
上一次说了一下要支持无限级的动态加载TreeView控件,服务器端数据的准备情况。不过那只是一个小小的演示实例,在实际的使用中,服务器端的数据可能会完全的不同,不过不管怎么变化,也必须要保证能形成树形数据的request/response结构。
由于TreeView必须在加载了节点信息有才能被Show出来,所以这里我们先手动把root level的节点生成。代码示例如下:
 <
script
Language
="javascript"
>
<
script
Language
="javascript"
>
 </
script
>
</
script
>
这里需要注意的是我们在此使用的是同步xmlhttp方式去获取的root level的数据,为什么这里不用异步呢?这是由我们的节点关系决定的,在 第一节里我就说过,这个TreeView的每一层,其实是一个独立的Tree,然后在节点TreeNode下挂接Tree,就形成无限级的结构了。而当我们在获取root level的数据时,还没有TreeNode这个东西。我们使用同步连接,可以保证原数据获取的顺序。当然在子节点的动态展开中,我们使用得是异步xmlhttp获取的数据。
当我们在Expand一个TreeNode时,如果这个节点的IsLazyLoad属性是true,那么执行代码:
 TreeNode.prototype.LoadNodes =
function()
TreeNode.prototype.LoadNodes =
function()
{
var childTree =
this.m_Element.nextSibling;
childTree.style.display = 'inline';
this.m_IsChildExpanded =
true;
this.m_Element.OpIcon.src = TreeStyle.OpIcon(
this.GetOpIconName());
childTree.cells(1).innerHTML = '<img src="' + TreeStyle.OpIcon('BottomLine')
+ '" border="0" align="absMiddle"><span style="color:blue;">loading
</span>';
var url =
this.Attributes('Url') + '?NID=' +
this.m_ServerId
+ '&CID=' +
this.m_Id + '&t=' +
new Date().getTime();
__XmlHttpPool__.GetRemoteData(url,
this.LoadingNodes);
};
在上面的调用中,url是类似如下的一个请求:
http://localhost/TreeView/GetTreeNodes.aspx?NID=1&CID=__TreeObject__11&t=12349803
NID是NodeId,CID是ClientId,t是一个时间戳(用来绕开IE的cache机制)。
返回的数据,上次也都说过了,形如:
__TreeObject__11$[
["2", "DV作品", "-1", "Mar 22 10:28", "2"],
["5", "大陆", "-1", "Apr 2 02:01 ", "9"],
["14", "港台", "-1", "Apr 2 02:02 ", "34"],
["63", "欧美", "-1", "Apr 2 01:50 ", "174"],
["80", "日韩", "-1", "Apr 2 01:53 ", "226"]]
在我们的xmlhttp的回调函数中,我们主要做三件事情:
1、找到本次返回数据的Parent Node,就是说这些数据是谁的子节点;
2、根据返回的数据生成子树,然后把子树append到Parent Node上;
3、更新Parent Node和Child Tree中的属性状态值,比如:m_ChildTree、m_ParentNode等。
参考代码如下:
TreeNode.prototype.LoadingNodes =
function(metadata)
{
try
{
var clientId = metadata.substring(0, metadata.indexOf('$'));
var data = metadata.substring(metadata.indexOf('$')+1);
var aryData = eval(data);
var tree =
new Tree();
for (
var i=0 ; i < aryData.length ; ++i )
{
//
["1","Movie","-1","Mar 29 07:23", "1"],
var aryNode = aryData[i];
var node =
new TreeNode(aryNode[1]);
if ( aryNode[0] != -1 )
{
node.m_IsLazyLoad =
true;
}
node.m_ServerId = aryNode[4];
tree.Add(node);
}
var objNode = __GlobalTreeCache__[clientId];
objNode.m_ChildTree = tree;
objNode.m_Tree.ApplySingleton();
objNode.m_IsLazyLoad =
false;
tree.m_ParentNode = objNode;
var childTree = objNode.m_Element.nextSibling;
var childNode = childTree.cells(1);
childNode.innerHTML = '';
childNode.appendChild(tree.Render(childTree.document));
}
catch(e)
{
__Debug(e, metadata);
}
};
由于TreeView必须在加载了节点信息有才能被Show出来,所以这里我们先手动把root level的节点生成。代码示例如下:
<
script
Language
="javascript"
>
</
script
>
这里需要注意的是我们在此使用的是同步xmlhttp方式去获取的root level的数据,为什么这里不用异步呢?这是由我们的节点关系决定的,在 第一节里我就说过,这个TreeView的每一层,其实是一个独立的Tree,然后在节点TreeNode下挂接Tree,就形成无限级的结构了。而当我们在获取root level的数据时,还没有TreeNode这个东西。我们使用同步连接,可以保证原数据获取的顺序。当然在子节点的动态展开中,我们使用得是异步xmlhttp获取的数据。
当我们在Expand一个TreeNode时,如果这个节点的IsLazyLoad属性是true,那么执行代码:
TreeNode.prototype.LoadNodes =
function()
{
var childTree =
this.m_Element.nextSibling;
childTree.style.display = 'inline';
this.m_IsChildExpanded =
true;
this.m_Element.OpIcon.src = TreeStyle.OpIcon(
this.GetOpIconName());
childTree.cells(1).innerHTML = '<img src="' + TreeStyle.OpIcon('BottomLine')
+ '" border="0" align="absMiddle"><span style="color:blue;">loading
</span>';
var url =
this.Attributes('Url') + '?NID=' +
this.m_ServerId
+ '&CID=' +
this.m_Id + '&t=' +
new Date().getTime();
__XmlHttpPool__.GetRemoteData(url,
this.LoadingNodes);
};
在上面的调用中,url是类似如下的一个请求:
http://localhost/TreeView/GetTreeNodes.aspx?NID=1&CID=__TreeObject__11&t=12349803
NID是NodeId,CID是ClientId,t是一个时间戳(用来绕开IE的cache机制)。
返回的数据,上次也都说过了,形如:
__TreeObject__11$[
["2", "DV作品", "-1", "Mar 22 10:28", "2"],
["5", "大陆", "-1", "Apr 2 02:01 ", "9"],
["14", "港台", "-1", "Apr 2 02:02 ", "34"],
["63", "欧美", "-1", "Apr 2 01:50 ", "174"],
["80", "日韩", "-1", "Apr 2 01:53 ", "226"]]
在我们的xmlhttp的回调函数中,我们主要做三件事情:
1、找到本次返回数据的Parent Node,就是说这些数据是谁的子节点;
2、根据返回的数据生成子树,然后把子树append到Parent Node上;
3、更新Parent Node和Child Tree中的属性状态值,比如:m_ChildTree、m_ParentNode等。
参考代码如下:
TreeNode.prototype.LoadingNodes =
function(metadata)
{
try
{
var clientId = metadata.substring(0, metadata.indexOf('$'));
var data = metadata.substring(metadata.indexOf('$')+1);
var aryData = eval(data);
var tree =
new Tree();
for (
var i=0 ; i < aryData.length ; ++i )
{
//
["1","Movie","-1","Mar 29 07:23", "1"],
var aryNode = aryData[i];
var node =
new TreeNode(aryNode[1]);
if ( aryNode[0] != -1 )
{
node.m_IsLazyLoad =
true;
}
node.m_ServerId = aryNode[4];
tree.Add(node);
}
var objNode = __GlobalTreeCache__[clientId];
objNode.m_ChildTree = tree;
objNode.m_Tree.ApplySingleton();
objNode.m_IsLazyLoad =
false;
tree.m_ParentNode = objNode;
var childTree = objNode.m_Element.nextSibling;
var childNode = childTree.cells(1);
childNode.innerHTML = '';
childNode.appendChild(tree.Render(childTree.document));
}
catch(e)
{
__Debug(e, metadata);
}
};
// 在类似这样的callback函数中,一般是不会有this出现的,因为这是的this指代的是window。
本来步骤2是比较麻烦的,但是由于我们在获取子节点的metadata时,同时把节点的Client ID也发到了服务器端。服务器返回时又将其原样返回了,所以我们只需要用这个Client ID,并且借助TreeView的全局Cache,很容易就能得到这个节点:var objNode = __GlobalTreeCache__[clientId];。
使用这样一个子节点的装载方式,可以非常sexy的利用异步操作同时加载多个子节点数据(只要的鼠标点击足够快![]() )。同时load多个子节点的效果如下图:
)。同时load多个子节点的效果如下图:
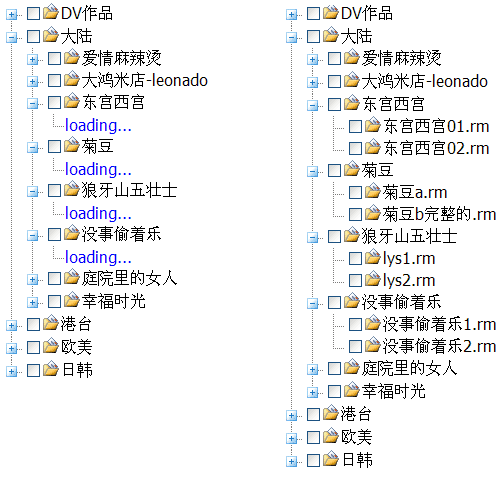
注:关于__XmlHttpPool__参看这里。
本文转自博客园鸟食轩的博客,原文链接:http://www.cnblogs.com/birdshome/,如需转载请自行联系原博主。


