
前言
前情回顾:上一篇我们遗留了两个问题,一个是未完全实现断点续传,另外则是在响应时是返回StreamContent还是PushStreamContent呢?这一节我们重点来解决这两个问题,同时就在此过程中需要注意的地方一并指出,若有错误之处,请指出。
StreamContent compare to PushStreamContent
我们来看看StreamContent代码,如下:
public class StreamContent : HttpContent { // Fields private int bufferSize; private Stream content; private bool contentConsumed; private const int defaultBufferSize = 0x1000; private long start; // Methods public StreamContent(Stream content); ] public StreamContent(Stream content, int bufferSize); protected override Task<Stream> CreateContentReadStreamAsync(); protected override void Dispose(bool disposing); private void PrepareContent(); protected override Task SerializeToStreamAsync(Stream stream, TransportContext context); protected internal override bool TryComputeLength(out long length); // Nested Types private class ReadOnlyStream : DelegatingStream {......} }
似乎没有什么可看的,但是有一句话我们需要注意,如下:
private const int defaultBufferSize = 0x1000;
在StreamContent的第二个构造函数为
public StreamContent(Stream content, int bufferSize);
上述给定的默认一次性输入到缓冲区大小为4k,这对我们有何意义呢?当我们写入到响应中时,一般我们直接利用的是第一个构造函数,如下:
var response = new HttpResponseMessage(); response.Content = new StreamContent(fileStream);
到这里我们明白了这么做是有问题的,当下载时默认读取的是4k,如果文件比较大下载的时间则有延长,所以我们在返回时一定要给定缓冲大小,那么给定多少呢?为达到更好的性能最多是80k,如下:
private const int BufferSize = 80 * 1024; response.Content = new StreamContent(fileStream, BufferSize);
此时下载的速度则有很大的改善,有人就说了为何是80k呢?这个问题我也不知道,老外验证过的,这是链接【.NET Asynchronous stream read/write】。
好了说完StreamContent,接下来我们来看看PushStreamContent,从字面意思来为推送流内容,难道是充分利用了缓冲区吗,猜测可以有,就怕没有任何想法,我们用源码来证明看看。
我们只需看看WebHost模式下对于缓冲策略是怎么选择的,我们看看此类 WebHostBufferPolicySelector 实现,代码如下:
/// <summary> /// Provides an implementation of <see cref="IHostBufferPolicySelector"/> suited for use /// in an ASP.NET environment which provides direct support for input and output buffering. /// </summary> public class WebHostBufferPolicySelector : IHostBufferPolicySelector { ....../// <summary> /// Determines whether the host should buffer the <see cref="HttpResponseMessage"/> entity body. /// </summary> /// <param name="response">The <see cref="HttpResponseMessage"/>response for which to determine /// whether host output buffering should be used for the response entity body.</param> /// <returns><c>true</c> if buffering should be used; otherwise a streamed response should be used.</returns> public virtual bool UseBufferedOutputStream(HttpResponseMessage response) { if (response == null) { throw Error.ArgumentNull("response"); } // Any HttpContent that knows its length is presumably already buffered internally. HttpContent content = response.Content; if (content != null) { long? contentLength = content.Headers.ContentLength; if (contentLength.HasValue && contentLength.Value >= 0) { return false; } // Content length is null or -1 (meaning not known). // Buffer any HttpContent except StreamContent and PushStreamContent return !(content is StreamContent || content is PushStreamContent); } return false; } }
从上述如下一句可以很明显的知道:
return !(content is StreamContent || content is PushStreamContent);
除了StreamContent和PushStreamContent的HttpContent之外,其余都进行缓冲,所以二者的区别不在于缓冲,那到底是什么呢?好了我们还未查看PushStreamContent的源码,我们继续往下走,查看其源代码如下,我们仅仅只看关于这个类的描述以及第一个构造函数即可,如下:
/// <summary> /// Provides an <see cref="HttpContent"/> implementation that exposes an output <see cref="Stream"/> /// which can be written to directly. The ability to push data to the output stream differs from the /// <see cref="StreamContent"/> where data is pulled and not pushed. /// </summary> public class PushStreamContent : HttpContent { private readonly Func<Stream, HttpContent, TransportContext, Task> _onStreamAvailable; /// <summary> /// Initializes a new instance of the <see cref="PushStreamContent"/> class. The /// <paramref name="onStreamAvailable"/> action is called when an output stream /// has become available allowing the action to write to it directly. When the /// stream is closed, it will signal to the content that is has completed and the /// HTTP request or response will be completed. /// </summary> /// <param name="onStreamAvailable">The action to call when an output stream is available.</param> public PushStreamContent(Action<Stream, HttpContent, TransportContext> onStreamAvailable) : this(Taskify(onStreamAvailable), (MediaTypeHeaderValue)null) { }
...... }
对于此类的描述大意是:PushStreamContent与StreamContent的不同在于,PushStreamContent在于将数据push【推送】到输出流中,而StreamContent则是将数据从流中【拉取】。
貌似有点晦涩,我们来举个例子,在webapi中我们常常这样做,读取文件流并返回到响应流中,若是StreamContent,我们会如下这样做:
response.Content = new StreamContent(File.OpenRead(filePath));
上面的释义我用大括号着重括起,StreamContent着重于【拉取】,当响应时此时将从文件流写到输出流,通俗一点说则是我们需要从文件流中去获取数据并写入到输出流中。我们再来看看PushStreamContent的用法,如下:
XDocument xDoc = XDocument.Load("cnblogs_backup.xml", LoadOptions.None); PushStreamContent xDocContent = new PushStreamContent( (stream, content, context) => { xDoc.Save(stream); stream.Close(); }, "application/xml");
PushStreamContent着重于【推送】,当我们加载xml文件时,当我们一旦进行保存时此时则会将数据推送到输出流中。
二者区别在于:StreamContent从流中【拉取】数据,而PushStreamContent则是将数据【推送】到流中。
那么此二者应用的场景是什么呢?
(1)对于下载文件我们则可以通过StreamContent来实现直接从流中拉取,若下载视频流此时则应该利用PushStreamContent来实现,因为未知服务器视频资源的长度,此视频资源来源于别的地方。
(2)数据量巨大,发送请求到webapi时利用PushStreamContent。
当发送请求时,常常序列化数据并请求webapi,我们可能这样做:
var client = new HttpClient(); string json = JsonConvert.SerializeObject(data); var response = await client.PostAsync(uri, new StringContent(json));
当数据量比较小时没问题,若数据比较大时进行序列化此时则将序列化的字符串加载到内存中,鉴于此这么做不可行,此时我们应该利用PushStreamContent来实现。
var client = new HttpClient(); var content = new PushStreamContent((stream, httpContent, transportContext) => { var serializer = new JsonSerializer(); using (var writer = new StreamWriter(stream)) { serializer.Serialize(writer, data); } }); var response = await client.PostAsync(uri, content);
为什么要这样做呢?我们再来看看源码,里面存在这样一个方法。
protected override Task SerializeToStreamAsync(Stream stream, TransportContext context);
其内部实现利用异步状态机实现,所以当数据量巨大时利用PushStreamContent来返回将会有很大的改善,至此,关于二者的区别以及常见的应用场景已经叙述完毕,接下来我们继续断点续传问题。
断点续传改进
上一篇我们讲过获取Range属性中的集合通过如下:
request.Headers.Range
我们只取该集合中的第一个范围元素,通过如下
RangeItemHeaderValue range = rangeHeader.Ranges.First();
此时我们忽略了返回的该范围对象中有当前下载的进度
range.From.HasValue
range.To.HasValue
我们获取二者的值然后进行重写Stream实时读取剩余部分,下面我们一步一步来看。
定义文件操作接口
public interface IFileProvider { bool Exists(string name); FileStream Open(string name); long GetLength(string name); }
实现该操作文件接口
public class FileProvider : IFileProvider { private readonly string _filesDirectory; private const string AppSettingsKey = "DownloadDir"; public FileProvider() { var fileLocation = ConfigurationManager.AppSettings[AppSettingsKey]; if (!String.IsNullOrWhiteSpace(fileLocation)) { _filesDirectory = fileLocation; } } /// <summary> /// 判断文件是否存在 /// </summary> /// <param name="name"></param> /// <returns></returns> public bool Exists(string name) { string file = Directory.GetFiles(_filesDirectory, name, SearchOption.TopDirectoryOnly) .FirstOrDefault(); return true; } /// <summary> /// 打开文件 /// </summary> /// <param name="name"></param> /// <returns></returns> public FileStream Open(string name) { var fullFilePath = Path.Combine(_filesDirectory, name); return File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read); } /// <summary> /// 获取文件长度 /// </summary> /// <param name="name"></param> /// <returns></returns> public long GetLength(string name) { var fullFilePath = Path.Combine(_filesDirectory, name); return new FileInfo(fullFilePath).Length; } }
获取范围对象中的值进行赋值给封装的对象
public class FileInfo { public long From; public long To; public bool IsPartial; public long Length; }
下载控制器,对文件操作进行初始化
public class FileDownloadController : ApiController { private const int BufferSize = 80 * 1024; private const string MimeType = "application/octet-stream"; public IFileProvider FileProvider { get; set; } public FileDownloadController() { FileProvider = new FileProvider(); } ...... }
接下来则是文件下载的逻辑,首先判断请求文件是否存在,然后获取文件的长度
if (!FileProvider.Exists(fileName)) { throw new HttpResponseException(HttpStatusCode.NotFound); } long fileLength = FileProvider.GetLength(fileName);
将请求中的范围对象From和To的值并判断当前已经下载进度以及剩余进度
private FileInfo GetFileInfoFromRequest(HttpRequestMessage request, long entityLength) { var fileInfo = new FileInfo { From = 0, To = entityLength - 1, IsPartial = false, Length = entityLength }; var rangeHeader = request.Headers.Range; if (rangeHeader != null && rangeHeader.Ranges.Count != 0) { if (rangeHeader.Ranges.Count > 1) { throw new HttpResponseException(HttpStatusCode.RequestedRangeNotSatisfiable); } RangeItemHeaderValue range = rangeHeader.Ranges.First(); if (range.From.HasValue && range.From < 0 || range.To.HasValue && range.To > entityLength - 1) { throw new HttpResponseException(HttpStatusCode.RequestedRangeNotSatisfiable); } fileInfo.From = range.From ?? 0; fileInfo.To = range.To ?? entityLength - 1; fileInfo.IsPartial = true; fileInfo.Length = entityLength; if (range.From.HasValue && range.To.HasValue) { fileInfo.Length = range.To.Value - range.From.Value + 1; } else if (range.From.HasValue) { fileInfo.Length = entityLength - range.From.Value + 1; } else if (range.To.HasValue) { fileInfo.Length = range.To.Value + 1; } } return fileInfo; }
在响应头信息中的对象ContentRangeHeaderValue设置当前下载进度以及其他响应信息
private void SetResponseHeaders(HttpResponseMessage response, FileInfo fileInfo, long fileLength, string fileName) { response.Headers.AcceptRanges.Add("bytes"); response.StatusCode = fileInfo.IsPartial ? HttpStatusCode.PartialContent : HttpStatusCode.OK; response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment"); response.Content.Headers.ContentDisposition.FileName = fileName; response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType); response.Content.Headers.ContentLength = fileInfo.Length; if (fileInfo.IsPartial) { response.Content.Headers.ContentRange = new ContentRangeHeaderValue(fileInfo.From, fileInfo.To, fileLength); } }
最重要的一步则是将FileInfo对象的值传递给我们自定义实现的流监控当前下载进度。
public class PartialContentFileStream : Stream { private readonly long _start; private readonly long _end; private long _position; private FileStream _fileStream; public PartialContentFileStream(FileStream fileStream, long start, long end) { _start = start; _position = start; _end = end; _fileStream = fileStream; if (start > 0) { _fileStream.Seek(start, SeekOrigin.Begin); } } /// <summary> /// 将缓冲区数据写到文件 /// </summary> public override void Flush() { _fileStream.Flush(); } /// <summary> /// 设置当前下载位置 /// </summary> /// <param name="offset"></param> /// <param name="origin"></param> /// <returns></returns> public override long Seek(long offset, SeekOrigin origin) { if (origin == SeekOrigin.Begin) { _position = _start + offset; return _fileStream.Seek(_start + offset, origin); } else if (origin == SeekOrigin.Current) { _position += offset; return _fileStream.Seek(_position + offset, origin); } else { throw new NotImplementedException("SeekOrigin.End未实现"); } } /// <summary> /// 依据偏离位置读取 /// </summary> /// <param name="buffer"></param> /// <param name="offset"></param> /// <param name="count"></param> /// <returns></returns> public override int Read(byte[] buffer, int offset, int count) { int byteCountToRead = count; if (_position + count > _end) { byteCountToRead = (int)(_end - _position) + 1; } var result = _fileStream.Read(buffer, offset, byteCountToRead); _position += byteCountToRead; return result; } public override IAsyncResult BeginRead(byte[] buffer, int offset, int count, AsyncCallback callback, object state) { int byteCountToRead = count; if (_position + count > _end) { byteCountToRead = (int)(_end - _position); } var result = _fileStream.BeginRead(buffer, offset, count, (s) => { _position += byteCountToRead; callback(s); }, state); return result; } ...... }
更新上述下载的完整逻辑
public HttpResponseMessage GetFile(string fileName) { fileName = "HBuilder.windows.5.2.6.zip"; if (!FileProvider.Exists(fileName)) { throw new HttpResponseException(HttpStatusCode.NotFound); } long fileLength = FileProvider.GetLength(fileName); var fileInfo = GetFileInfoFromRequest(this.Request, fileLength); var stream = new PartialContentFileStream(FileProvider.Open(fileName), fileInfo.From, fileInfo.To); var response = new HttpResponseMessage(); response.Content = new StreamContent(stream, BufferSize); SetResponseHeaders(response, fileInfo, fileLength, fileName); return response; }
下面我们来看看演示结果:
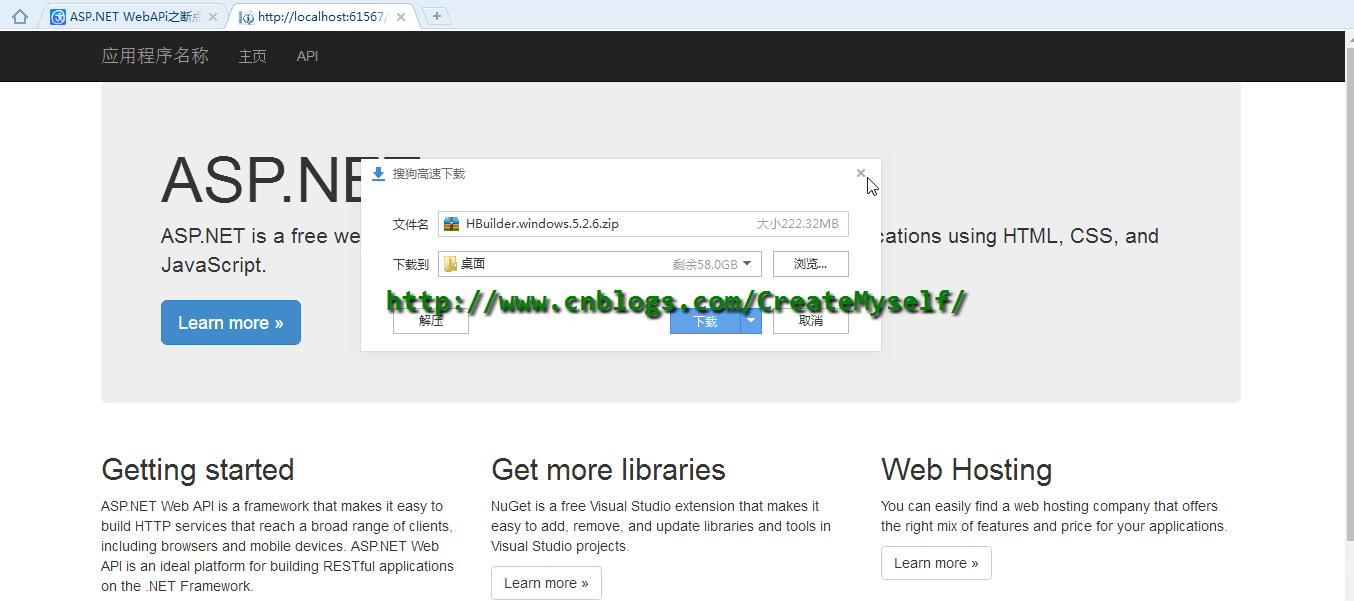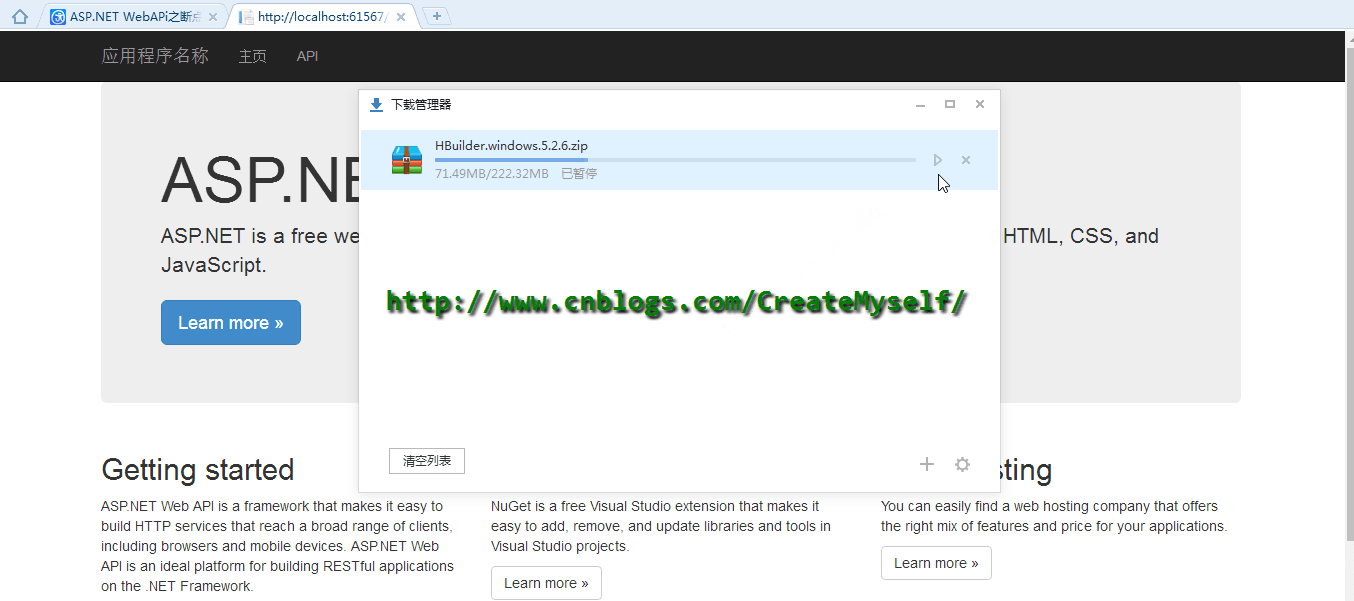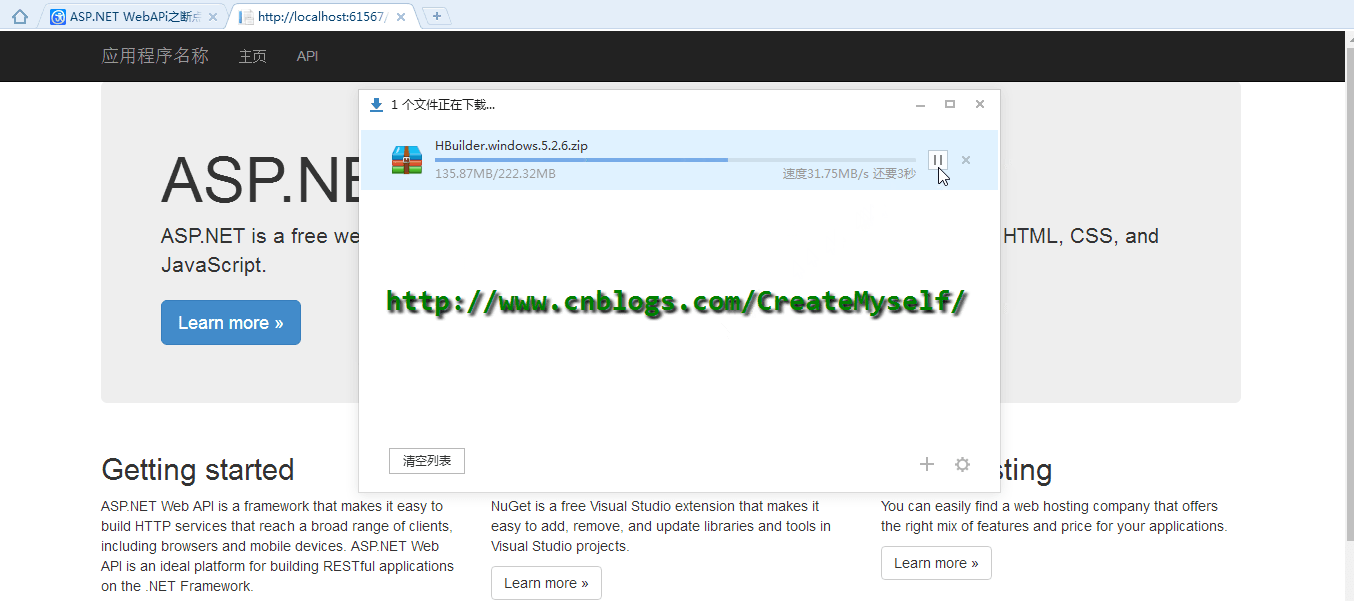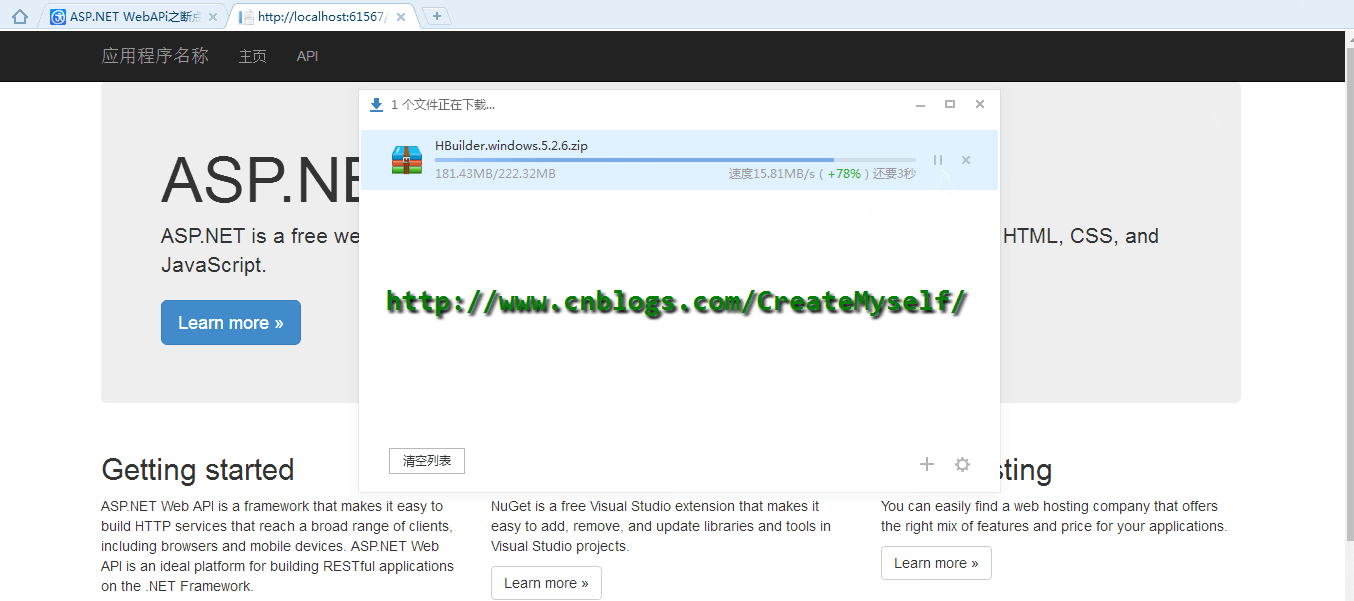
好了,到了这里我们也得到了我们想要的结果。
总结
本节我们将上节遗留的问题一一进行比较详细的叙述并最终解决,是不是就这么完全结束了呢?那本节定义为中篇岂不是不对头了,本节是在web端进行下载,下节我们利用webclient来进行断点续传。想了想无论是mvc上传下载,还是利用webapi来上传下载又或者是将mvc和webapi结合来上传下载基本都已经囊括,这都算是在项目中比较常用的吧,所以也就花了很多时间去研究。对于webapi的断点续传关键它本身就提供了比较多的api来给我们调用,所以还是很不错,webapi一个很轻量的服务框架,你值得拥有see u,反正周末,哟,不早了,休息休息。

