

xgboost中文叫做极致梯度提升模型,官方文档链接:https://xgboost.readthedocs.io/en/latest/tutorials/model.html
2018年9月6日笔记
IDE(Intergrated development Environment),集成开发环境为jupyter notebook
操作系统:Win10
语言及其版本:python3.6
此项目的难点在于pandas的熟练使用、机器学习模型快速开发和部署。
0.打开jupyter notebook
在桌面新建文件夹风力发电机叶片结冰分类预测,按钮如下图所示:
在文件夹 风力发电机叶片结冰分类预测中打开 PoweShell。
在文件夹中 按住Shift键的情况下,点击鼠标右键,出现如下图所示:

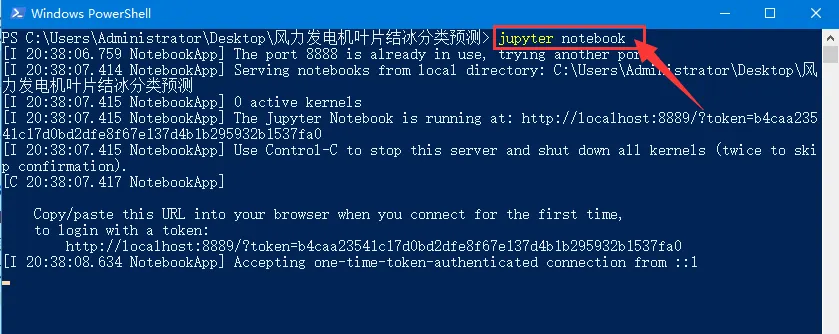
点击上图中的 在此处打开PowerShell窗口,在其中输入命令并运行: jupyter notebook
运行命令后会自动打开浏览器窗口,新建代码文件,如下图所示:

aerogenerator中文叫做 风力发电机;
vane中文叫做 叶片。
代码文件重命名为 aerogeneratorVane,重命名文件 按钮位置如下图所示:
1.加载数据
数据集下载链接: https://pan.baidu.com/s/15NsGA1fvDlmQdxww_xBXZg 密码: 8sn8
下载文件为zip压缩文件,里面含有3个csv文件:data.csv、failure.csv、normal.csv
data.csv文件是带有所有特征字段的数据集;
failure.csv文件是风力发电机叶片故障时间段,时间段包括2个字段:开始时间startTime、结束时间endTime;
normal.csv文件是风力发电机叶片正常时间段,时间段包括2个字段:开始时间startTime、结束时间endTime。
3个文件要放到代码文件同级目录下。
1.1 pd.read_csv方法加载数据
载入data.csv文件并观察数据代码如下:
import pandas as pd
data_df = pd.read_csv('data.csv', parse_dates=['time'])
print(data_df.shape)
data_df.head()

1.2 利用pickle保存数据集
安装pickle库命令:pip install pickle
import pickle
with open('data_df.pickle', 'wb') as file:
pickle.dump(data_df, file)
1.3 利用pickle加载数据集
import pickle
with open('data_df.pickle', 'rb') as file:
data_df = pickle.load(file)
1.4 对比2种加载方法
import time
startTime = time.time()
data_df = pd.read_csv('data.csv', parse_dates=['time'])
readcsv_time = time.time() - startTime
print('readcsv time: %.2f seconds' %readcsv_time)
startTime2 = time.time()
with open('data_df.pickle', 'rb') as file:
data_df = pickle.load(file)
pickleLoad_time = time.time() - startTime2
print('pickleLoad time: %.3f seconds' %pickleLoad_time)
print('pickleLoad_time / readcs_time = %.3f' %(pickleLoad_time/readcsv_time))
上面一段代码的运行结果如下:
readcsv time: 4.37 seconds
pickleLoad time: 0.11 seconds
pickleLoad_time / readcs_time = 0.025
从上面的运行结果可以看出,利用pickle加载数据花费时间是pd.read_csv方法加载数据花费时间的0.025倍。
利用pickle库可以保存python中的任何对象,在数据科学实践中可以用来保存重要的模型和数据。
2.观察数据
2.1 查看数据集大小
data_df.shape
运行结果如下:
(393886, 28)
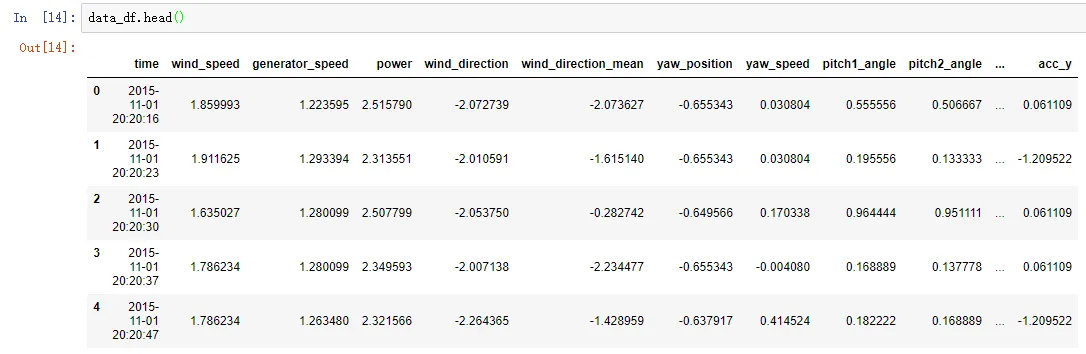
2.2 查看数据集前5行
data_df.head()
上面一段代码的运行结果如下图所示:
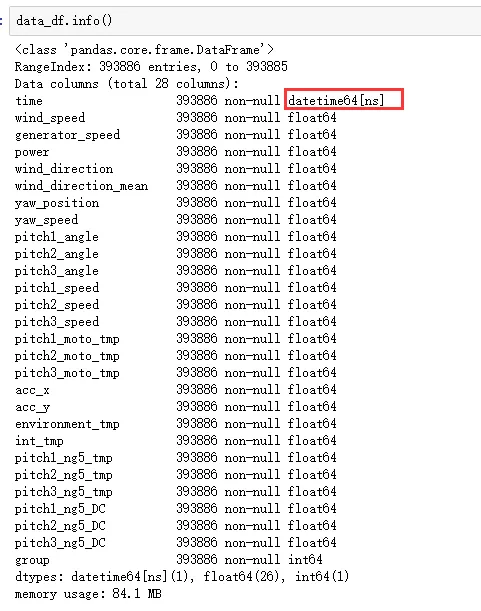
2.3 查看数据字段空缺情况
data_df.info()
读者应该查看变量data_df的time字段是否和下图一样是datetime64的数据类型。
上面一段代码的运行结果如下图所示:
3.数据处理
3.1 获取时间段
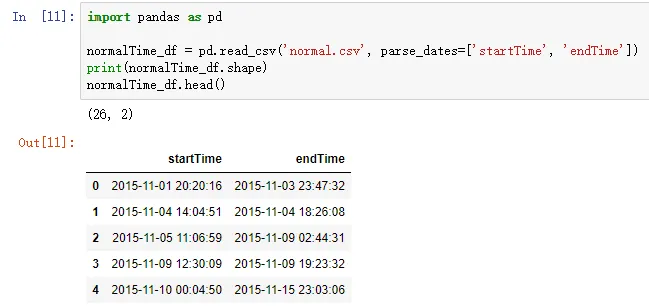
import pandas as pd
normalTime_df = pd.read_csv('normal.csv', parse_dates=['startTime', 'endTime'])
print(normalTime_df.shape)
normalTime_df.head()
上面一段代码的运行结果如下图所示:
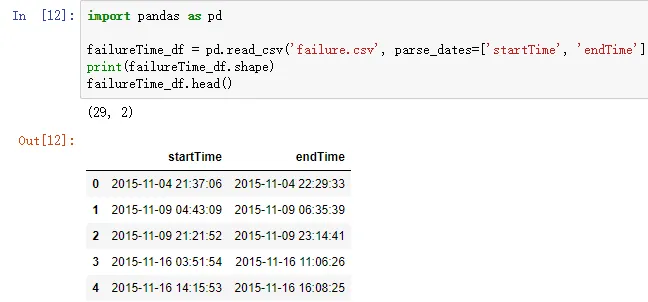
import pandas as pd
failureTime_df = pd.read_csv('failure.csv', parse_dates=['startTime', 'endTime'])
print(failureTime_df.shape)
failureTime_df.head()
上面一段代码的运行结果如下图所示:
3.2 取出预测目标值为正常的样本
import pandas as pd
normal_list = []
for index in normalTime_df.index:
startTime = normalTime_df.loc[index].startTime
endTime = normalTime_df.loc[index].endTime
part_df = data_df[data_df.time.between(startTime, endTime)]
print(part_df.shape)
normal_list.append(part_df)
normal_df = pd.concat(normal_list).reset_index(drop=True)
normal_df.shape
上面一段代码的运行结果如下图所示:

3.3 取出预测目标值为故障的样本
import pandas as pd
failure_list = []
for index in failureTime_df.index:
startTime = failureTime_df.loc[index].startTime
endTime = failureTime_df.loc[index].endTime
part_df = data_df[data_df.time.between(startTime, endTime)]
print(part_df.shape)
failure_list.append(part_df)
failure_df = pd.concat(failure_list).reset_index(drop=True)
failure_df.shape
上面一段代码的运行结果如下图所示:

3.4 统计正常、故障、无效样本占比
stat_df = pd.DataFrame({
'number' : [normal_df.shape[0], failure_df.shape[0], data_df.shape[0]-normal_df.shape[0]-failure_df.shape[0]]
}, index = ['normal', 'failure', 'invalid'])
stat_df['ratio'] = stat_df['number'] / stat_df['number'].sum()
stat_df
上面一段代码的运行结果如下图所示:

3.5 下采样
因为预测目标值为正常的样本远远多于预测目标值为故障的样本,所以对预测目标值为正常的样本做下采样。
下采样指减少样本或者减少特征,具体方法是选取一部分正常样本,数量为故障样本的2倍。
import random
normalPart_df = normal_df.loc[random.sample(list(normal_df.index), k=failure_df.shape[0]*2)]
normalPart_df.shape
上面一段代码的运行结果如下:
(47784, 28)
3.6 形成特征矩阵和预测目标值
iimport numpy as np
feature_df = pd.concat([normalPart_df, failure_df]).reset_index(drop=True)
X = feature_df.drop('time', axis=1).values
print(X.shape)
y = np.append(np.ones(len(normalPart_df)), np.zeros(len(failure_df)))
print(y.shape)
上面一段代码的运行结果如下:
(71676, 27)
(71676,)
3.7 保存数据
安装pickle库命令:pip install pickle
import pickle
with open('X.pickle', 'wb') as file:
pickle.dump(X, file)
with open('y.pickle', 'wb') as file:
pickle.dump(y, file)
4.模型训练
4.1 数据准备
作者提供可以pickle库加载的数据文件,下载链接: https://pan.baidu.com/s/1r9eVzROI0pKKXYdnhf031g 密码: nciu
下载后解压是3.7节保存数据的两个文件X.pickle和y.pickle。
安装pickle库命令:pip install pickle
加载数据的代码如下:
import pickle
with open('X.pickle', 'rb') as file:
X = pickle.load(file)
with open('y.pickle', 'rb') as file:
y = pickle.load(file)
4.2 随机森林模型
第5行代码初始化模型对象,参数n_jobs设置为-1时,会最大化利用电脑的多线程性能;
第6行代码实例化交叉验证对象,参数n_splits设置为5,表示会做5折交叉验证;
第7行代码调用cross_val_score方法,第1个参数为模型对象,第2个参数为特征矩阵X,第3个参数为预测目标值y,第4个关键字参数cv的数据类型为整数或交叉验证对象,方法的返回结果的数据类型为ndarray对象;
第8行代码,ndarray对象的round方法可以使其中的数保留指定位数。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
rfc_model = RandomForestClassifier(n_jobs=-1)
cv_split = ShuffleSplit(n_splits=5)
score_ndarray = cross_val_score(rfc_model, X, y, cv=cv_split)
print(score_ndarray.round(4))
print(score_ndarray.mean().round(4))
上面一段代码的运行结果如下:
[0.9997 0.9999 0.9999 1. 0.9999]
0.9999
4.3 xgboost模型
xgboost中文叫做极致梯度提升模型,安装xgboost命令:pip install xgboost
第6行代码忽略警告信息;
第7行代码初始化模型对象,参数nthread设置为4时,利用4线程做模型训练;
第8行代码实例化交叉验证对象,参数n_splits设置为5,表示会做5折交叉验证;
第9行代码调用cross_val_score方法,第1个参数为模型对象,第2个参数为特征矩阵X,第3个参数为预测目标值y,第4个关键字参数cv的数据类型为整数或交叉验证对象,方法的返回结果的数据类型为ndarray对象;
第10行代码,ndarray对象的round方法可以使其中的数保留指定位数。
from xgboost import XGBClassifier
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
import warnings
warnings.filterwarnings('ignore')
xgb_model = XGBClassifier(nthread=4)
cv_split = ShuffleSplit(n_splits=5)
score_ndarray = cross_val_score(xgb_model, X, y, cv=cv_split)
print(score_ndarray.round(4))
print(score_ndarray.mean().round(4))
上面一段代码的运行结果如下:
[0.9831 0.983 0.9805 0.9814 0.9862]
0.9828
5.模型评估
5.1 模型得分
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
xgb_model = XGBClassifier(thread=8)
xgb_model.fit(train_X, train_y)
xgb_model.score(test_X, test_y).round(4)
上面一段代码的运行结果如下:
0.9812
5.2 混淆矩阵
from sklearn.metrics import confusion_matrix
predict_y = xgb_model.predict(test_X)
labels = ['故障', '正常']
pd.DataFrame(confusion_matrix(test_y, predict_y), columns=labels, index=labels)
上面一段代码的运行结果如下图所示:

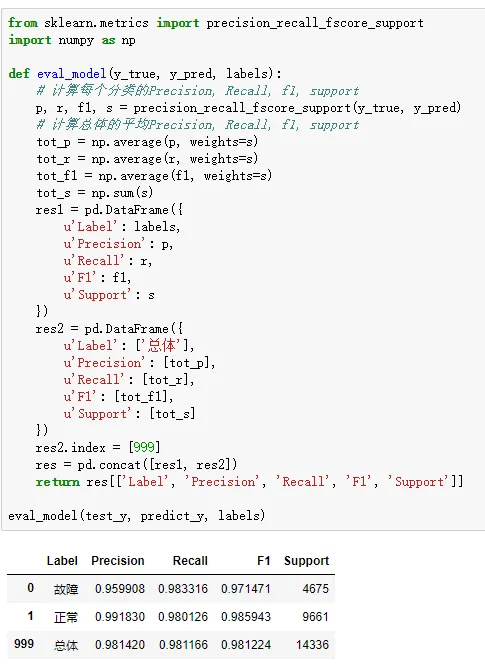
5.3 precision、recall、f1-score、support报告表
from sklearn.metrics import precision_recall_fscore_support
import numpy as np
def eval_model(y_true, y_pred, labels):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
# 计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
eval_model(test_y, predict_y, labels)
上面一段代码的运行结果如下图所示:
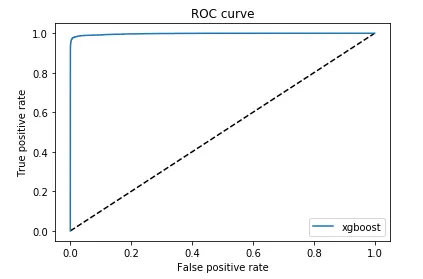
5.4 绘制ROC曲线
from sklearn.metrics import roc_curve
predict_y_probability = xgb_model.predict_proba(X)
false_predict, true_predict, thresholds = roc_curve(y, predict_y_probability[:,1])
import matplotlib.pyplot as plt
plt.plot([0,1], [0,1], 'k--')
plt.plot(false_predict, true_predict, label='xgboost')
plt.legend()
plt.title('ROC curve')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.show()
上面一段代码的运行结果如下图所示:
5.5 模型保存
利用pickle库的dump方法保存
import pickle
with open('xgb_model.pickle', 'wb') as file:
pickle.dump(xgb_model, file)
6.模型测试
6.1 模型加载
模型下载链接: https://pan.baidu.com/s/1Itt2kVbZYwBIJc9TyLzp6g 密码: uh55
利用pickle库的load方法加载模型
import pickle
with open('xgb_model.pickle', 'rb') as file:
xgb_model = pickle.load(file)
6.2 测试数据准备
测试数据下载链接: https://pan.baidu.com/s/1llzPfg6ynPXBs2fn-ou4_Q 密码: ddhm
下载压缩文件解压后为data_test.df文件,用文本文件形成特征矩阵和预测目标值。
预测目标值是clf字段,查看clf字段的统计计数情况,如下图所示:

预测目标值为0的样本标签值是故障;
预测目标值为1的样本标签值是正常;
预测目标值为2的样本标签值为无效。
所以保留标签值时故障和正常的样本,去除无效样本。
test_df = pd.read_csv('data_test.csv', index_col=0)
y = test_df['clf'].values
X = test_df.drop(['time', 'clf'], axis=1).values
X = X[y<2]
print(X.shape)
y = y[y<2]
print(y.shape)
上面一段代码的运行结果如下:
(179567, 27)
(179567,)
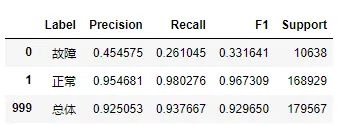
6.3 绘制precision、recall、f1-score、support报告表
from sklearn.metrics import precision_recall_fscore_support
import numpy as np
def eval_model(y_true, y_pred, labels):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
# 计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
predict_exam_y = xgb_model.predict(exam_X)
labels = ['故障', '正常']
eval_model(exam_y, predict_exam_y, labels)
上面一段代码的运行结果如下图所示:
7.总结
0.代码文件下载链接: https://pan.baidu.com/s/1HidM93l2DBPyKo8pURitgA 密码: yk1w
1.模型在原数据集经过交叉验证取得了优秀的评估指标;
2.模型在正常样本的预测中取得很高的查准率和查全率;
3.模型在故障样本的预测中取得很低的查准率和查全率;
4.模型在新数据集的测试效果差,说明模型泛化能力差,想要提高模型的泛化能力,则需要提取出更多数据中的有效特征。



