
Oracle 索引扫描的五种类型

(1)索引唯一扫描(INDEX UNIQUE SCAN)
LHR@orclasm > set line 9999
LHR@orclasm > select * from scott.emp t where t.empno=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=10)
LHR@orclasm > select * from scott.emp t where t.empno>=10 and t.empno<=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=10)
LHR@orclasm > create table t_emp_lhr as select * from scott.emp;
Table created.
LHR@orclasm > create unique index idx_dup_lhr on t_emp_lhr(empno,ename,job);
Index created.
LHR@orclasm > select * from t_emp_lhr t where t.empno=7369 and t.ename='lhr';
Execution Plan
----------------------------------------------------------
Plan hash value: 2495657605
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 0 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_EMP_LHR | 1 | 87 | 0 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_DUP_LHR | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=7369 AND "T"."ENAME"='lhr')
Note
-----
- dynamic sampling used for this statement (level=2)
LHR@orclasm > select * from t_emp_lhr t where t.empno=7369 and t.ename='lhr' and t.job='dba';
Execution Plan
----------------------------------------------------------
Plan hash value: 859693366
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_EMP_LHR | 1 | 87 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | IDX_DUP_LHR | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=7369 AND "T"."ENAME"='lhr' AND "T"."JOB"='dba')
(2)索引范围扫描(INDEX RANGE SCAN)
LHR@orclasm > select * from scott.emp t where t.empno>=10 and t.empno<=20;
Execution Plan
----------------------------------------------------------
Plan hash value: 169057108
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_EMP | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO">=10 AND "T"."EMPNO"<=20)
LHR@orclasm > select * from t_emp_lhr t where t.empno=7369 and t.ename='lhr';
Execution Plan
----------------------------------------------------------
Plan hash value: 2495657605
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 0 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_EMP_LHR | 1 | 87 | 0 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_DUP_LHR | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=7369 AND "T"."ENAME"='lhr')
Note
-----
- dynamic sampling used for this statement (level=2)
LHR@orclasm > create index idx_nounique_lhr on t_emp_lhr(DEPTNO);
Index created.
LHR@orclasm > select * from t_emp_lhr t where t.deptno=7369;
Execution Plan
----------------------------------------------------------
Plan hash value: 4262540901
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_EMP_LHR | 1 | 87 | 1 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_NOUNIQUE_LHR | 1 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."DEPTNO"=7369)
Note
-----
- dynamic sampling used for this statement (level=2)
--索引降序范围扫描(INDEX RANGE SCAN DESCENDING)
LHR@orclasm > select * from t_emp_lhr t where t.deptno between 7369 and 8000 order by deptno desc;
Execution Plan
----------------------------------------------------------
Plan hash value: 3039488792
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 0 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | T_EMP_LHR | 1 | 87 | 0 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| IDX_NOUNIQUE_LHR | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."DEPTNO">=7369 AND "T"."DEPTNO"<=8000)
Note
-----
- dynamic sampling used for this statement (level=2)
(3)索引全扫描(INDEX FULL SCAN)
LHR@orclasm > create index idx_full_emp_lhr on scott.emp(empno,ename);
Index created.
LHR@orclasm > select empno, ename from scott.emp order by empno,ename;
Execution Plan
----------------------------------------------------------
Plan hash value: 3792893151
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 140 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | IDX_FULL_EMP_LHR | 14 | 140 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
(4)索引快速全扫描(INDEX FAST FULL SCAN)
LHR@orclasm > select /*+ index_ffs(t) */ empno from scott.emp t where empno>0;
Execution Plan
----------------------------------------------------------
Plan hash value: 36645660
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 2 (0)| 00:00:01 |
|* 1 | INDEX FAST FULL SCAN| IDX_FULL_EMP_LHR | 14 | 56 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMPNO">0)
(5)索引跳跃扫描(INDEX SKIP SCAN)
LHR@orclasm > select /*+index_ss(t)*/ * from t_emp_lhr t where t.ename='lhr';
Execution Plan
----------------------------------------------------------
Plan hash value: 3374324980
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_EMP_LHR | 1 | 87 | 2 (0)| 00:00:01 |
|* 2 | INDEX SKIP SCAN | IDX_DUP_LHR | 1 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."ENAME"='lhr')
filter("T"."ENAME"='lhr')
Note
-----
- dynamic sampling used for this statement (level=2)
LHR@orclasm > create table t_idxss_20170607_lhr as select owner,object_id,object_type,created from dba_objects;
Table created.
LHR@orclasm > create index idx_idxss_com on t_idxss_20170607_lhr(owner,object_id,object_type);
Index created.
LHR@orclasm > exec dbms_stats.gather_table_stats(user,'t_idxss_20170607_lhr');
PL/SQL procedure successfully completed.
LHR@orclasm > select * from t_idxss_20170607_lhr where object_id=20 and object_type='TABLE';
Execution Plan
----------------------------------------------------------
Plan hash value: 1285454804
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 28 | 41 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T_IDXSS_20170607_LHR | 1 | 28 | 41 (0)| 00:00:01 |
|* 2 | INDEX SKIP SCAN | IDX_IDXSS_COM | 1 | | 40 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=20 AND "OBJECT_TYPE"='TABLE')
filter("OBJECT_ID"=20 AND "OBJECT_TYPE"='TABLE')
根据索引的类型与where限制条件的不同,有4种类型的Oracle索引扫描:
(1) 索引唯一扫描(index unique scan)
(2) 索引范围扫描(index range scan)
(3) 索引全扫描(index full scan)
(4) 索引快速扫描(index fast full scan)
(5) 索引跳跃扫描(INDEX SKIP SCAN)
一. 索引唯一扫描(index unique scan)
通过唯一索引查找一个数值经常返回单个ROWID。如果该唯一索引有多个列组成(即组合索引),则至少要有组合索引的引导列参与到该查询中,如创建一个索引:create index idx_test on emp(ename, deptno, loc)。则select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句可以使用该索引。如果该语句只返回一行,则存取方法称为索引唯一扫描。而select ename from emp where deptno = ‘DEV’语句则不会使用该索引,因为where子句种没有引导列。如果存在UNIQUE 或PRIMARY KEY 约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描。
如:
SQL> set autot traceonly exp; -- 只显示执行计划
SQL> select * from scott.emp t where t.empno=10;
执行计划
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:0
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:0
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:0
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."EMPNO"=10)
二.索引范围扫描(index range scan)
使用一个索引存取多行数据,同上面一样,如果索引是组合索引,而且select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句返回多行数据,虽然该语句还是使用该组合索引进行查询,可此时的存取方法称为索引范围扫描。
在唯一索引上使用索引范围扫描的典型情况下是在谓词(where限制条件)中使用了范围操作符(如>、<、<>、>=、<=、between)
使用索引范围扫描的例子:
SQL> select empno,ename from scott.emp where empno > 7876 order by empno;
执行计划
----------------------------------------------------------
Plan hash value: 169057108
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 2 (0)| 00:0
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 10 | 2 (0)| 00:0
|* 2 | INDEX RANGE SCAN | PK_EMP | 1 | | 1 (0)| 00:0
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO">7876)
在非唯一索引上,谓词可能返回多行数据,所以在非唯一索引上都使用索引范围扫描。
使用index rang scan的3种情况:
(a) 在唯一索引列上使用了range操作符(> < <> >= <= between)。
(b) 在组合索引上,只使用部分列进行查询,导致查询出多行。
(c) 对非唯一索引列上进行的任何查询。
三.索引全扫描(index full scan)
与全表扫描对应,也有相应的全Oracle索引扫描。在某些情况下,可能进行全Oracle索引扫描而不是范围扫描。
全Oracle索引扫描的例子:
SQL> create index big_emp on scott.emp(empno,ename);
索引已创建。
SQL> select empno, ename from scott.emp order by empno,ename;
执行计划
----------------------------------------------------------
Plan hash value: 322359667
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 140 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | BIG_EMP | 14 | 140 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------
四. 索引快速扫描(index fast full scan)
扫描索引中的所有的数据块,与 index full scan很类似,但是一个显著的区别就是它不对查询出的数据进行排序,即数据不是以排序顺序被返回。在这种存取方法中,可以使用多块读功能,也可以使用并行读入,以便获得最大吞吐量与缩短执行时间。
索引快速扫描的例子:
SQL> select /*+ index_ffs(dave index_dave) */ id from dave where id>0;
执行计划
----------------------------------------------------------
Plan hash value: 674200218
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 24 | 2 (0)| 00:00:0
|* 1 | INDEX FAST FULL SCAN| INDEX_DAVE | 8 | 24 | 2 (0)| 00:00:0
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID">0)
为了实现这个效果,折腾了半天,最终还是用hint来了.
Oracle Hint
http://blog.csdn.net/tianlesoftware/archive/2010/03/05/5347098.aspx
INDEX SKIP SCAN,发生在多个列建立的复合索引上,如果SQL中谓词条件只包含索引中的部分列,并且这些列不是建立索引时的第一列时,就可能发生INDEX SKIP SCAN。这里SKIP的意思是因为查询条件没有第一列或前面几列,被忽略了。
Oracle 10g的文档如下:
Index skip scans improve index scans by nonprefix columns. Often, scanning index blocks is faster than scanning table data blocks.
Skip scanning lets a composite index be split logically into smaller subindexes. In skip scanning, the initial column of the composite index is not specified in the query. In other words, it is skipped.
--skip scan 让组合索引(composite index)逻辑的split 成几个子索引。如果在在查询时,第一个列没有指定,就跳过它。
The number of logical subindexes is determined by the number of distinct values in the initial column. Skip scanning is advantageous if there are few distinct values in the leading column of the composite index and many distinct values in the nonleading key of the index.
-- 建议将distinct 值小的列作为组合索引的引导列,即第一列。
Consider, for example, a table employees (sex, employee_id, address) with a composite index on (sex, employee_id). Splitting this composite index would result in two logical subindexes, one for M and one for F.
For this example, suppose you have the following index data:
('F',98)
('F',100)
('F',102)
('F',104)
('M',101)
('M',103)
('M',105)
The index is split logically into the following two subindexes:
(1)The first subindex has the keys with the value F.
(2)The second subindex has the keys with the value M.
Figure 13-2 Index Skip Scan Illustration
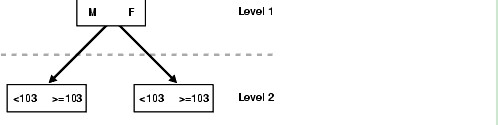
The column sex is skipped in the following query:
SELECT *
FROM employees
WHERE employee_id = 101;
A complete scan of the index is not performed, but the subindex with the value F is searched first, followed by a search of the subindex with the value M.
测试:
创建表:
SQL> create table dave_test as select owner,object_id,object_type,created from dba_objects;
Table created.
创建组合索引
SQL> create index idx_dave_test_com on dave_test(owner,object_id,object_type);
Index created.
--收集表的统计信息
SQL> exec dbms_stats.gather_table_stats('SYS','DAVE_TEST');
PL/SQL procedure successfully completed.
SQL> set autot traceonly exp;
指定组合索引的所有字段时,使用Index range scan:
SQL> select * from dave_test where owner='SYS' and object_id=20 and object_type='TABLE';
Execution Plan
----------------------------------------------------------
Plan hash value: 418973243
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 2
| 1 | TABLE ACCESS BY INDEX ROWID| DAVE_TEST | 1 | 27 | 2
|* 2 | INDEX RANGE SCAN | IDX_DAVE_TEST_COM | 1 | | 1
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER"='SYS' AND "OBJECT_ID"=20 AND "OBJECT_TYPE"='TABLE')
指定组合索引的2个字段时,使用的还是index range scan:
SQL> select * from dave_test where owner='SYS' and object_id=20;
Execution Plan
----------------------------------------------------------
Plan hash value: 418973243
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 3
| 1 | TABLE ACCESS BY INDEX ROWID| DAVE_TEST | 1 | 27 | 3
|* 2 | INDEX RANGE SCAN | IDX_DAVE_TEST_COM | 1 | | 2
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER"='SYS' AND "OBJECT_ID"=20)
指定组合索引的引导列,即第一个列时,不走索引,走全表扫描
SQL> select * from dave_test where owner='SYS';
Execution Plan
----------------------------------------------------------
Plan hash value: 1539627441
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 23567 | 621K| 52 (4)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DAVE_TEST | 23567 | 621K| 52 (4)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OWNER"='SYS')
指定组合索引的非引导列,使用Index skip scan:
SQL> select * from dave_test where object_id=20 and object_type='TABLE';
Execution Plan
----------------------------------------------------------
Plan hash value: 3446962311
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 22
| 1 | TABLE ACCESS BY INDEX ROWID| DAVE_TEST | 1 | 27 | 22
|* 2 | INDEX SKIP SCAN | IDX_DAVE_TEST_COM | 1 | | 21
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=20 AND "OBJECT_TYPE"='TABLE')
filter("OBJECT_ID"=20 AND "OBJECT_TYPE"='TABLE')
指定组合索引的最后一列,不走索引,走全表扫描
SQL> select * from dave_test where object_type='TABLE';
Execution Plan
----------------------------------------------------------
Plan hash value: 1539627441
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1774 | 47898 | 52 (4)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DAVE_TEST | 1774 | 47898 | 52 (4)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_TYPE"='TABLE')
指定组合索引的头尾2列,不走索引:
SQL> select * from dave_test where owner='SYS' and object_type='TABLE';
Execution Plan
----------------------------------------------------------
Plan hash value: 1539627441
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 830 | 22410 | 52 (4)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DAVE_TEST | 830 | 22410 | 52 (4)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_TYPE"='TABLE' AND "OWNER"='SYS')
通过以上测试,和之前官网的说明,Index skip scan 仅是在组合索引的引导列,即第一列没有指定,并且非引导列指定的情况下。
联合索引选择性更高咯,所占空间应当是比单独索引要少,因为叶节点节省了重复的rowid,当然branch节点可能稍微多一点。
禁用skip scan:
alter system set “_optimizer_skip_scan_enabled” = false scope=spfile;
About Me
...............................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-05-09 09:00 ~ 2017-05-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。






