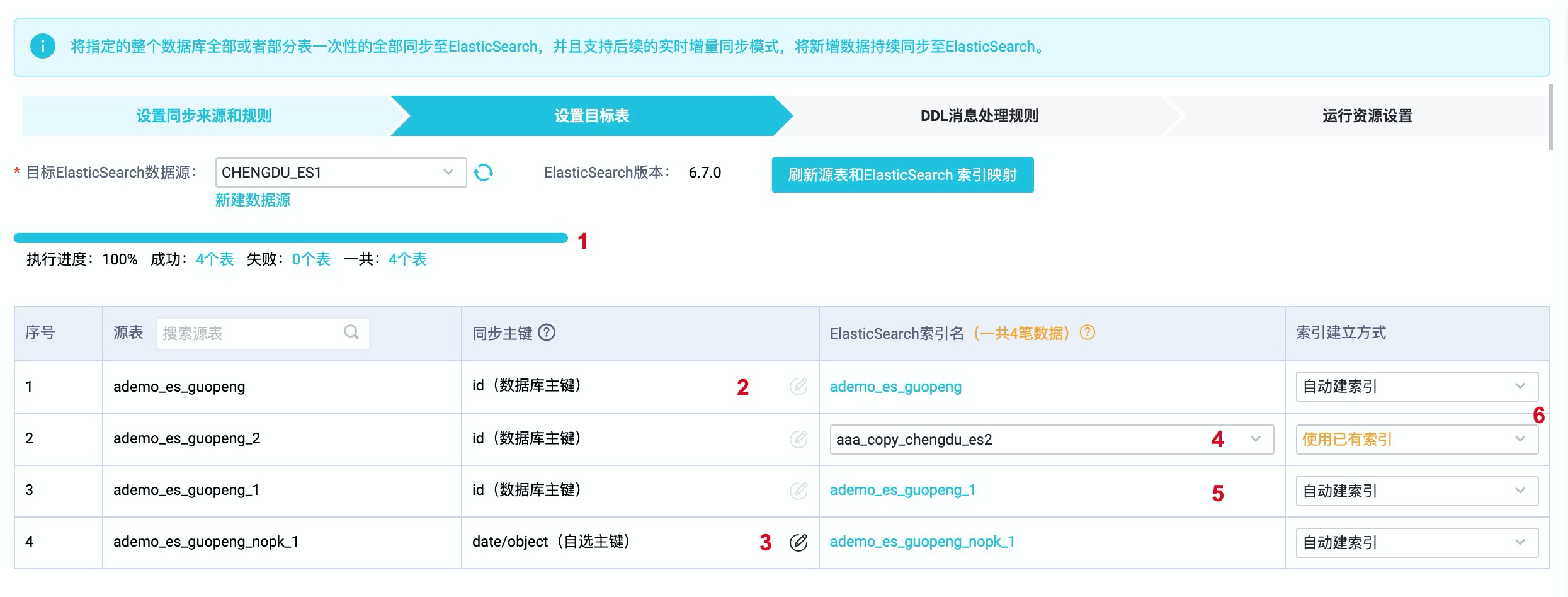
| 序号 | 描述 |
|---|---|
| ① | 显示映射关系的创建进度。说明 如果同步的表数量较多,会导致执行进度较慢,请耐心等待。 |
| ②③ | 如果来源库有主键则会直接使用此主键。如果没有,则会显示编辑标志,允许自定义主键(支持联合主键) |
| ④56 | 选择的索引建立方式:- 当索引建立方式选择自动建索引时,显示自动创建的Elasticsearch索引名称。您可以单击表名称,修改建索引的配置。- 当索引建立方式选择使用已有索引时,请在下拉列表中选择需要的索引。 |
4.单击下一步。
步骤四:DDL消息处理规则/同步规则设置
1.如果是“一键实时同步至Elasticsearch”任务,那么这一步是配置DDL消息处理规则,如下图配置要同步的方式和参数。
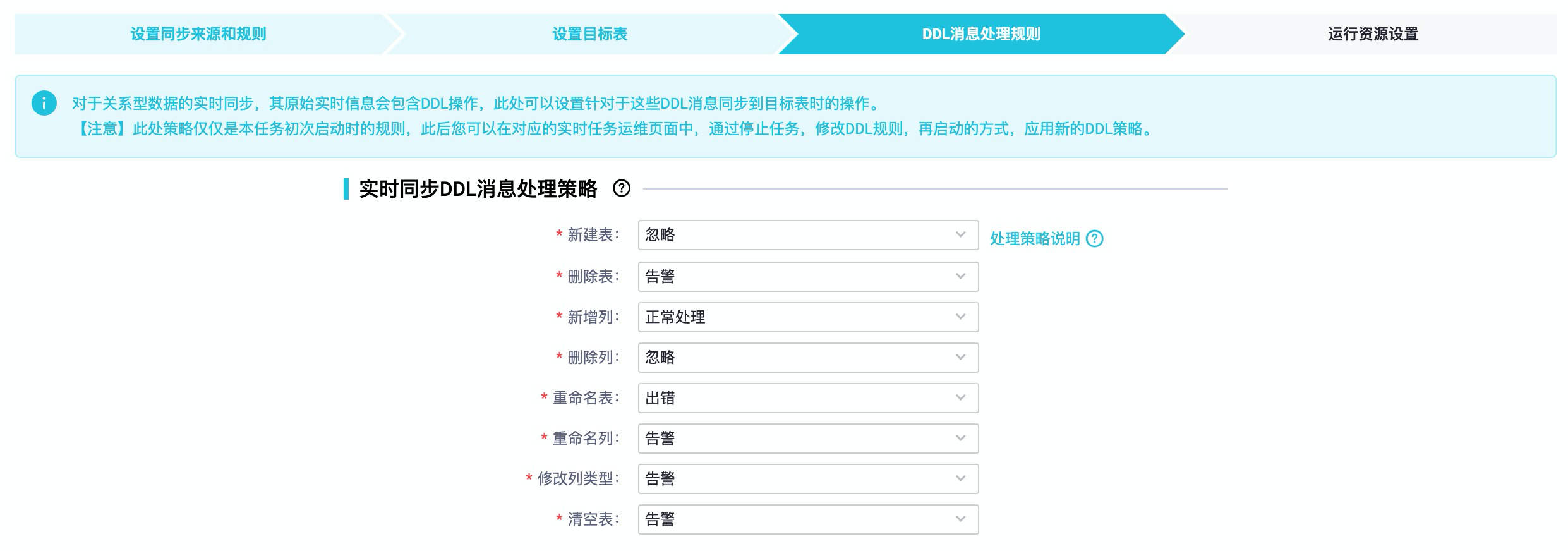
2.处理规则说明:
| 处理方式 | 解释 |
|---|---|
| 正常处理 | 此DDL消息将会继续下发给目标数据源,由目标数据源来处理,不同目标数据源处理策略可能会不同。比如“增加列”对于MaxCompute来说就是个错误,但是对于Hologres来说就可以正常增加一列。 |
| 忽略 | 丢弃掉此DDL消息,不再向目标数据源发送此消息。 |
| 告警 | 在日志中发送告警信息,同时丢弃掉此DDL消息。 |
| 出错 | 直接让实时同步任务以出错状态终止运行。 |
3.如果是“整库离线同步至Elasticsearch”任务,那么这一步应该是配置同步规则设置,如下图配置要同步的方式和参数。
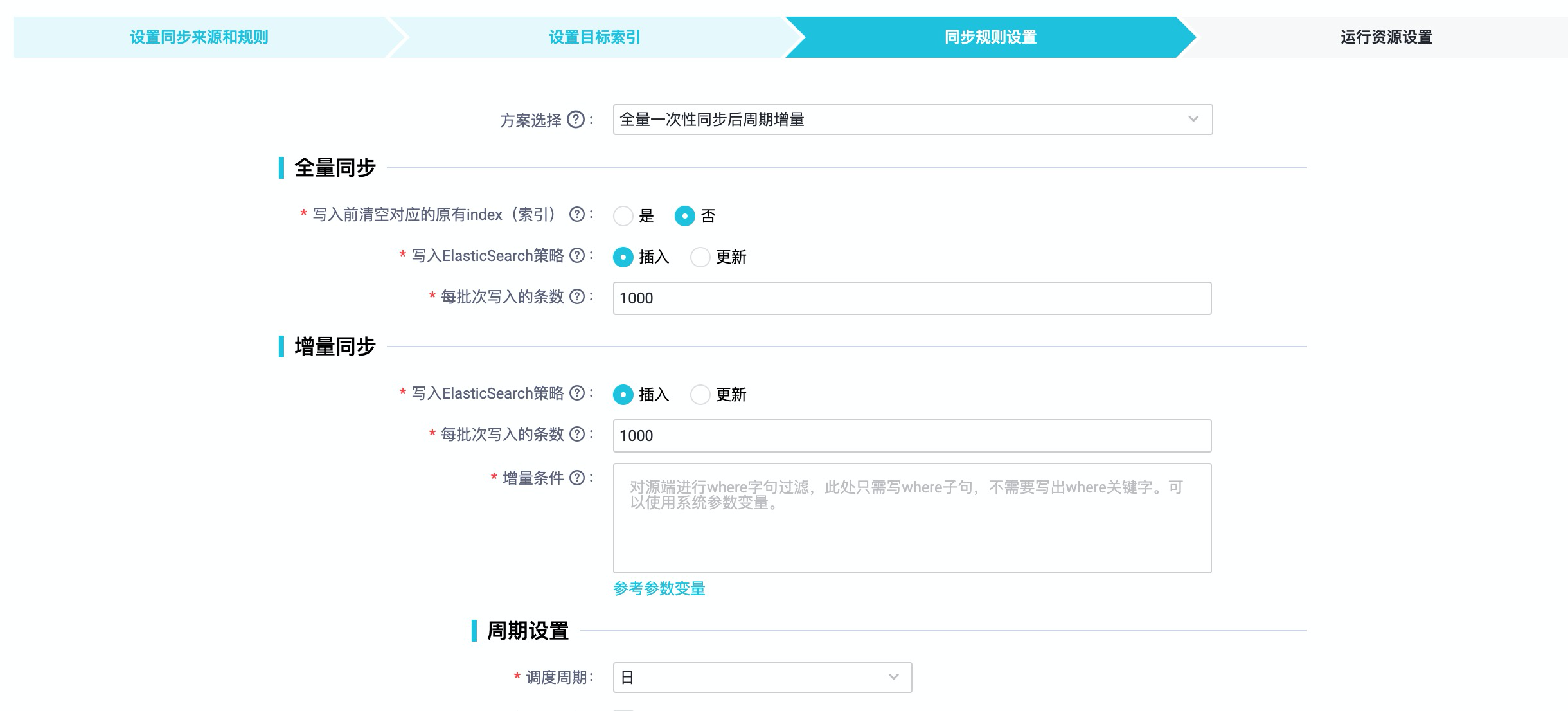
4.方案选择:
| 方案 | 解释 |
|---|---|
| 全量一次性同步后周期增量 | 先将源端所有数据全量拉取到Elasticsearch后,再按照指定的过滤条件和重复周期,每次循环将增量数据拉取到Elasticsearch中。 |
| 只全量一次性同步 | 只进行一次同步,将源端所有数据全量拉取到Elasticsearch。 |
| 只增量一次性同步 | 只进行一次同步,按照指定的过滤条件将源端的增量数据拉取到Elasticsearch中。 |
| 周期性全量同步 | 按照指定的重复周期,每次循环都将源端所有数据拉取到Elasticsearch中。 |
| 周期性增量同步 | 按照指定的过滤条件和重复周期,每次循环将增量数据拉取到Elasticsearch中。 |
步骤五:运行资源设置
在运行资源设置页面,配置各项参数。目前解决方案仅支持使用独享数据集成资源组,该资源组可以在DataWorks官网下“单独产品”购买处点击购买(注意是“独享数据集成资源”,不是调度资源),资源组详情也可参见资源规划与配置文档。
1.如果是“一键实时同步至Elasticsearch”任务,这一步配置界面如下:

2.如果是“整库离线同步至Elasticsearch”任务,这一步配置界面如下:

| 参数 | 描述 |
|---|---|
| 离线任务名称规则 | 全量同步时的离线任务名称。创建解决方案后,会先生成一个离线任务用于读取全量数据,再生成实时任务持续读取实时增量数据。 |
| 选择实时任务独享资源组 | 分别选择实时任务和全量离线任务需要使用的独享资源组。目前解决方案仅支持使用独享数据集成资源组,此处可配置为准备操作中已购买并配置的独享数据集成资源组,详情可参见资源规划与配置。 |
| 选择全量离线任务独享资源组 | |
| 选择调度资源组 | 选择运行任务时使用的调度资源组。 |
| 来源端读取支持最大连接数 | 读取端的最大连接数,即来源端数据库的JDBC连接数。请根据数据库资源的实际情况合理配置。 |
3.单击完成配置,完成数据同步解决方案任务创建。
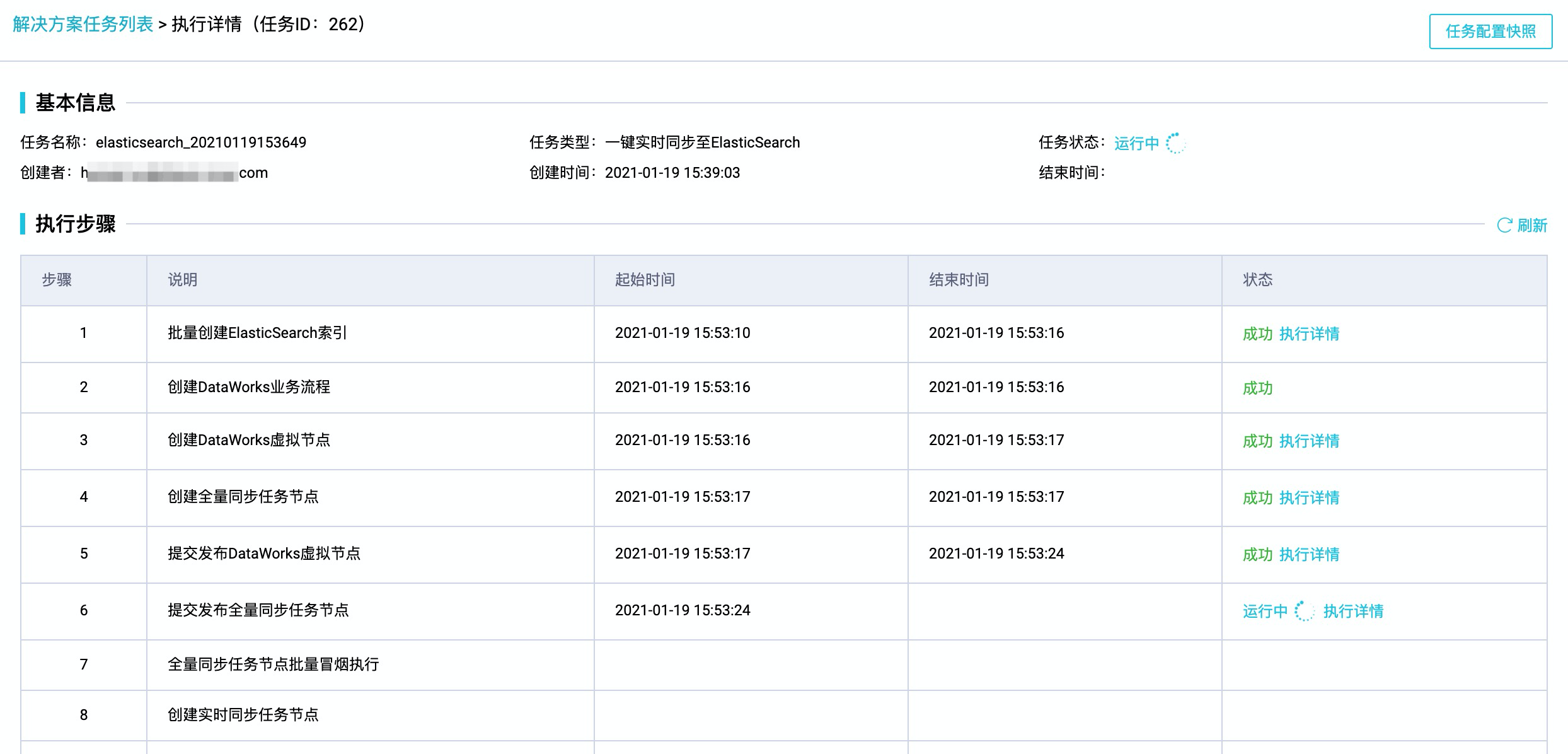
查看运行状态及结果
在解决方案任务列表页面,单击已运行任务后的执行详情,查看当前解决方案数据同步过程中各子任务节点的运行详情。
单击子任务节点后的执行详情,可在弹窗中单击任务链接进入子节点的数据开发页面。
管理数据同步解决方案任务
查看或编辑任务。在解决方案任务列表页面,单击相应任务后的任务配置,可以查看或编辑任务。
仅单击未运行状态后的任务配置,您可以编辑任务。其它状态下的任务配置页面,仅支持查看。
删除任务:单击相应任务后的删除。在删除对话框中,单击确定(仅删除当前任务的配置记录,已经生成的表和任务不受影响)。
总结
以上就是Elasticsearch实时同步解决方案的全部内容,数据同步到Elasticsearch之后,您可以很方便地做实时分布式的搜索与分析,Elasticsearch构建在Elastic Stack开源生态矩阵中,包括Beats(轻量级数据采集工具)、Logstash(收集、过滤、传输数据的工具)、Elasticsearch、Kibana(灵活的可视化工具)。您可以很方便地利用丰富的工具快速搭建您的数据检索或者实时监控运维应用。
如果您对本次方案感兴趣的话,可以到Elasticsearch和DataWorks的官网查看具体产品信息:
数据集成产品介绍:https://help.aliyun.com/document_detail/199008.html
Elasticsearch产品官网:https://www.aliyun.com/product/bigdata/product/elasticsearch
DataWorks产品官网:https://www.aliyun.com/product/bigdata/ide
数据集成问题答疑请钉钉扫码加群咨询:




