产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
开发者社区
首页
探索云世界
探索云世界
云上快速入门,热门云上应用快速查找
了解更多
问产品
动手实践
考认证
TIANCHI大赛
活动广场
活动广场
丰富的线上&线下活动,深入探索云世界
任务中心
做任务,得社区积分和周边
高校计划
让每位学生受益于普惠算力
训练营
资深技术专家手把手带教
话题
畅聊无限,分享你的技术见解
开发者评测
最真实的开发者用云体验
乘风者计划
让创作激发创新
阿里云MVP
遇见技术追梦人
直播
技术交流,直击现场
下载
下载
海量开发者使用工具、手册,免费下载
镜像站
极速、全面、稳定、安全的开源镜像
技术资料
开发手册、白皮书、案例集等实战精华
插件
为开发者定制的Chrome浏览器插件
探索云世界
新手上云
云上应用构建
云上数据管理
云上探索人工智能
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
热门
Modelscope模型即服务
弹性计算
云原生
数据库
物联网
云效DevOps
龙蜥操作系统
平头哥
钉钉开放平台
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
支持服务
镜像站
码上公益
开发者社区
数据库
文章
正文
2.3 MultiOp和Pipeline支持有限
2018-02-27
1493
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议
》和 《
阿里云开发者社区知识产权保护指引
》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单
进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
因为Redis Cluster自动数据Sharding的缘故,MultiOp和Pipeline都被限定在命令中的所有Key必须都在同一Slot内。如果想突破这个限定该怎么办?那扩展Jedis或者在Proxy中实现命令拆分和结果聚合的逻辑。
本文作者:geelou
本文来自云栖社区合作伙伴rediscn,了解相关信息可以关注redis.cn网站。
文章标签:
Java
NoSQL
Redis
玄学酱
目录
相关文章
追逐时光者
|
7月前
|
NoSQL
API
调度
.NET开源的轻量化定时任务调度,支持临时的延时任务和重复循环任务(可持久化) - FreeScheduler
.NET开源的轻量化定时任务调度,支持临时的延时任务和重复循环任务(可持久化) - FreeScheduler
追逐时光者
105
0
0
必嘫
|
4月前
|
缓存
Cloud Native
调度
Fluid支持分层数据缓存本地性调度(Tiered Locality Scheduling)
依赖容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的 AI 与大数据应用在其上部署和运行。但是数据密集型应用计算框架的设计理念和云原生灵活的应用编排的分歧,导致了数据访问和计算瓶颈。 CNCF开源项目Fluid作为 AI 与大数据云原生应用提供一层高效便捷的数据抽象,将数据从存储抽象出来,针对具体的场景(比如大模型),加速计算访问数据。
必嘫
743
0
0
金九
|
10月前
|
存储
算法
区块链
铜锁支持 Bulletproofs 算法
背景零知识证明(ZKP,Zero Knowledge Proof)是隐私计算和区块链领域中非常重要的密码学技术,能够在证明者不向验证者提供任何有用信息的情况下,使验证者相信某个论断是正确的。零知识证明于1985 年提出,至今30多年,但目前主流的零知识证明算法仅有 zk-SNARKs、zk-STARKs 和 Bulletproofs,其中 zk-SNARKs 于 2013 年提出,因其常数级的验证
金九
207
0
0
倪桦
|
10月前
|
机器学习/深度学习
移动开发
数据挖掘
R语言- data.table包加速大型数据集的加载和运算效率用法示例
本文根据个人使用经验和博客参考,总结分享了在R语言中使用data.table包来提升大型数据集处理效率的用法示例,以供参考
倪桦
172
0
0
技术小达人
|
存储
并行计算
API
【TVM 学习资料】用 Schedule 模板和 AutoTVM 优化算子
【TVM 学习资料】用 Schedule 模板和 AutoTVM 优化算子
技术小达人
144
0
0
Deephub
|
数据可视化
算法
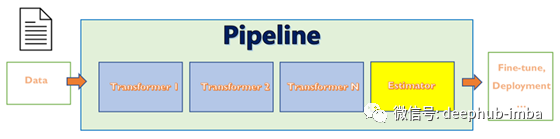
使用Scikit-Learn pipeline 减少ML项目的代码量并提高可读性(下)
使用Scikit-Learn pipeline 减少ML项目的代码量并提高可读性
Deephub
98
0
0
Deephub
|
机器学习/深度学习
安全
测试技术
使用Scikit-Learn pipeline 减少ML项目的代码量并提高可读性(上)
使用Scikit-Learn pipeline 减少ML项目的代码量并提高可读性
Deephub
91
0
0
前端歌谣
ts重点学习91-分布式条件类型
ts重点学习91-分布式条件类型
前端歌谣
76
0
0
前端歌谣
ts重点学习92-分布式条件类型笔记
ts重点学习92-分布式条件类型笔记
前端歌谣
69
0
0
NebulaGraph
|
存储
分布式计算
NoSQL
Nebula Graph 在大规模数据量级下的实践和定制化开发
国内主流互联网公司如何解决图数据库的挑战呢?除了自研之外,还可以选择 Nebula Graph 进行图数据库实践。在本文中,你将了解到如何进行 Nebula Graph 的深度定制。
NebulaGraph
714
0
0
热门文章
最新文章
1
Mac安装并使用telnet命令操作
2
OSS回源的几种方式和应用场景
3
[剑指offer] 孩子们的游戏(圆圈中最后剩下的数)
4
网络安全系列之二十二 Windows用户账号加固
5
我理解的一个程序员如何学习前端开发
6
《社交网站界面设计(原书第2版)》——1.9 为设备之间的空间进行设计
7
《Microduino实战》——1.2 为什么要开源
8
.Net函数Math.Round你会用吗?
9
麻省理工大学新发明:暗黑WiFi透视技术
10
2014秋C++第19周 补充代码 哈希法的存储与查找
1
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
25
2
R语言近似贝叶斯计算MCMC(ABC-MCMC)轨迹图和边缘图可视化
21
3
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现-4
31
4
Sentieon | 每周文献-Multi-omics-第四十一期
26
5
数据分享|R语言广义线性模型GLM:线性最小二乘、对数变换、泊松、二项式逻辑回归分析冰淇淋销售时间序列数据和模拟-2
16
6
数据分享|R语言广义线性模型GLM:线性最小二乘、对数变换、泊松、二项式逻辑回归分析冰淇淋销售时间序列数据和模拟-1
23
7
基于RT-Thread摄像头车牌图像采集系统
22
8
R语言极值理论:希尔HILL统计量尾部指数参数估计可视化
17
9
【视频】R语言中的分布滞后非线性模型(DLNM)与发病率,死亡率和空气污染示例
22
10
sql语句创建数据库
18
相关课程
更多
如何使用Kubernetes监控定位慢调用
相关电子书
更多
《Pulsar 2.8.0 功能特性概述及规划》
千万Feeds流系统的存储技术揭秘
为并行图数据处理提供高层抽象/语言
相关实验场景
更多
使用Count功能批量创建资源
下一篇
部署LAMP环境(Alibaba Cloud Linux 3)