
谁能想到,NIPS这种顶会都能风波乍起。
Ali Rahimi(阿里·拉希米),因为2007年发表的一篇论文,获得今年的“Test of Time”最具时间价值大奖。当然,阿里作为最佳论文作者理所应当的登台演讲。

起初,这个演讲主要介绍之前的研究成果。阿里说从很多方面来讲,我们的状况都比10年前好多了。在技术上,取得了很大的进步,街上跑着自动驾驶汽车,人工智能可以干很多事情……基于机器学习技术,能产生出几十亿美元的公司。
后来,火药味逐渐浓烈起来,阿里朝着整个深度学习界开了一枪,他说:
但某些方面更糟糕了。

空气中飘荡着一种自鸣得意的感觉,我们会说“人工智能是新的电力”。(安德鲁老师最爱的说法)
我想换个比方:机器学习已经成了炼金术。

炼金术挺好的,炼金术没毛病,它自有它的地位,炼金术“管用”。

炼金术带来了冶金、纺织、现代玻璃制造工艺、医疗等等领域的发明。但同时,炼金术还相信水蛭能治病,廉价金属能变成金子。
从当年的炼金术到现在的物理、化学,到我们现在对宇宙的认识,科学家们要消解掉2000年的炼金术理论。
如果你要做个照片分享系统,用“炼金术”就行。但我们现在所做的远远超出了这个范围,我们所做的系统用在医疗领域,用在社交媒体上,甚至能影响大选。
我希望我所生活的世界里,这些系统都建立在严格、周密、可验证的知识之上,而不是基于“炼金术”。
我有点怀念十年前NIPS上质疑各种想法够不够严谨的“学术警察”,希望他们回来。
(不关心技术细节的可以跳过下面的例子)
举个例子,不知道你有没有经历过这样的情况:从零开始搭建、训练了一个神经网络,然后发现它不管用的时候,总觉得是自己的错。这种状况我大约每三个月就要经历一次,我想说,这不是你的错,是梯度下降的错。
比如说这个最简单的深度神经网络,两层线性网络:
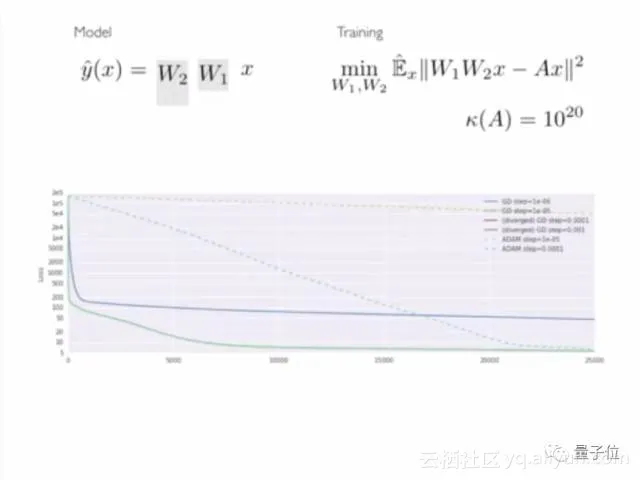
左边是我的模型,右边是损失函数,底下是不同参数设置下梯度下降的过程。有时候loss一开始下降得很快,后来就不动了。你可能会觉得遇到了局部最小值,或者鞍点,loss和0相差还很远。
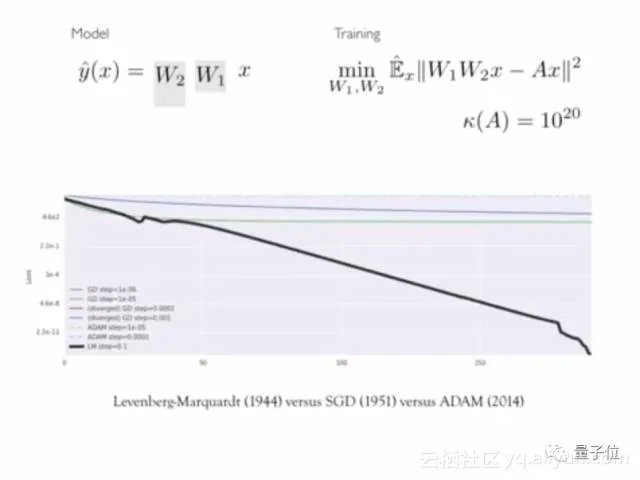
换一个下降的方向,很快就能优化到最低。
你可能会觉得这个例子不自然,或者说梯度下降在更大的神经网络上表现得不错,我的回答是:第一,很多人都被梯度下降坑过;第二,我们把自己的工具用在简单的例子上,从中学习知识,然后应用到更复杂的场景,这正符合我们建立知识的方式。
梯度下降带来的痛苦是真实存在的。
上个月,我的朋友Boris给我发了封邮件:

周五,另一个组有人改动了TensorFlow内部的默认舍入模式,从“舍到0”改成了“四舍五入到偶数”。
我们的训练就崩溃了,误差从<25%飙升到了~99.97%。
这样的邮件我收到过不少,网上也有人在讨论类似的问题。
会发生这种情况,是因为我们把脆弱的优化技巧用到了我们不理解的loss上, 我们的解决方案在本来就已经很神秘的技术上增加了更多神秘性。
Batchnorm是加速梯度下降的一种方法,把Batchnorm插入到深度神经网络的层中,梯度下降的速度就会更快。
我不排斥使用一些自己不懂的技术,比如说我是坐飞机来的,并不完全清楚它的工作原理,但知道有整个航空界都在研究这项技术就很安心了。
而对于Batchnorm的工作原理,我们只知道它的功能是“reducing internal covariate shift”。

可是为什么这样就能加速梯度下降了?有没有相关的理论或者实验?你甚至都不清楚internal covariate shift是什么,就不想要一个定义吗?
Batchnorm已经成了构建深度神经网络的一个基础工具,但我们对它几乎一无所知。
想想过去一年里你为了刷竞赛榜单而做的实验、尝试的新技术;再想想过去一年里你为了解释奇怪现象、寻找其根源而做的努力。前者,我们做得很多,后者,我们应该再多做一些。简单的实验和理论是帮我们理解复杂系统的基础。
我们还有一件事可以做。现在,所有商用硬件上运行的成熟计算引擎都是梯度下降的变体,处理着数百亿的变量。
想象一下,如果我们有能在标准商用硬件上运行,处理数百亿变量线性解算器或者矩阵分解引擎,想象一下这样我们能做出多好的优化算法,用多好的模型来做实验,当然,这在数学上和系统上都很难,但这正是我们要解决的问题。
我对这个圈子有真挚的爱,这也是为什么我会站在这儿,号召大家更严格精确,别那么像炼金术师。
希望我们可以共同努力,将机器学习从“炼金术”变成“电力”。
完整演讲,参见下面这段视频:
LeCun:实名反对
一石激起千层浪,阿里的演讲引发了热烈的讨论。
深度学习专家、前谷歌大脑成员Denny Britz说:“对很多人来说,这是NIPS的高光时刻。深度学习就像炼金术,我们不知道发生了什么。我们需要在这个领域更加严谨。如果你知道背后没有可靠的科学理论,你会坐上飞机么?”
当然也有人立刻抛出不同意见。比如号称“三巨头”之一的Yann LeCun。他在Facebook上发表了一篇“长篇大论”进行了阐释。

原文概要如下:
阿里发表了一个有趣的演讲,但我压根不同意他说的话。他的核心思想是说:机器学习(ML)现在的实践,类似于“炼金术”(他的原话)。
这是种侮辱,是的。但是不要担心:他是错的。
阿里抱怨目前ML使用的许多方法,缺乏(理论上)的理解,尤其是在深度学习领域。理解是好事,这也是NIPS群体中很多人追求的目标。
但另一个更重要的目标是发明新的方法、新的技术,以及新的技巧(tricks)。
翻看科学技术发展的历史,工程实践总是先于理论理解出现:透镜和望远镜先于光学理论,蒸汽机先于热动力学,飞机先于空气动力学,无线电和数据通信先于信息理论,计算机先于计算机科学。
因此只是因为目前理论工具还没赶上实践,就批评整个ML群体(还是个相当成功的群体)在搞“炼金术”,这是一个非常危险的行为。
为什么说危险?因为正是这种态度,曾让ML群体抛弃神经网络超过10年,尽管有充分的证据表明他们在很多情况下效果很好。具有非凸损失函数的神经网络不能保证收敛。所以人们连婴儿带洗澡水一起泼掉了。
只是因为可以进行理论研究就固守一套方法,而且还忽视另一套从经验上来说更好的方法,仅仅是因为还没有从理论上理解它?
是的,我们需要更好的理解我们所用的方法。但是,正确的态度应该是尝试去解决问题,而不是因为还没解决就跑去羞辱整个群体。
致阿里:你每天也在用这些方法,如果你对如何理解他们不满意,请动手研究深度学习的理论,而不是抱怨其他人没做,更不是建议NIPS世界只用“理论正确”的方法。这是错的。

阿里随后跟帖回复:
Yann,感谢你深思熟虑的反馈。你最后的让我进行理论研究的建议,正是Moritz Hardt一年前曾对我说的话。只是一小群人很难取得进步,老实说,我被这个任务的规模压得喘不过气来。这次的演讲也是寻求更多人的帮助。
我呼吁简单的实验和简单的定力,以便我们都可以毫无困惑的传达见解。你可能已经非常擅长建立深度模型,在这方面你的经验可能比几乎任何人都多。但是想象一下新手会有怎样的困惑,一切看起来都像魔术。大家谈论的都是整个模型如何工作,而不是每一个小部分在干什么。
我认同炼金术的方法很重要。这让我们加速向前,解决了眼前的问题。我对那些能迅速建立起直觉以及可工作系统的人怀有最深的敬意。你和我在Google的许多同事都有这样令人印象深刻的技能,但你们只是少数。
我呼吁你们不但授人以鱼,而且还授人以渔,让大家都能达到你的生产力水平。我所期望的“严谨”是:简单的实验,简单的定理。
LeCun再回复:
简单和通用理论很好。
热力学的原则,让我们免于浪费时间去寻找永动机。在ML领域我们已经有这样的理论,适用于所有的学习机器,包括神经网络。
但是很有可能不会有专注于神经网络的“简单”定理,原因类似于我们没有纳维-斯托克斯方程或者三体问题的解析解。
背景交代
Ali Rahimi,去年5月加入Google,目前担任Member of Technical Staff(这个职位类似于主任工程师)。2005-2011年期间,他供职于英特尔担任研究员。
这次被NIPS 2017评为最佳时间检验奖的论文《Random Features for Large-Scale Kernel Machines》,就是他在英特尔期间发表的。
1997年,阿里在UC Berkeley获得学士学位,随后在MIT获得硕士和博士学位。
如果你对他感兴趣,可以看看他的个人主页。在欣赏了他的女友、兄弟和女朋友们的照片后,量子位感觉这也是一个“逗逼型”科学家。
主页地址:https://keysduplicated.com/~ali/Personal.html

炼金术又是啥?
根据维基和百度百科,炼金术(Alchemy)的目标,是想把“贱金属”炼制成“贵金属”,比方把铅变成黄金。(当然还有炼丹,想造出长生不老药)。包括牛顿也曾研究过这门技术。不过现代化学证明,这种方法是行不通的。
OMT
以上,就是这次NIPS大会上关于真理标准的大讨论。
最后推荐一款应景的T恤,就是下面这款啦
在国外的服装定制平台Teespring有售,如果你对这件T恤感兴趣,而且熟悉海外购物流程,在量子位微信账号(QbitAI)回复:“炼”一个字,就能获得购买地址。
— 完 —


