开篇
最早接触DataX是在前阿里同事在现在的公司引入的时候提到的,一直想抽空好好看看这部分代码,因为DataX的代码框架设计的很好,非常适合二次开发。在熟悉DataX的代码过程中,没有时间针对每个数据源的读写部分代码进行研究(这部分代码非常值得研究,基本上主流数据源的读写操作都能看到),主要阅读的还是DataX的启动和工作部分代码。
DataX的框架的核心部分我个人看来就两大块,一块是配置贯穿DataX,all in configuration,将配置的json用到了极致;另一块是通过URLClassLoader实现插件的热加载。
DataX的github地址:https://github.com/alibaba/DataX
DataX介绍
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
Job&Task概念
在DataX的逻辑模型中包括job、task两个维度,通过将job进行task拆分,然后将task合并到taskGroup进行运行。
job实例运行在jobContainer容器中,它是所有任务的master,负责初始化、拆分、调度、运行、回收、监控和汇报,但它并不做实际的数据同步操作。
Job: Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。
Task: Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。
TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroup。
JobContainer: Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTracker。
TaskGroupContainer: TaskGroup执行器,负责执行一组Task的工作单元,类似Yarn中的TaskTracker。
简而言之, Job拆分成Task,在分别在框架提供的容器中执行,插件只需要实现Job和Task两部分逻辑。
启动过程
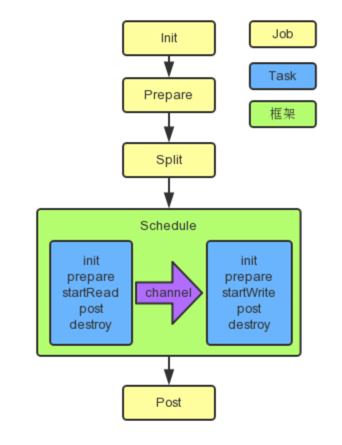
说明:
- 上图中,黄色表示
Job部分的执行阶段,蓝色表示Task部分的执行阶段,绿色表示框架执行阶段。
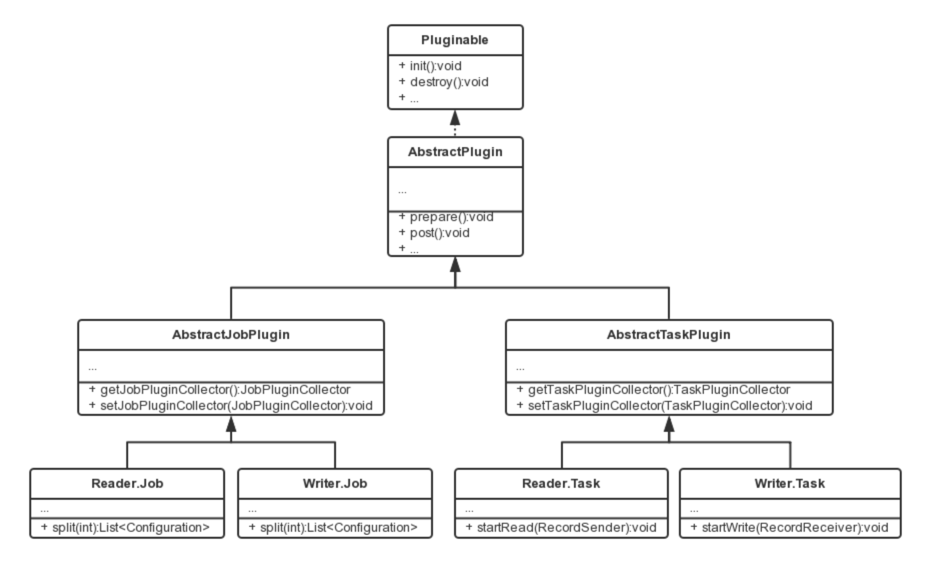
说明:
- reader和writer的自定义插件内部需要实现job和task的接口即可
DataX开启Debug
阅读源码的最好方法是debug整个项目工程,在如何调试DataX项目的过程中还是花费了一些精力在里面的,现在一并共享出来供有兴趣的程序员一并研究。
整个debug过程需要按照下列步骤进行:
- 1、github上下载DataX的源码并通过以下命令进行编译,github官网有编译命令,如果遇到依赖包无法下载可以省去部分writer或reader插件,不影响debug。
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
- 2、由于DataX是通过python脚本进行启动的,所以在python脚本中把启动参数打印出来,核心在于print startCommand这句,继而我们就能够获取启动命令参数了。
if __name__ == "__main__":
printCopyright()
parser = getOptionParser()
options, args = parser.parse_args(sys.argv[1:])
if options.reader is not None and options.writer is not None:
generateJobConfigTemplate(options.reader,options.writer)
sys.exit(RET_STATE['OK'])
if len(args) != 1:
parser.print_help()
sys.exit(RET_STATE['FAIL'])
startCommand = buildStartCommand(options, args)
print startCommand
child_process = subprocess.Popen(startCommand, shell=True)
register_signal()
(stdout, stderr) = child_process.communicate()
sys.exit(child_process.returncode)
- 3、获取启动DataX的启动命令
java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=//Users/lebron374/Documents/github/DataX/target/datax/datax/log
-Dloglevel=info -Dfile.encoding=UTF-8
-Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener
-Djava.security.egd=file:///dev/urandom -Ddatax.home=//Users/lebron374/Documents/github/DataX/target/datax/datax
-Dlogback.configurationFile=//Users/lebron374/Documents/github/DataX/target/datax/datax/conf/logback.xml
-classpath //Users/lebron374/Documents/github/DataX/target/datax/datax/lib/*:.
-Dlog.file.name=s_datax_job_job_json
com.alibaba.datax.core.Engine
-mode standalone -jobid -1
-job //Users/lebron374/Documents/github/DataX/target/datax/datax/job/job.json
- 4、配置Idea启动脚本
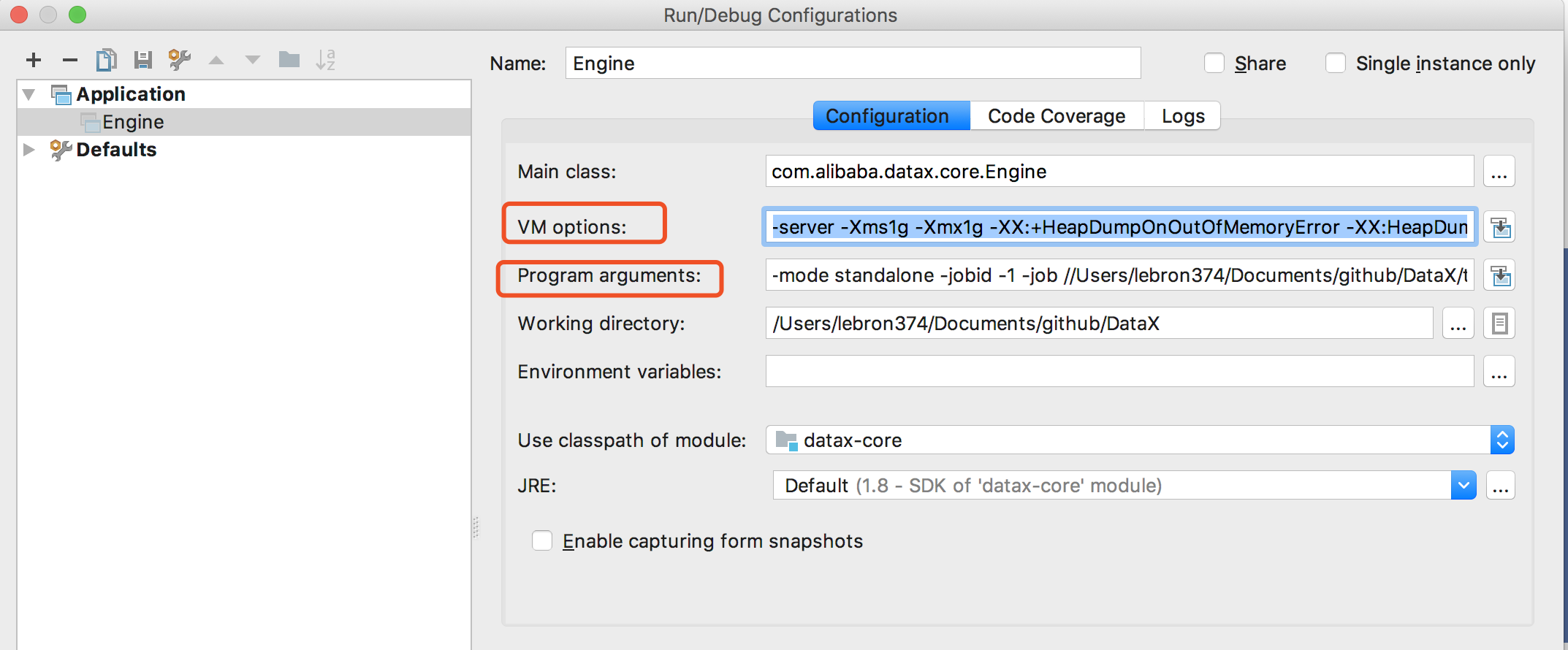
以下配置在VM options当中
-server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=//Users/lebron374/Documents/github/DataX/target/datax/datax/log
-Dloglevel=info -Dfile.encoding=UTF-8
-Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener
-Djava.security.egd=file:///dev/urandom -Ddatax.home=//Users/lebron374/Documents/github/DataX/target/datax/datax
-Dlogback.configurationFile=//Users/lebron374/Documents/github/DataX/target/datax/datax/conf/logback.xml
-classpath //Users/lebron374/Documents/github/DataX/target/datax/datax/lib/*:.
-Dlog.file.name=s_datax_job_job_json
com.alibaba.datax.core.Engine
以下配置在Program arguments当中
-mode standalone -jobid -1
-job //Users/lebron374/Documents/github/DataX/target/datax/datax/job/job.json
启动步骤解析
1、解析配置,包括job.json、core.json、plugin.json三个配置
2、设置jobId到configuration当中
3、启动Engine,通过Engine.start()进入启动程序
4、设置RUNTIME_MODE奥configuration当中
5、通过JobContainer的start()方法启动
6、依次执行job的preHandler()、init()、prepare()、split()、schedule()、- post()、postHandle()等方法。
7、init()方法涉及到根据configuration来初始化reader和writer插件,这里涉及到jar包热加载以及调用插件init()操作方法,同时设置reader和writer的configuration信息
8、prepare()方法涉及到初始化reader和writer插件的初始化,通过调用插件的prepare()方法实现,每个插件都有自己的jarLoader,通过集成URLClassloader实现而来
9、split()方法通过adjustChannelNumber()方法调整channel个数,同时执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,达到切分后数目相等,才能满足1:1的通道模型
10、channel的计数主要是根据byte和record的限速来实现的,在split()的函数中第一步就是计算channel的大小
11、split()方法reader插件会根据channel的值进行拆分,但是有些reader插件可能不会参考channel的值,writer插件会完全根据reader的插件1:1进行返回
12、split()方法内部的mergeReaderAndWriterTaskConfigs()负责合并reader、writer、以及transformer三者关系,生成task的配置,并且重写job.content的配置
13、schedule()方法根据split()拆分生成的task配置分配生成taskGroup对象,根据task的数量和单个taskGroup支持的task数量进行配置,两者相除就可以得出taskGroup的数量
14、schdule()内部通过AbstractScheduler的schedule()执行,继续执行startAllTaskGroup()方法创建所有的TaskGroupContainer组织相关的task,TaskGroupContainerRunner负责运行TaskGroupContainer执行分配的task。
15、taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务
启动过程源码分析
入口main函数
public class Engine {
public static void main(String[] args) throws Exception {
int exitCode = 0;
try {
Engine.entry(args);
} catch (Throwable e) {
System.exit(exitCode);
}
}
public static void entry(final String[] args) throws Throwable {
// 省略相关参数的解析代码
// 获取job的配置路径信息
String jobPath = cl.getOptionValue("job");
// 如果用户没有明确指定jobid, 则 datax.py 会指定 jobid 默认值为-1
String jobIdString = cl.getOptionValue("jobid");
RUNTIME_MODE = cl.getOptionValue("mode");
// 解析配置信息
Configuration configuration = ConfigParser.parse(jobPath);
// 省略相关代码
boolean isStandAloneMode = "standalone".equalsIgnoreCase(RUNTIME_MODE);
configuration.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, jobId);
// 根据配置启动参数
Engine engine = new Engine();
engine.start(configuration);
}
}
说明:
main函数主要做两件事情,分别是:
- 1、解析job相关配置生成configuration。
- 2、依据配置启动Engine。
configuration解析过程
public final class ConfigParser {
private static final Logger LOG = LoggerFactory.getLogger(ConfigParser.class);
/**
* 指定Job配置路径,ConfigParser会解析Job、Plugin、Core全部信息,并以Configuration返回
*/
public static Configuration parse(final String jobPath) {
// 加载任务的指定的配置文件,这个配置是有固定的json的固定模板格式的
Configuration configuration = ConfigParser.parseJobConfig(jobPath);
// 合并conf/core.json的配置文件
configuration.merge(
ConfigParser.parseCoreConfig(CoreConstant.DATAX_CONF_PATH),
false);
// todo config优化,只捕获需要的plugin
// 固定的节点路径 job.content[0].reader.name
String readerPluginName = configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
// 固定的节点路径 job.content[0].writer.name
String writerPluginName = configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_WRITER_NAME);
// 固定的节点路径 job.preHandler.pluginName
String preHandlerName = configuration.getString(
CoreConstant.DATAX_JOB_PREHANDLER_PLUGINNAME);
// 固定的节点路径 job.postHandler.pluginName
String postHandlerName = configuration.getString(
CoreConstant.DATAX_JOB_POSTHANDLER_PLUGINNAME);
// 添加读写插件的列表待加载
Set<String> pluginList = new HashSet<String>();
pluginList.add(readerPluginName);
pluginList.add(writerPluginName);
if(StringUtils.isNotEmpty(preHandlerName)) {
pluginList.add(preHandlerName);
}
if(StringUtils.isNotEmpty(postHandlerName)) {
pluginList.add(postHandlerName);
}
try {
// parsePluginConfig(new ArrayList<String>(pluginList))加载指定的插件的配置信息,并且和全局的配置文件进行合并
configuration.merge(parsePluginConfig(new ArrayList<String>(pluginList)), false);
}catch (Exception e){
}
// configuration整合了三方的配置,包括 任务配置、core核心配置、指定插件的配置。
return configuration;
}
// 在指定的reader和writer目录获取指定的插件并解析其配置
public static Configuration parsePluginConfig(List<String> wantPluginNames) {
// 创建一个空的配置信息对象
Configuration configuration = Configuration.newDefault();
Set<String> replicaCheckPluginSet = new HashSet<String>();
int complete = 0;
// 所有的reader在/plugin/reader目录,遍历获取所有reader的目录
// 获取待加载插件的配资信息,并合并到上面创建的空配置对象
// //Users/lebron374/Documents/github/DataX/target/datax/datax/plugin/reader
for (final String each : ConfigParser
.getDirAsList(CoreConstant.DATAX_PLUGIN_READER_HOME)) {
// 解析单个reader目录,eachReaderConfig保存的是key是plugin.reader.pluginname,value是对应的plugin.json内容
Configuration eachReaderConfig = ConfigParser.parseOnePluginConfig(each, "reader", replicaCheckPluginSet, wantPluginNames);
if(eachReaderConfig!=null) {
// 采用覆盖式的合并
configuration.merge(eachReaderConfig, true);
complete += 1;
}
}
// //Users/lebron374/Documents/github/DataX/target/datax/datax/plugin/writer
for (final String each : ConfigParser
.getDirAsList(CoreConstant.DATAX_PLUGIN_WRITER_HOME)) {
Configuration eachWriterConfig = ConfigParser.parseOnePluginConfig(each, "writer", replicaCheckPluginSet, wantPluginNames);
if(eachWriterConfig!=null) {
configuration.merge(eachWriterConfig, true);
complete += 1;
}
}
if (wantPluginNames != null && wantPluginNames.size() > 0 && wantPluginNames.size() != complete) {
throw DataXException.asDataXException(FrameworkErrorCode.PLUGIN_INIT_ERROR, "插件加载失败,未完成指定插件加载:" + wantPluginNames);
}
return configuration;
}
}
说明:
configuration解析包括三部分的配置解析合并解析结果并返回,分别是:
- 1、解析job的配置信息,由启动参数指定job.json文件。
- 2、解析DataX自带配置信息,由默认指定的core.json文件。
- 3、解析读写插件配置信息,由job.json指定的reader和writer插件信息
configuration配置信息
job.json的configuration
{
"job": {
"setting": {
"speed": {
"byte":10485760,
"record":1000
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19890604,
"type": "long"
},
{
"value": "1989-06-04 00:00:00",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 100000
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
]
}
}
core.json的configuration
{
"entry": {
"jvm": "-Xms1G -Xmx1G",
"environment": {}
},
"common": {
"column": {
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",
"timeFormat": "HH:mm:ss",
"dateFormat": "yyyy-MM-dd",
"extraFormats":["yyyyMMdd"],
"timeZone": "GMT+8",
"encoding": "utf-8"
}
},
"core": {
"dataXServer": {
"address": "http://localhost:7001/api",
"timeout": 10000,
"reportDataxLog": false,
"reportPerfLog": false
},
"transport": {
"channel": {
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
"speed": {
"byte": 100,
"record": 10
},
"flowControlInterval": 20,
"capacity": 512,
"byteCapacity": 67108864
},
"exchanger": {
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger",
"bufferSize": 32
}
},
"container": {
"job": {
"reportInterval": 10000
},
"taskGroup": {
"channel": 5
},
"trace": {
"enable": "false"
}
},
"statistics": {
"collector": {
"plugin": {
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector",
"maxDirtyNumber": 10
}
}
}
}
}
plugin.json的configuration
{
"name": "streamreader",
"class": "com.alibaba.datax.plugin.reader.streamreader.StreamReader",
"description": {
"useScene": "only for developer test.",
"mechanism": "use datax framework to transport data from stream.",
"warn": "Never use it in your real job."
},
"developer": "alibaba"
}
{
"name": "streamwriter",
"class": "com.alibaba.datax.plugin.writer.streamwriter.StreamWriter",
"description": {
"useScene": "only for developer test.",
"mechanism": "use datax framework to transport data to stream.",
"warn": "Never use it in your real job."
},
"developer": "alibaba"
}
合并后的configuration
{
"common": {
"column": {
"dateFormat": "yyyy-MM-dd",
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",
"encoding": "utf-8",
"extraFormats": ["yyyyMMdd"],
"timeFormat": "HH:mm:ss",
"timeZone": "GMT+8"
}
},
"core": {
"container": {
"job": {
"id": -1,
"reportInterval": 10000
},
"taskGroup": {
"channel": 5
},
"trace": {
"enable": "false"
}
},
"dataXServer": {
"address": "http://localhost:7001/api",
"reportDataxLog": false,
"reportPerfLog": false,
"timeout": 10000
},
"statistics": {
"collector": {
"plugin": {
"maxDirtyNumber": 10,
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector"
}
}
},
"transport": {
"channel": {
"byteCapacity": 67108864,
"capacity": 512,
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
"flowControlInterval": 20,
"speed": {
"byte": -1,
"record": -1
}
},
"exchanger": {
"bufferSize": 32,
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger"
}
}
},
"entry": {
"jvm": "-Xms1G -Xmx1G"
},
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"column": [{
"type": "string",
"value": "DataX"
}, {
"type": "long",
"value": 19890604
}, {
"type": "date",
"value": "1989-06-04 00:00:00"
}, {
"type": "bool",
"value": true
}, {
"type": "bytes",
"value": "test"
}],
"sliceRecordCount": 100000
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": false
}
}
}],
"setting": {
"errorLimit": {
"percentage": 0.02,
"record": 0
},
"speed": {
"byte": 10485760
}
}
},
"plugin": {
"reader": {
"streamreader": {
"class": "com.alibaba.datax.plugin.reader.streamreader.StreamReader",
"description": {
"mechanism": "use datax framework to transport data from stream.",
"useScene": "only for developer test.",
"warn": "Never use it in your real job."
},
"developer": "alibaba",
"name": "streamreader",
"path": "//Users/lebron374/Documents/github/DataX/target/datax/datax/plugin/reader/streamreader"
}
},
"writer": {
"streamwriter": {
"class": "com.alibaba.datax.plugin.writer.streamwriter.StreamWriter",
"description": {
"mechanism": "use datax framework to transport data to stream.",
"useScene": "only for developer test.",
"warn": "Never use it in your real job."
},
"developer": "alibaba",
"name": "streamwriter",
"path": "//Users/lebron374/Documents/github/DataX/target/datax/datax/plugin/writer/streamwriter"
}
}
}
}
Engine的start过程
public class Engine {
private static final Logger LOG = LoggerFactory.getLogger(Engine.class);
private static String RUNTIME_MODE;
/* check job model (job/task) first */
public void start(Configuration allConf) {
// 省略相关代码
boolean isJob = !("taskGroup".equalsIgnoreCase(allConf
.getString(CoreConstant.DATAX_CORE_CONTAINER_MODEL)));
AbstractContainer container;
if (isJob) {
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);
// 核心点在于JobContainer的对象
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
}
Configuration jobInfoConfig = allConf.getConfiguration(CoreConstant.DATAX_JOB_JOBINFO);
// 核心容器的启动
container.start();
}
说明:
start过程中做了两件事:
- 1、创建JobContainer对象
- 2、启动JobContainer对象
JobContainer的启动过程
public class JobContainer extends AbstractContainer {
/**
* jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler、
* post以及destroy和statistics
*/
@Override
public void start() {
try {
isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);
if(isDryRun) {
// 省略相关代码
} else {
//拷贝一份新的配置,保证线程安全
userConf = configuration.clone();
// 执行preHandle()操作
LOG.debug("jobContainer starts to do preHandle ...");
this.preHandle();
// 执行reader、transform、writer等初始化
LOG.debug("jobContainer starts to do init ...");
this.init();
// 执行plugin的prepare
LOG.info("jobContainer starts to do prepare ...");
this.prepare();
// 执行任务切分
LOG.info("jobContainer starts to do split ...");
this.totalStage = this.split();
// 执行任务调度
LOG.info("jobContainer starts to do schedule ...");
this.schedule();
// 执行后置操作
LOG.debug("jobContainer starts to do post ...");
this.post();
// 执行postHandle操作
LOG.debug("jobContainer starts to do postHandle ...");
this.postHandle();
LOG.info("DataX jobId [{}] completed successfully.", this.jobId);
this.invokeHooks();
}
} catch (Throwable e) {
// 省略相关代码
} finally {
// 省略相关代码
}
}
}
说明:
JobContainer的start方法会执行一系列job相关的操作,如下:
- 1、执行job的preHandle()操作,暂时不关注。
- 2、执行job的init()操作,需重点关注。
- 3、执行job的prepare()操作,暂时不关注。
- 4、执行job的split()操作,需重点关注。
- 5、执行job的schedule()操作,需重点关注。
- 6、执行job的post()和postHandle()操作,暂时不关注。
Job的init过程
public class JobContainer extends AbstractContainer {
private void init() {
this.jobId = this.configuration.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, -1);
if (this.jobId < 0) {
LOG.info("Set jobId = 0");
this.jobId = 0;
this.configuration.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID,
this.jobId);
}
Thread.currentThread().setName("job-" + this.jobId);
// 初始化
JobPluginCollector jobPluginCollector = new DefaultJobPluginCollector(
this.getContainerCommunicator());
//必须先Reader ,后Writer
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
}
private Reader.Job initJobReader(
JobPluginCollector jobPluginCollector) {
// 获取插件名字
this.readerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.readerPluginName));
Reader.Job jobReader = (Reader.Job) LoadUtil.loadJobPlugin(
PluginType.READER, this.readerPluginName);
// 设置reader的jobConfig
jobReader.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
// 设置reader的readerConfig
jobReader.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
jobReader.setJobPluginCollector(jobPluginCollector);
// 这里已经到每个插件具体的初始化操作
jobReader.init();
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobReader;
}
private Writer.Job initJobWriter(
JobPluginCollector jobPluginCollector) {
this.writerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_WRITER_NAME);
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.writerPluginName));
Writer.Job jobWriter = (Writer.Job) LoadUtil.loadJobPlugin(
PluginType.WRITER, this.writerPluginName);
// 设置writer的jobConfig
jobWriter.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
// 设置reader的readerConfig
jobWriter.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
jobWriter.setPeerPluginName(this.readerPluginName);
jobWriter.setJobPluginCollector(jobPluginCollector);
jobWriter.init();
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobWriter;
}
}
说明:
Job的init()过程主要做了两个事情,分别是:
- 1、创建reader的job对象,通过URLClassLoader实现类加载。
- 2、创建writer的job对象,通过URLClassLoader实现类加载。
job的split过程
public class JobContainer extends AbstractContainer {
private int split() {
this.adjustChannelNumber();
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);
LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));
/**
* 输入是reader和writer的parameter list,输出是content下面元素的list
*/
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
LOG.debug("contentConfig configuration: "+ JSON.toJSONString(contentConfig));
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
}
private void adjustChannelNumber() {
int needChannelNumberByByte = Integer.MAX_VALUE;
int needChannelNumberByRecord = Integer.MAX_VALUE;
boolean isByteLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);
if (isByteLimit) {
long globalLimitedByteSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);
Long channelLimitedByteSpeed = this.configuration
.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);
needChannelNumberByByte =
(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);
needChannelNumberByByte =
needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;
LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");
}
boolean isRecordLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;
if (isRecordLimit) {
long globalLimitedRecordSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);
Long channelLimitedRecordSpeed = this.configuration.getLong(
CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);
needChannelNumberByRecord =
(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);
needChannelNumberByRecord =
needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;
}
// 取较小值
this.needChannelNumber = needChannelNumberByByte < needChannelNumberByRecord ?
needChannelNumberByByte : needChannelNumberByRecord;
boolean isChannelLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);
if (isChannelLimit) {
this.needChannelNumber = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
LOG.info("Job set Channel-Number to " + this.needChannelNumber
+ " channels.");
return;
}
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"Job运行速度必须设置");
}
}
说明:
DataX的job的split过程主要是根据限流配置计算channel的个数,进而计算task的个数,主要过程如下:
- 1、adjustChannelNumber的过程根据按照字节限流和record限流计算channel的个数。
- 2、reader的个数根据channel的个数进行计算。
- 3、writer的个数根据reader的个数进行计算,writer和reader实现1:1绑定。
- 4、通过mergeReaderAndWriterTaskConfigs()方法生成reader+writer的task的configuration,至此我们生成了task的配置信息。
Job的schedule过程
public class JobContainer extends AbstractContainer {
private void schedule() {
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
ExecuteMode executeMode = null;
AbstractScheduler scheduler;
try {
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
//设置 executeMode
for (Configuration taskGroupConfig : taskGroupConfigs) {
taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());
}
// 开始调度所有的taskGroup
scheduler.schedule(taskGroupConfigs);
} catch (Exception e) {
// 省略相关代码
}
}
}
说明:
Job的schedule的过程主要做了两件事,分别是:
- 1、将task拆分成taskGroup,生成List<Configuration> taskGroupConfigs。
- 2、启动taskgroup的对象, scheduler.schedule(taskGroupConfigs)。
TaskGroup的schedule过程
public abstract class AbstractScheduler {
public void schedule(List<Configuration> configurations) {
int totalTasks = calculateTaskCount(configurations);
// 启动所有的TaskGroup
startAllTaskGroup(configurations);
try {
while (true) {
// 省略相关代码
}
} catch (InterruptedException e) {
}
}
}
public abstract class ProcessInnerScheduler extends AbstractScheduler {
private ExecutorService taskGroupContainerExecutorService;
@Override
public void startAllTaskGroup(List<Configuration> configurations) {
//todo 根据taskGroup的数量启动固定的线程数
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
//todo 每个TaskGroup启动一个TaskGroupContainerRunner
for (Configuration taskGroupConfiguration : configurations) {
//todo 创建TaskGroupContainerRunner并提交线程池运行
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
// 等待所有任务执行完后会关闭,执行该方法后不会再接收新任务
this.taskGroupContainerExecutorService.shutdown();
}
}
public class TaskGroupContainerRunner implements Runnable {
private TaskGroupContainer taskGroupContainer;
private State state;
public TaskGroupContainerRunner(TaskGroupContainer taskGroup) {
this.taskGroupContainer = taskGroup;
this.state = State.SUCCEEDED;
}
@Override
public void run() {
try {
Thread.currentThread().setName(
String.format("taskGroup-%d", this.taskGroupContainer.getTaskGroupId()));
this.taskGroupContainer.start();
this.state = State.SUCCEEDED;
} catch (Throwable e) {
}
}
}
说明:
TaskGroup的Schedule方法做的事情如下:
- 1、为所有的TaskGroup创建TaskGroupContainerRunner。
- 2、通过线程池提交TaskGroupContainerRunner任务,执行TaskGroupContainerRunner的run()方法。
- 3、在run()方法内部执行this.taskGroupContainer.start()方法。
TaskGroupContainer的启动
public class TaskGroupContainer extends AbstractContainer {
@Override
public void start() {
try {
// 省略相关代码
int taskCountInThisTaskGroup = taskConfigs.size();
Map<Integer, Configuration> taskConfigMap = buildTaskConfigMap(taskConfigs); //taskId与task配置
List<Configuration> taskQueue = buildRemainTasks(taskConfigs); //待运行task列表
Map<Integer, TaskExecutor> taskFailedExecutorMap = new HashMap<Integer, TaskExecutor>(); //taskId与上次失败实例
List<TaskExecutor> runTasks = new ArrayList<TaskExecutor>(channelNumber); //正在运行task
Map<Integer, Long> taskStartTimeMap = new HashMap<Integer, Long>(); //任务开始时间
while (true) {
// 省略相关代码
// 新增任务会在这里被启动
Iterator<Configuration> iterator = taskQueue.iterator();
while(iterator.hasNext() && runTasks.size() < channelNumber){
Configuration taskConfig = iterator.next();
Integer taskId = taskConfig.getInt(CoreConstant.TASK_ID);
int attemptCount = 1;
TaskExecutor lastExecutor = taskFailedExecutorMap.get(taskId);
// todo 需要新建任务的配置信息
Configuration taskConfigForRun = taskMaxRetryTimes > 1 ? taskConfig.clone() : taskConfig;
// todo taskExecutor应该就需要新建的任务
TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun, attemptCount);
taskStartTimeMap.put(taskId, System.currentTimeMillis());
taskExecutor.doStart();
iterator.remove();
runTasks.add(taskExecutor);
}
} catch (Throwable e) {
}finally {
}
}
}
说明:
TaskGroupContainer的内部主要做的事情如下:
- 1、根据TaskGroupContainer分配的Task任务列表,创建TaskExecutor对象。
- 2、创建TaskExecutor对象,用以启动分配该TaskGroup的task。
- 3、至此,已经成功的启动了Job当中的Task任务。
Task的启动
class TaskExecutor {
private Channel channel;
private Thread readerThread;
private Thread writerThread;
private ReaderRunner readerRunner;
private WriterRunner writerRunner;
/**
* 该处的taskCommunication在多处用到:
* 1. channel
* 2. readerRunner和writerRunner
* 3. reader和writer的taskPluginCollector
*/
public TaskExecutor(Configuration taskConf, int attemptCount) {
// 获取该taskExecutor的配置
this.taskConfig = taskConf;
// 得到taskId
this.taskId = this.taskConfig.getInt(CoreConstant.TASK_ID);
this.attemptCount = attemptCount;
/**
* 由taskId得到该taskExecutor的Communication
* 要传给readerRunner和writerRunner,同时要传给channel作统计用
*/
this.channel = ClassUtil.instantiate(channelClazz,
Channel.class, configuration);
// channel在这里生成,每个taskGroup生成一个channel,在generateRunner方法当中生成writer或reader并注入channel
this.channel.setCommunication(this.taskCommunication);
/**
* 获取transformer的参数
*/
List<TransformerExecution> transformerInfoExecs = TransformerUtil.buildTransformerInfo(taskConfig);
/**
* 生成writerThread
*/
writerRunner = (WriterRunner) generateRunner(PluginType.WRITER);
this.writerThread = new Thread(writerRunner,
String.format("%d-%d-%d-writer",
jobId, taskGroupId, this.taskId));
//通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
this.writerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.taskConfig.getString(
CoreConstant.JOB_WRITER_NAME)));
/**
* 生成readerThread
*/
readerRunner = (ReaderRunner) generateRunner(PluginType.READER,transformerInfoExecs);
this.readerThread = new Thread(readerRunner,
String.format("%d-%d-%d-reader",
jobId, taskGroupId, this.taskId));
/**
* 通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
*/
this.readerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.taskConfig.getString(
CoreConstant.JOB_READER_NAME)));
}
public void doStart() {
this.writerThread.start();
this.readerThread.start();
}
}
说明:
TaskExecutor的启动过程主要做了以下事情:
- 1、创建了reader和writer的线程任务,reader和writer公用一个channel。
- 2、先启动writer线程后,再启动reader线程。
- 3、至此,同步数据的Task任务已经启动了。
DataX的数据传输
跟一般的生产者-消费者模式一样,Reader插件和Writer插件之间也是通过channel来实现数据的传输的。channel可以是内存的,也可能是持久化的,插件不必关心。插件通过RecordSender往channel写入数据,通过RecordReceiver从channel读取数据。
channel中的一条数据为一个Record的对象,Record中可以放多个Column对象,这可以简单理解为数据库中的记录和列。
public class DefaultRecord implements Record {
private static final int RECORD_AVERGAE_COLUMN_NUMBER = 16;
private List<Column> columns;
private int byteSize;
// 首先是Record本身需要的内存
private int memorySize = ClassSize.DefaultRecordHead;
public DefaultRecord() {
this.columns = new ArrayList<Column>(RECORD_AVERGAE_COLUMN_NUMBER);
}
@Override
public void addColumn(Column column) {
columns.add(column);
incrByteSize(column);
}
@Override
public Column getColumn(int i) {
if (i < 0 || i >= columns.size()) {
return null;
}
return columns.get(i);
}
@Override
public void setColumn(int i, final Column column) {
if (i < 0) {
throw DataXException.asDataXException(FrameworkErrorCode.ARGUMENT_ERROR,
"不能给index小于0的column设置值");
}
if (i >= columns.size()) {
expandCapacity(i + 1);
}
decrByteSize(getColumn(i));
this.columns.set(i, column);
incrByteSize(getColumn(i));
}
}