内部节点方案。大部分公司的做法都是lvs+keepalived
几个厂商的不同作法:
1.pptv keepalived+nginx+squid+ts 节点灵活性比较高,小节点多机房,30左右节点数量,70台左右的机器
2.迅雷 lvs+keepalived+ts+squid lvs是公用的,其他业务也会用到(机房业务比较多)
3.京东 lvs+keepalived+haproxy+squid 大几点,20几个机房,500台左右的机器
4.新浪 lvs+keepalived+nginx+ts. 40左右节点,都算大节点。每节点数量在30台左右,利用率80%
5.淘宝 lvs+keepalived+haproxy+ts 大节点,多服务,ssd。。。流量超大。
准备采用的Cdn整体结构及内部结构:
1)gslb,全局负载均衡使用三方智能dns解析,控制用户到cdn节点的调度(cloudxns,支持到城市的调度,收费1999/(域名/年))
2)lslb(本地负载均衡):
方案1:
4层使用lvs+keepalived,7层使用nginx,这样就可以保证4层到7层的高可用性和扩展性,单节点最少需要5个公网IP,4台机器
方案2:
4层使用keepalived, 7层使用nginx,单节点最少需要4个公网IP,2台机器,对比方案1的缺点是不能支持4层-----7层的检测(即,机器挂掉可以实现auto failover,nginx挂掉不能)
Cache系统使用apache traffic server(对比squid,响应更快,性能更强)。
3)cdn节点到源站回源使用bind+lvs(每个bind集群至少需要4台机器,现节点对回源dns的ha要求不高,可以暂时不考虑ha),构建回源dns的高可用。
4)源站构建在双线核心机房,用来保证网通和电信各自的回源质量(目前条件不允许)
5)也可以在cdn节点和源站直接构建2cache(测试阶段可以电信,网通各一个),来缓解源站的压力(这个也是需要的,之前在pptv出现过边缘回源压垮源站的问题,如果能够在2cache有效缓存,就可以避免这种情况)
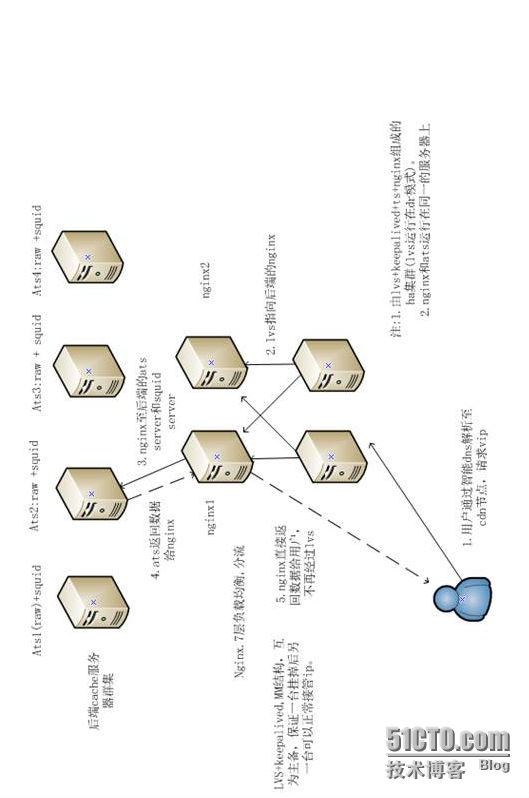
提供下方案1的Lvs+keepalived的结构图:
几点说明:
1.js,jpg,swf,gif等缓存时间比较长的,object size比较大的文件类型通过ats缓存,使用ats的raw来优化io。
2.html,xml的文件缓存时间比较短,使用squid做缓存,squid只使用内存做缓存。

附ats的一些性能指标:
1.ats vs squid 性能对比
今天review了下ts的性能表现,由于使用了多线程异步处理模型和分离的各个模块子系统,ts的性能要优于squid很多。从响应时间上来看,相同的请求数量下,ts减少了3倍(由0.04s减少至0.01s),而且响应时间趋于平稳。
下面为具体的数据(只取upstream add含有127.0.0.1:8080的访问记录,即proxy到ts的访问记录。sql不再列举)
取切换前后webcdn机器访问数据,环比12.20,12.06,12.13的数据来看。
1).访问量
12.6号的访问量和12.20号的访问量趋势相当

2.)平均响应时间:
更换成ts后,响应时间明显降低,由12.6号的。0.04s左右降低至0.01s,而且整体趋势比较平稳,在流量高峰时响应时间也未见大幅增加。而更换ts之前的数据显示,在12点-13点,18点-20点的流量高峰时,响应时间都较正常时段有所增加。

12.20号数据环比一天情况
整体的响应时间,13点左右,squid转成ts,平均响应时间降低至0.01s左右。

zabbix监控图:

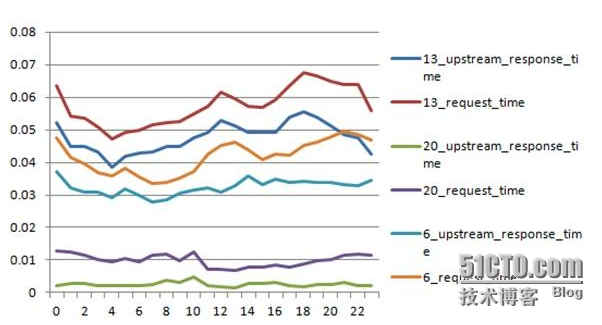
相同访问量的情况下,squid和ats响应时间对比(都未到达瓶颈),ts很平稳。比squid也低不少
rt,,urt:
(可以看到nginx的request_time也有两个高峰,相反ts倒是很平稳)

nginx-proxy交互使用的时间:
(有两个明显的高峰,后端squid的响应没有这么明显的变化,应该是nginx--squid的交互问题,比如长连接的支持,连接的复用)

切换前后响应时间对比图:

2. ats raw vs ext3 io性能对比
相同流量下Tps,rtps,wtps的结果
Tps的比例是ram:ext3=1:2.45,从趋势图上也可看出,使用raw时,io是比较稳定和集中的,而使用ext3文件系统时,由于会有buffer flush的行为,Io会每隔一段时间出现高峰值,不会稳定。
raw:
平均tps:98.59
平均wtps:50.32
平均rtps:48.27
ext3:
平均tps:241.99
平均rtps:144.61
平均wtps:97.38

响应时间对比
从ts的upstream的时间来看,ts在raw 和ext3两种情况下,响应时间变化不大,也比较平稳。
nginx request time在高峰期时变化比较明显
Avg-upstream_time avg_request_time (type):
0.0024 0.0090 (ext3)
0.0026 0.0093 (raw)

目前结论:Ts 使用raw的情景下,会有效的减低io的操作数,减少io的消耗,比例是ram:ext3=1:2.45,ts的响应速度上基本没有变化。按现在的cdn节点压力来看,io还没有到达性能的瓶颈,所以可以暂不考虑raw的方案,如果以后机器的压力上去了,io成为瓶颈的话,可以将ext3换成raw.












{kind=link}
{kind=link}