
科学家使用大脑成像技术绘制了一幅地图,让我们清楚看到大脑不同区域如何表征 958 个常见英语词汇及其含义。揭开这个谜题会有意想不到的回报:通过观察大脑活动,就能知道你在想什么。

英语词典按照字母顺序排列出所有常用英文单词,人类大脑又是如何储存这些词汇的呢?解开这个谜题的回报将是巨大的:通过观察大脑活动,就能知道你正在想什么。
神经科学家们一直都在研究「读心术」,试图解码大脑信息。
伯克利大学 Brian Pasley 等人曾试图解码人类自忖时的语词。在治疗癫痫病人的过程中,研究人员将电极植入大脑颞叶,记录病人听人说话时大脑的活动情况。他们发现, 颞叶只会被声音的某些方面激活,比如特殊的频率。以此为基础,伯克利的研究人员设计了一套算法,仅以神经活动为基础,解码人类自忖时的语词。(当然,前提是假设自忖和听别人说话会激发一些相同的神经信号。这样,用以识别听到语词的算法,也能用来解码自忖时的语词。)
在荷兰,马斯特里赫特大学 Joao Correia 等人的「读心术」研究已经证实,大脑某个区域会对特定词汇做出反应。
伯克利大学神经科学家 Jack Gallant 自己的实验室也巳经发现,大脑会根据意义类别,比如动物或建筑物,对视觉信息进行分类。
但是,大脑究竟如何安置词汇和概念——这是通往清楚解读人类思想的关键一步——仍然模糊不清。
这正是Jack Gallant 及其研究团队想要征服的下一个高峰。是否能够在大脑皮层,这个灰色物质褶皱的外层,绘制出更加完整的语义地图,看看大脑各区域如何对具有类似语义内容的词汇做出反应?不同受试的语义地图是否存在类似地方?Jack Gallant 表示,希望能在大脑处于自然状态时,完成所有这些研究工作。
他们做到了。
在最新一期《Nature》封面文章《Semantic information in natural narrative speech is represented in complex maps that tile human cerebral cortex》中, Jack Gallant 和他的团队(Gallant 认知、计算和系统神经科学实验室)终于成功绘制出大脑语义地图(985 个英语常用词汇语义)。我们可以清楚看到大脑如何根据更深一层的词汇含义,将词汇安置到诸如数字、地点或其他基于共通主题的子类别当中。
方法和过程
为了绘制出语义地图,研究人员请来 7 位受试倾听 The Moth Radio Hour 里的故事。在受试听故事时,科学家使用 fMRI(功能性磁共振成像)记录下大脑血氧水平的变化——一种神经活动的信号。然后,将故事文本的词汇意义与脑部活动数据进行对比,看看相关词汇组如何在 5—8 万个豌豆大小位置(遍及整个大脑皮层)引发神经反应。
论文第一作者 Alexander Huth 之所以采用 The Moth Radio 里面的故事,是因为它们既短小又吸引人。故事越迷人,科学家们就越有自信:接受脑部扫描测试的受试没有走神。7 个人,每个人要听 2 个小时的故事,大致要听 25,000 个词汇(words)——以及 3,000 多个不同词汇(words)。
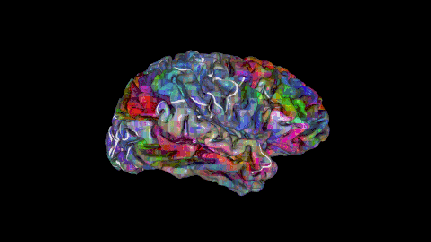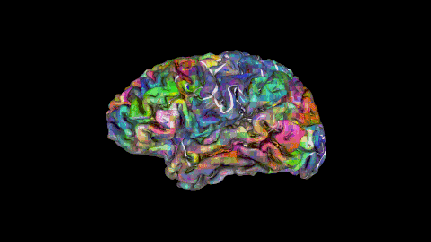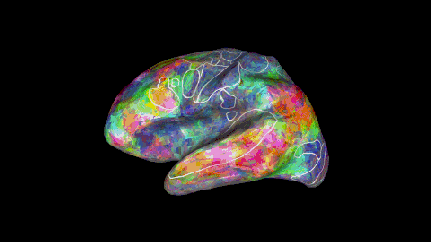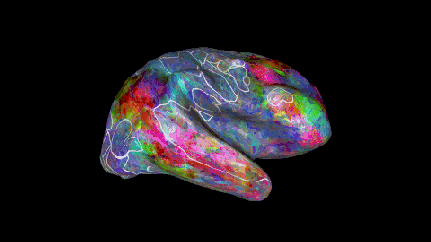
如同覆盖在大脑皮层上的彩色被子,这幅地图作品用彩虹般的色彩描绘出大脑如何将单个词汇及其传达的概念分组。
讲述故事过程中,研究人员也会转录下故事,并记录下读出每个单词的时间。然后,研究人员利用 fMRI 数据和记录下来的故事文本,建立计算模型,根据受试者听到词汇的函数来预测大脑活动。为了验证这些模型,研究人员利用它们来预测大脑对新故事的 fMRI 反应。结果发现,这些模型能够相对良好地预测几个宽阔大脑皮层区域的反应。
接下来,研究人员试图发现皮层每个点所代表的语义信息类型。为了将相当高维度的语义模型视觉化,他们使用了一种叫做主要成分分析(principal components analysis , PCA)的降维技术。PCA 会找出数据中最重要的维度,这样,研究人员就可以将 985 —维的模型降到只有三维,同时还能尽可能多的保存住信息。利用这三个维度,研究人员大致视觉化出皮层每个地方所代表的语义信息类型,揭示出覆盖在大脑表面上的复杂语义地图。
最后,为了发现这些地图中的哪些方面是所有受试所共享的,他们采用了一种新的叫做 PrAGMATiC(一个概率和生成模型)的计算方法。这种方法可以找出受试共享的功能区域,同时也能容许每个区域解剖学位置上存在个体差异。
研究发现
结果显示,词汇及相关术语(terms)都激活了大脑同一个区域。比如,大脑左边,耳朵以上,这块小面积区域代表着单词「受害人(victim)」。 这块区域也对 「杀害(killed)」, 「宣告有罪(convicted)」,「谋杀(murdered)」和「认罪(confessed)」有反应。大脑右侧,近头部顶端,也是会对以下词汇产生反应的大脑位置之一:「妻子」、「丈夫」、「孩子」、「父母」。

人的大脑右半球。当从上下文听到覆盖在皮层上的语词时,可以预测出这些语词会在相应区域附近引发强烈反应。绿色词汇几乎都是视觉和触觉方面的词汇,红色词汇与社交有关。
代表每个词汇的大脑位置不止一处,因为词汇往往不止一个含义。比如,大脑有个部分,会可靠地对「顶部(top)」做出反应,也会对其他描绘衣服的单词做出反应(top 也有上衣的意思)。但是,单词「顶部(top)」也激活了许多大脑其他区域。其中一个区域还会对数字和度量单词做出反应(top 也有最大、最高之意),另一个区域与建筑(top 表示顶层)和地点相关。
由此可见,并不存在一个单独的大脑区域来储存一个词汇或者概念。大脑中,一个单独的位置与许多相关词汇存在联系。而且,每一个单独词汇会点亮许多不同的大脑位置。它们一起,形成了一张网络,这张网络代表着我们使用中每个词汇语义:生命与爱;死亡和税收;云彩,佛罗里达和胸罩。研究人员一共识别出12个簇群(clusters),每个簇群都保存着与特定概念相应的语词。
另外,研究人员惊讶发现:所有受试大脑地图是类似的,这意味着,他们的大脑以相同的方式组织词汇意思。不过,科学家仅扫描了五位男士与两位女士。所有受试均以英语为母语。拥有不同背景和文化的人,很可能会有不同的大脑语义地图。

三位不同受试的语义地图,不同颜色分布存在相似性
研究还发现,语言网络占用的大脑区域非常广阔,并不局限于少数几个区域。而且,语义表征是高度双边的,具有功能对称性:在对语词做出回应的大小和多变方面,大脑右半球和左半球是一样的。这一发现对当前教条提出了挑战。根据几十年来对脑部受损患者的研究,当前教条认为,语言仅与左半球有关。
对研究的评价
帝国理工的神经学家 Richard Wise 说,长期以来,科学家一直怀疑语词被储存在大脑的意义云中。因此,这项研究结果并非真的让人惊讶。

剑桥大学语音、语言和大脑研究中心(Centre for Speech, Language and the Brain )负责人、认知神经科学家 Lorraine Tyler 说,在广度和方法上,这项研究堪称杰作。但是,目前这种形式的大脑地图并没有捕捉到词语意思的微妙区别。以 「table 」这个词为例。它可能属于许多不同语义组。「它可以指用来吃东西的东西,用木头做的东西,很重的东西,有四条腿的东西,不会动的东西,等等。词汇能够得以灵活运用,离不开这类细节的语义信息,但是,在分析过程中,这类信息被丢掉了。」
普林斯顿的神经科学家 Uri Hasson 对这项研究表示赞赏。他指出,许多研究观察的是,说出一个孤立的词汇或句子时,大脑活动情况如何。和这些研究不同,Gallant 研究小组的成果揭示出大脑在真实世界情景中的运作方式。Hasson 相信,最终,根据大脑活动,重现一个人正在想着的词汇,是有可能的。另外,他也指出,这项研究的道德应用问题影响很大。一个更加良性的使用方法是,通过观察大脑活动,评估某些政治信息是否被有效地传递给公众。
波士顿大学的 Swathi Kiran表示,「我们正苦于那些不漂亮、不够整齐以及受损的大脑,这篇文章告诉我们正常大脑的样子。」该研究有助于人们了解诸如老年痴呆症或失语症患者的语言缺损现象。总之,正如 Hasson 所说,「研究的应用方式很多,我们仅触及其表面。」
值得一提的是,这项研究也有方法上的重要贡献。研究人员开发出数据驱动方法,它们对恢复详细的语义地图足够敏感。有了这种方法,研究人员就能高效绘制出许多不同语义信息类型的地图。这些方法也能被用于绘制其他与语言有关的信息地图,比如,语素信息。
同时,这篇论文采用的数据驱动方法,也进一步推动了认知神经科学领域中,数据驱动型研究方法(也是人类神经解剖学和功能连接研究中常见的方法)与传统、基于假设的实验研究方法之争。作为同行,Uri Hasson 对新方法欣然接受,「做科学研究,并不只有一种方法。」
下一步
人类语言是一种复杂信号,包含多种不同信息类型:音素(phonemes)、词素(morphemes)、句法(syntax)、语义和叙述,等等。在对叙事语言的自然理解过程中,大脑必须处理这些所有的不同方面。因此,语言的每一个不同方面都要在大脑某处表现出来。
目前,研究团队已经开始研究新的地图:大脑如何保存语言其他方面的信息,从音素到句法(syntax)。不过,到目前为止,大脑叙述结构地图还是难以捉摸。「每次想到一套叙述特征,我们就被告知这些不是正确的叙述特征组。」



