
原文http://blog.csdn.net/horace20/article/details/6672081
特别说明:本文产生于个人工作总结,转载请注明原文出处http://blog.csdn.net/horace20
1、环境
PowerDesigner15.2.0.3042-BEAN+ MySQL5.5 + mysql-connector-odbc-5.1.8
以上软件在网上都很容易找到,这里就不再给出相关链接!系统环境为WindowsXP。
2、具体流程
既然是生成测试数据,首先数据库一定存在,这里我以对MySQL的操作为例,假设我的数据库名称为db_generate_test。
流程如下:

在PowerDesigner环境中,只能对PDM(物理数据模型)生成测试数据所以,首先将需要生成测试数据的数据库反向工程为PowerDesigner的PDM模型。
2.1.1配置数据源
针对MySQL5.0系列版本需要安装mysql-connector-odbc-5.1.8,这里没有什么选择项,直接“下一步”就行。安装好后,打开控制面板 | 管理工具 | 数据源(ODBC) 如图:
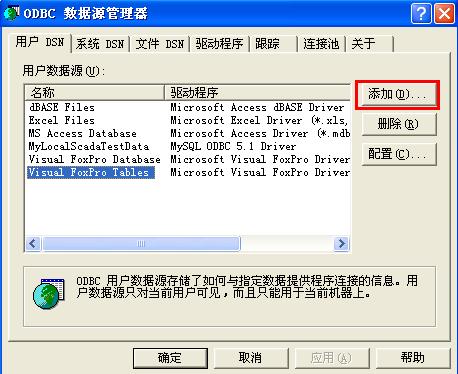
添加数据源:
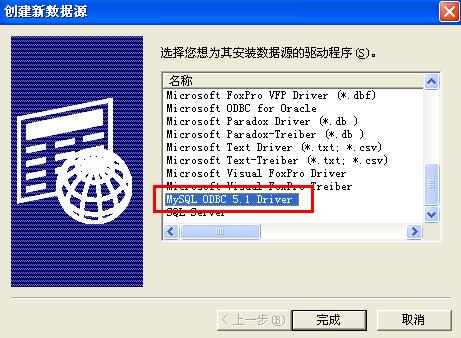
创建数据源:
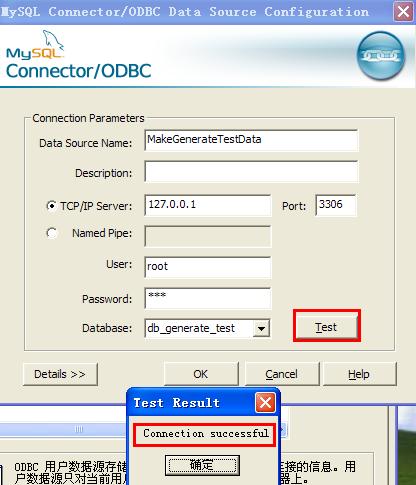
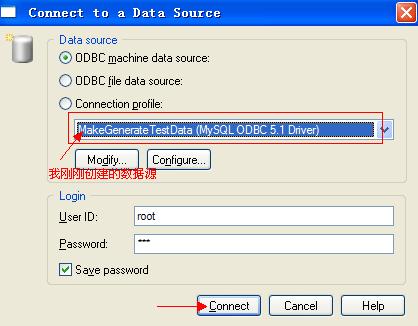
填完相关选项后点击“Test”连接成功,OK确定即完成数据源的创建。
2.1.2数据库反向工程
数据源建好后打开PowerDesigner,选择File | Reverse Engineer |Database…,如下图:
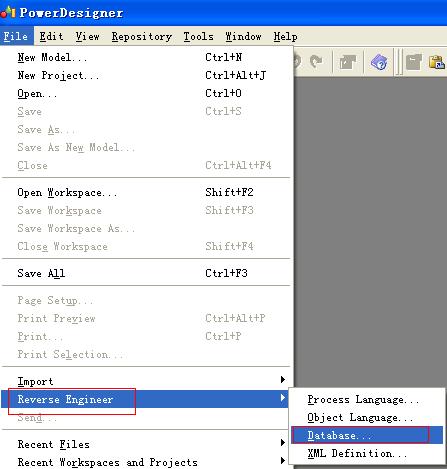
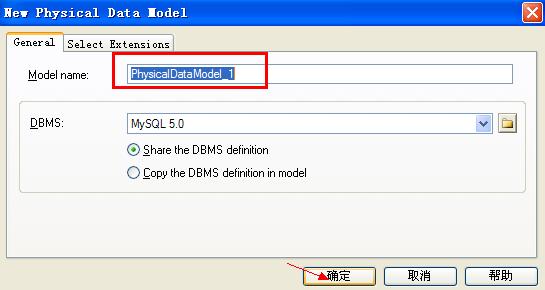
你可以为物理数据模型命名,确定即可,这里我命名为GenerateTestDataModel_1,接着:
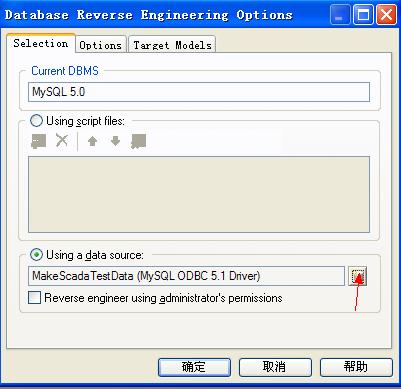
点击红色箭头处配置数据源:
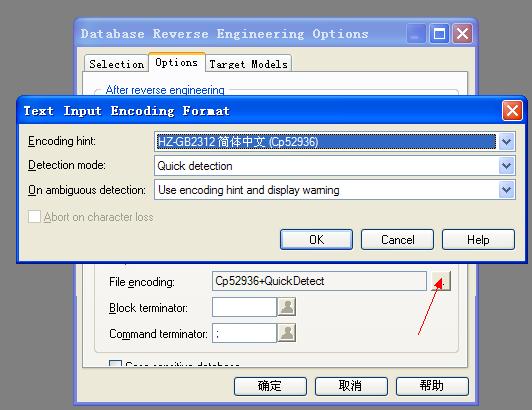
另外在“Options”选项下可以配置编码类型等选项:
确定后如下:
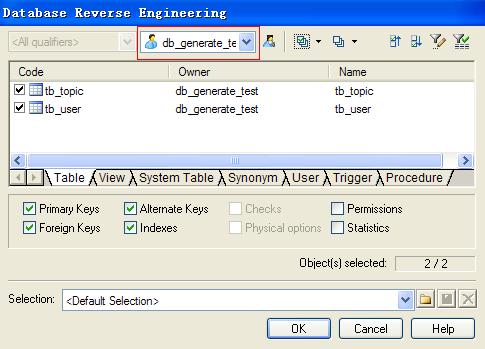
选择数据库用户,选择表,OK即可完成数据库到物理数据模型的转换
我这里只有两个表,而且表结构也极其简单,这个过程很快就会完成,但是如果你的数据库表多、表结构复杂,那么这将是一个非常耗时的过程。我曾遇到过 耗了三天三夜险些未完成的(果真是那样的话,不建议使用PowerDesigner生成测试数据,因为在生成测试数那一步会更加耗时,自己编写程序插入模 拟数据会快很多)。
2.2配置测试数据摘要文档
这一步相当于是制定你的测试数据生成规则,可以单独做也可以和下一步“应用测试数据摘要文档”一起做,单独做的话点击Model | Test Data Profile…,不过我个人更建议和下一步一起做,因为那样使你更加明确需要配置哪些测试数据摘要文档。
2.3应用测试数据摘要文档
在PowerDesigner PDM模型下双击Table,Columns选项卡下再双击相应字段,如下:
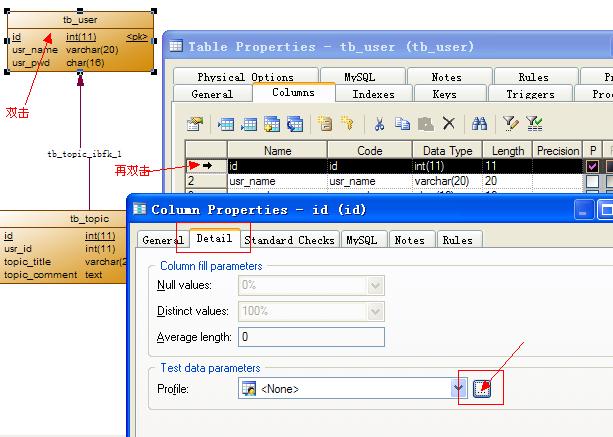
在出现的ColumnProperties选项板中Detail选项卡下点击红色箭头可创建测试数据摘要文档: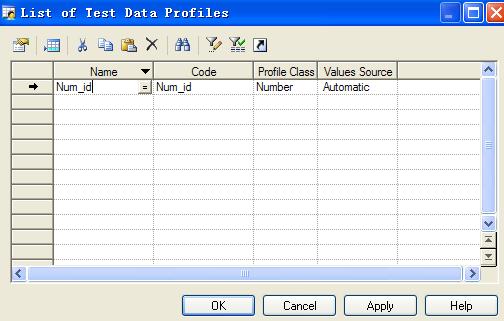
这里我为id列创建的测试数据摘要文档名为Num_id,是Number类型,自动产生。其中这里有三种类型可以选择,分别是:Number(数值 型)、Character(字符型)、Data&Time(日期时间型)。在”Generaction Source”项上为测试数据摘要文件指定数据的产生方式:Automatic是自动产生、List是根据列表值产生、ODBC是根据其它的数据库产生。
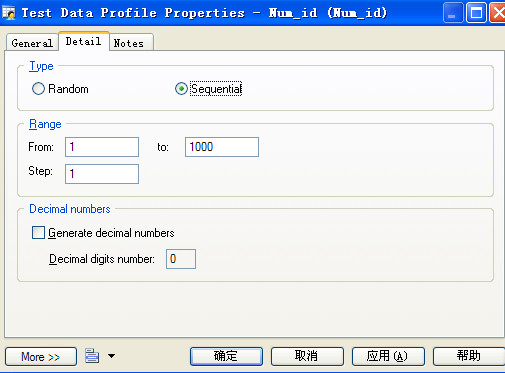
再双击“Num_id”可制定更细致的规则,如下我这里指定的是一序列的方式从1递增至1000,步长为1(我假设在这里要产生1000条数据):
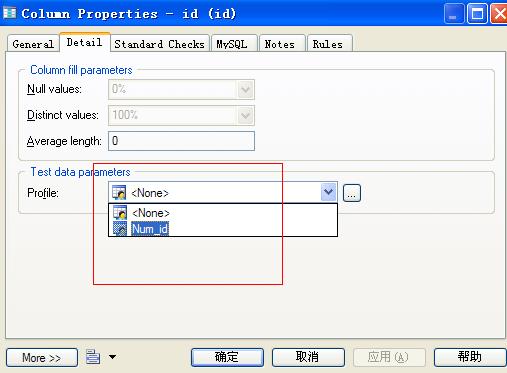
制定摘要文档完成后确定回到Column Properties - id选项板下,为列应用摘要文档,如下:
制定完所有测试数据生成规则后可进入下一步“生成测试数据”。
2.4生成测试数据
选择Database | Generate Test Data…如下:
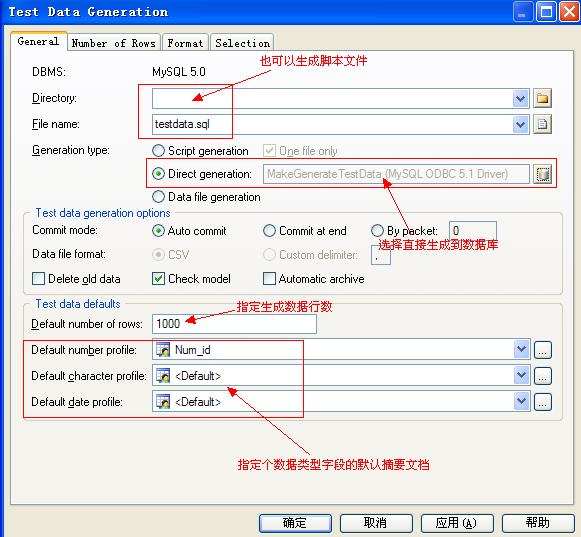
确定即可开始生成测试数据。
2、总结
每当我们完成数据库的构建,接下就需要数据库性能测、相关接口测试以及报表测试等等,这时就需要大量的测试数据。相比手工创建,使用 PowerDesigner自动生成不失为一种方便简捷的办法。但是这一切都是建立在我们的数据库结构并不复杂庞大的情况下,如果你的数据库结构庞大复 杂,那么你看到的将是PowerDesigner未响应,这时PowerDesigner的效率还不如我们自己写程序生成。
另,在生成大量测试数据的过程中,为了节约时间我们可以采用并行生成测试数据,即在不影响相关外键及其他约束的情况下,我们可以将数据库分为几个相对独立的模块,分别生成。


