
这几天在研究唯一文件名生成与文件特征验证解决方案,之前都是使用MD5算法,但是除了MD5外还有没有其他办法呢?后来无意看到了七牛云的ETag就稍微研究了下。
七牛ETag算法说明:https://developer.qiniu.com/kodo/manual/1231/appendix#qiniu-etag
github:https://github.com/qiniu/qetag
1.算法原理
七牛的 hash/etag 算法是公开的。算法大体如下:
- 小于或等于4M的文件
1. 对文件内容做sha1计算;
+---------------+
| <=4MB |
+---------------+
\ | /
\ sha1() /
\ | /
\ V /
+--+-----+
|1B| 20B | 2. 在sha1值(20字节)前拼上单个字节,值为0x16;
+--+-----+
| |
| \--- 文件内容的sha1值
|
\------ 固定为0x16
3. 对拼接好的21字节的二进制数据做url_safe_base64计算,所得结果即为ETag值。
- 大于4M的文件
1. 对文件内容按4M大小切块;
2. 对每个块做sha1计算;
+----------+----------+-------
| 4MB | 4MB | ...
+----------+----------+-------
\ | | | /
\ sha1() | sha1() /
\ | | | /
\ V | V /
+-----+-----+-------
| 20B | 20B | ...
+-----+-----+-------
\ | /
\ sha1() /
\ | /
\ V /
+--+-----+
|1B| 20B | 3. 对所有的 sha1 值拼接后做二次 sha1,
+--+-----+ 然后在二次 sha1 值前拼上单个字节,值为0x96;
| |
| \---- 二次sha1的值
\------- 固定为0x96
4. 对拼接好的21字节的二进制数据做url_safe_base64计算,所得结果即为ETag值。
- 为何需要公开
hash/etag算法?
这个和 “消重” 问题有关,详细见:如何避免用户上传相同的文件。 - 为何在
sha1值前面加一个字节的标记位0x16或0x96?
0x16 = 22,而 2^22 = 4M。所以前面的0x16其实是文件按 4M 分块的意思。
0x96 = 0x80 | 0x16。其中0x80表示这个文件是大文件(有多个分块),hash值也经过了2重的sha1计算
2.qetag.js使用教程(NodeJS)
前往(https://github.com/qiniu/qetag)下载源码

使用示例:
//demo.js
var getEtag = require("./qetag");
var fs = require("fs")
fs.readFile("文件路径", function (err, buf) {
getEtag(buf, function (v) {
console.log(v);
})
});
/////////或
getEtag("文件路径", function (v) {
console.log(v);
})

3.纯前端JS实现qETag
其实我们已经知道原理和NodeJS的源文件了我们只要稍微改一下就可以了
完整源码在:https://gitee.com/baojuhua/lutils/blob/master/others/qetag.js
1.sha1算法
-
我们观察源码可以发现sha1算法使用NodeJS内置的crypto库实现

-
我用https://github.com/emn178/js-sha1来代替,像这样

2.Uint8Array与原生Array来替代Buffer操作
- 我们观察源码中的Buffer操作

- 我们稍微改一下,用Uint8Array与原生Array替代Buffer

3.完整源码
- qetag.js
function getEtag(buffer, callback) {
// sha1算法
var shA1 = sha1.digest;
// 以4M为单位分割
var blockSize = 4 * 1024 * 1024;
var sha1String = [];
var prefix = 0x16;
var blockCount = 0;
var bufferSize = buffer.size || buffer.length || buffer.byteLength;
blockCount = Math.ceil(bufferSize / blockSize);
for (var i = 0; i < blockCount; i++) {
sha1String.push(shA1(buffer.slice(i * blockSize, (i + 1) * blockSize)));
}
function concatArr2Uint8(s) {//Array 2 Uint8Array
var tmp = [];
for (var i of s) tmp = tmp.concat(i);
return new Uint8Array(tmp);
}
function Uint8ToBase64(u8Arr, urisafe) {//Uint8Array 2 Base64
var CHUNK_SIZE = 0x8000; //arbitrary number
var index = 0;
var length = u8Arr.length;
var result = '';
var slice;
while (index < length) {
slice = u8Arr.subarray(index, Math.min(index + CHUNK_SIZE, length));
result += String.fromCharCode.apply(null, slice);
index += CHUNK_SIZE;
}
return urisafe ? btoa(result).replace(/\//g, '_').replace(/\+/g, '-') : btoa(result);
}
function calcEtag() {
if (!sha1String.length) return 'Fto5o-5ea0sNMlW_75VgGJCv2AcJ';
var sha1Buffer = concatArr2Uint8(sha1String);
// 如果大于4M,则对各个块的sha1结果再次sha1
if (blockCount > 1) {
prefix = 0x96;
sha1Buffer = shA1(sha1Buffer.buffer);
} else {
sha1Buffer = Array.apply([], sha1Buffer);
}
sha1Buffer = concatArr2Uint8([[prefix], sha1Buffer]);
return Uint8ToBase64(sha1Buffer, true);
}
return (calcEtag());
}
4.使用示例
- demo.html
<!-- https://github.com/emn178/js-sha1 -->
<script src="./sha1.js"></script>
<script src="./qetag.js"></script>
<script>
function fload(input) {
var fs = input.files;
if (fs.length) {
var f = fs[0];
var reader = new FileReader();
reader.onload = function () {
document.getElementById("etagDemo").innerHTML = getEtag(this.result);
}
reader.readAsArrayBuffer(f);
}
}
</script>
<input id="f" type="file" onchange="fload(this)" />
<div id="etagDemo"></div>
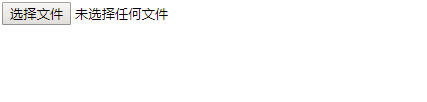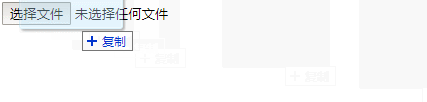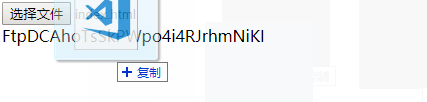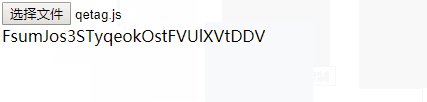
效果


