
作者:王庆璨 张凯
进击的Kubernetes调度系统(一):Scheduling Framework
进击的Kubernetes调度系统(二):支持批任务的Coscheduling/Gang scheduling
进击的Kubernetes调度系统(三):支持批任务的Binpack Scheduling
前言
本系列的前两篇《进击的Kubernetes调度系统 (一):Scheduling Framework》 和进击的 Kubernetes 调度系统(二):支持批任务的 Coscheduling/Gang scheduling 分别介绍了Kubernetes Scheduling Framework和如何通过扩展Scheduling Framework实现Coscheduling/Gang scheduling调度策略。当我们的批任务作业在集群里边运行起来之后,随后要关注的就是资源的利用率。特别是对于GPU卡的价格昂贵,不希望有资源的浪费。本文将介绍在批任务的调度过程中如何通过Binpack的方式,减少资源碎片,提升GPU的利用率。
为什么需要Binpack功能?
Kubernetes默认开启的资源调度策略是LeastRequestedPriority,消耗的资源最少的节点会优先被调度,使得整体集群的资源使用在所有节点之间分配地相对均匀。但是这种调度策略往往也会在单个节点上产生较多资源碎片。
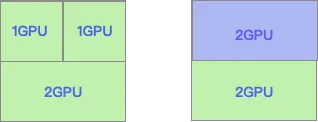
下面拿一个简单的例子来说明这种问题。如下图所示,资源在节点之间平均使用,所以每个节点使用3个GPU卡,则两个节点各剩余1GPU的资源。这是有申请2GPU的新作业,提交到调度器,则因为无法提供足够的资源,导致调度失败。

如上这种情况情况,每个节点都有1个GPU卡空闲,可是又无法被利用,导致资源GPU这种昂贵的资源被浪费。如果使用的资源调度策略是Binpack,优先将节点资源填满之后,再调度下一个节点,则上图所出现的资源碎片问题得到解决。申请2GPU的作业被正常调度到节点上,提升了集群的资源使用率。
实现方案
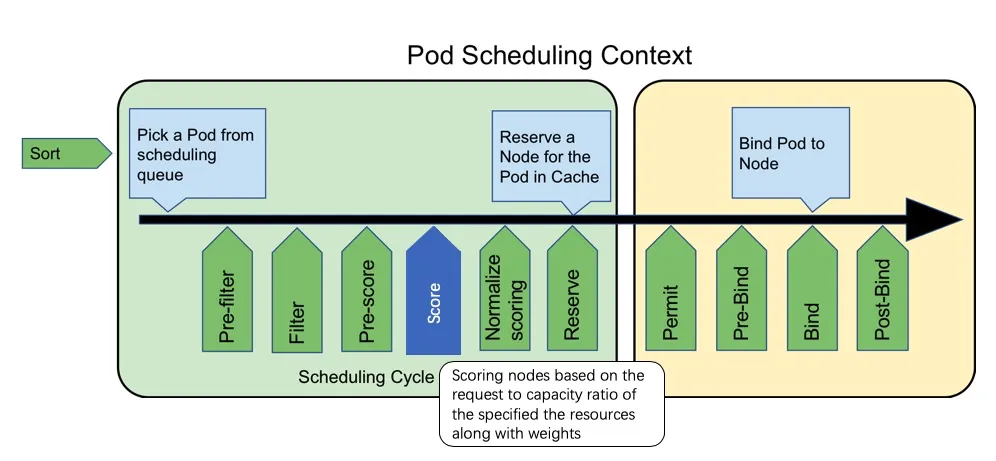
Binpack实现已经抽象成Kubernetes Scheduler Framework的Score插件RequestedToCapacityRatio,用于优选阶段给节点打分。将节点根据自己定义的配置进行打分。具体的实现可以分为两个部分,构建打分函数和打分.
构建打分函数
构建打分函数的过程比较容易理解,就是用户可以自己定义不同的利用率所对应的分值大小,以便影响调度的决策过程。
如果用户设定的对应方式如下所示,即如果资源利用率为0的时候,得分为0分,当资源利用率为100时,得分为10分,所以得到的资源利用率越高,得分越高,则这个行为是Binpack的资源分配方式。

用户也可以设置成利用率为0时,得分为10分,利用率为100时,得分为0分。这样意味着资源利用率越低,则得分越高,这种行为是spreading的资源分配方式。

用户除了2个点之外也可以新增更多的点,对应关系可以不是线性的关系,例如可以标识资源利用率为50时,得分为8,则会将打分分割为两个区间: 0-50和50-100。

打分
用户可以自己定义在Binpack计算中所要参考的资源以及权重值,例如可以只是设定GPU和CPU的值和权重。
resourcetoweightmap:
"cpu": 1
"nvidia.com/gpu": 1然后在打分过程总,会通过计算(pod.Request + node.Allocated)/node.Total的结果得到对应资源的利用率,并且将利用率带入上文中所述的打分函数中,得到相应的分数。最后将所有的资源根据weight值,加权得到最终的分数。
Score = line(resource1_utilization) * weight1 + line(resource2_utilization) * weight2 ....) / (weight1 + weight2 ....)Binpack使用
配置方法
- 新建/etc/kubernetes/scheduler-config.yaml, 用户可以自行配置其他的priorities策略。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
clientConnection:
kubeconfig: "REPLACE_ME_WITH_KUBE_CONFIG_PATH"
plugins:
score:
enabled:
- name: RequestedToCapacityRatio
weight: 100
disabled:
- name: LeastRequestedPriority
pluginConfig:
- name: RequestedToCapacityRatio
args:
functionshape:
- utilization: 0
score: 0
- utilization: 100
score: 100
resourcetoweightmap: # 定义具体根据哪种资源类型进行binpack操作,多种资源时可以设置weight来进行比重设置
"cpu": 1
"nvidia.com/gpu": 1Demo演示
接下来我们通过运行Tensorflow的分布式作业来进行演示,展示Binpack的效果,当前测试集群有2台4卡的GPU机器
- 通过Kubeflow的arena在已有的Kubernetes集群中部署tf-operator
Arena是基于Kubernetes的机器学习系统开源社区Kubeflow中的子项目之一。Arena用命令行和SDK的形式支持了机器学习任务的主要生命周期管理(包括环境安装,数据准备,到模型开发,模型训练,模型预测等),有效提升了数据科学家工作效率。
git clone https://github.com/kubeflow/arena.git
kubectl create ns arena-system
kubectl create -f arena/kubernetes-artifacts/jobmon/jobmon-role.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-crd.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-operator.yaml检查是否部署成功
$ kubectl get pods -n arena-system
NAME READY STATUS RESTARTS AGE
tf-job-dashboard-56cf48874f-gwlhv 1/1 Running 0 54s
tf-job-operator-66494d88fd-snm9m 1/1 Running 0 54s- 用户向集群中提交Tensorflow分布式,作业含有1个PS和4个Worker,每个Worker需要1个GPU
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "tf-smoke-gpu"
spec:
tfReplicaSpecs:
PS:
replicas: 1
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
cpu: '1'
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
Worker:
replicas: 4
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 1
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure- 当用户使用Binpack功能时,用户提交任务后,4个Worker被调度到同一个GPU节点cn-shanghai.192.168.0.129
$ kubectl get pods -o wide
NAME READY STATUS AGE IP NODE
tf-smoke-gpu-ps-0 1/1 Running 15s 172.20.0.210 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-0 1/1 Running 17s 172.20.0.206 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-1 1/1 Running 17s 172.20.0.207 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-2 1/1 Running 17s 172.20.0.209 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-3 1/1 Running 17s 172.20.0.208 cn-shanghai.192.168.0.129 - 当用户不使用Binpack功能时,用户提交任务后,4个Worker被分配到cn-shanghai.192.168.0.129和cn-shanghai.192.168.0.130两个节点上,产生资源碎片
$ kubectl get pods -o wide
NAME READY STATUS AGE IP NODE
tf-smoke-gpu-ps-0 1/1 Running 7s 172.20.1.72 cn-shanghai.192.168.0.130
tf-smoke-gpu-worker-0 1/1 Running 8s 172.20.0.214 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-1 1/1 Running 8s 172.20.1.70 cn-shanghai.192.168.0.130
tf-smoke-gpu-worker-2 1/1 Running 8s 172.20.0.215 cn-shanghai.192.168.0.129
tf-smoke-gpu-worker-3 1/1 Running 8s 172.20.1.71 cn-shanghai.192.168.0.130后记
上文中我们介绍了如何利用Kubernetes原生的调度策略RequestedToCapacityRatio来支持Binpack Scheduling的功能,减少资源碎片,提升GPU的利用率。使用起来很简单,但是效果很明显。针对GPU的资源利用率的提升的课题,我们将在本系列接下来的文章中介绍如何在推理服务下,通过GPU共享调度的方法大大的提升GPU利用率。


