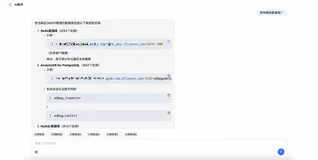
/************************************************************
* Time: 2010-10-07 13:23:32
* 找出有索引的表信息(表名行数堆集群非聚集)
************************************************************/
WITH cte AS
(
SELECT table_name = o.name,
o.[object_id],
i.index_id,
i.type,
i.type_desc
FROM sys.indexes i
INNER JOIN sys.objects o
ON i.[object_id] = o.[object_id]
WHERE o.type IN ('U')
AND o.is_ms_shipped = 0
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND i.type <= 2
), cte2 AS
(
SELECT *
FROM cte c
PIVOT(
COUNT(TYPE) FOR type_desc IN ([HEAP], [CLUSTERED], [NONCLUSTERED])
) pv
)
SELECT c2.table_name,
[rows] = MAX(p.rows),
is_heap = SUM([HEAP]),
is_clustered = SUM([CLUSTERED]),
num_of_nonclustered = SUM([NONCLUSTERED])
FROM cte2 c2
INNER JOIN sys.partitions p
ON c2.[object_id] = p.[object_id]
AND c2.index_id = p.index_id
GROUP BY
table_name
--没有索引的表
SELECT NAME
FROM sys.tables
WHERE OBJECTPROPERTY(OBJECT_ID, 'TableHasIndex') = 0

问题:
'pivot' 附近有语法错误。您可能需要将当前数据库的兼容级别设置为更高的值,以启用此功能
解决:
EXEC sp_dbcmptlevel stat ,90 --stat 为数据库名称
本文转自曾祥展博客园博客,原文链接:http://www.cnblogs.com/zengxiangzhan/archive/2010/10/07/1845094.html,如需转载请自行联系原作者