
Hadoop 的主要组件是 HDFS 文件系统,它支持将信息分布到整个集群中。对于使用这种分布格式存储的信息,可以通过一个名为 MapReduce 的系统在每个集群节点上进行单独处理。MapReduce 进程将存储在 HDFS 文件系统中的信息转换为更小的、经过处理的、更容易管理的数据块。
因为 Hadoop 可在多个节点上运行,所以可以使用它来处理大量输入数据,并将这些数据简化为更实用的信息块。此过程可使用一个简单的 MapReduce 系统来处理。
MapReduce 转换传入信息(不一定为结构化格式),将该信息转换为一种可更轻松地使用、查询和处理的结构。
例如,一种典型的用途是处理来自数百个不同应用程序的日志信息,以便可以识别特定的问题、计数或其他事件。通过使用 MapReduce 格式,您可以开始度量并查找趋势,将平常非常多的信息转换为更小的数据块。举例而言,在查看某个 Web 服务器的日志时,您可能希望查看特定页面上的特定范围中发生的错误。您可以编写一个 MapReduce 函数来识别特定页面上的特定错误,并在输出中生成该信息。使用此方法,您可从日志文件中精减多行信息,得到一个仅包含错误信息的小得多的记录集合。
理解 MapReduce
MapReduce 的工作方式分两个阶段。映射 (map) 过程获取传入信息,并将这些信息映射到某种标准化的格式。对于某些信息类型,此映射可以是直接和显式的。例如,如果要处理 Web 日志等输入数据,那么仅从 Web 日志的文本中提取一列数据即可。对于其他数据,映射可能更复杂。在处理文本信息时,比如研究论文,您可能需要提取短语或更复杂的数据块。
精减 (reduce) 阶段用于收集和汇总数据。精减实际上能够以多种不同方式发生,但典型的过程是处理一个基本计数、总和或其他基于来自映射阶段的个别数据的统计数据。
想象一个简单的示例,比如 Hadoop 中用作示例 MapReduce 的字数,映射阶段将对原始文本进行分解,以识别各个单词,并为每个单词生成一个输出数据块。reduce 函数获取这些映射的信息块,对它们进行精减,以便在所看到的每个惟一单词上进行递增。给定一个包含 100 个单词的文本文件,映射过程将生成 100 个数据块,但精减阶段可对此进行汇总,提供惟一单词的数量(比如 56 个)和每个单词出现的次数。
借助 Web 日志,映射将获取输入数据,为日志文件中的每个错误创建一条记录,然后为每个错误生成一个数据块,其中包含日期、时间和导致该问题的页面。
在 Hadoop 内,MapReduce 阶段会出现在存储各个源信息块的各个节点上。这使 Hadoop 能够处理以下大型信息集:通过允许多个节点同时处理数据。例如,对于 100 个节点,可以同时处理 100 个日志文件,比通过单个节点快得多地简化许多 GB(或 TB)的信息。
Hadoop 信息
核心 Hadoop 产品的一个主要限制是,无法在数据库中存储和查询信息。数据添加到 HDFS 系统中,但您无法要求 Hadoop 返回与某个特定数据集匹配的所有数据的列表。主要原因是 Hadoop 不会存储、结构化或理解存储在 HDFS 中的数据的结构。这正是 MapReduce 系统需要将信息分析并处理为更加结构化的格式的原因。
但是,我们可以将 Hadoop 的处理能力与更加传统的数据库相结合,使我们可以查询 Hadoop 通过自己的 MapReduce 系统生成的数据。可能的解决方案有许多,其中包括一些传统 SQL 数据库,但我们可以通过使用 Couchbase Server 来保持 MapReduce 风格(它对大型数据集非常有效)。
系统之间的数据共享的基本结构如 图 1 所示。
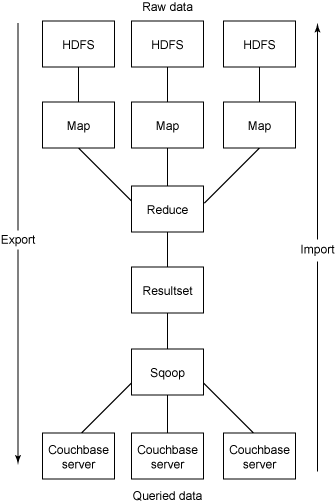
▲图 1. 系统之间的数据共享的基本结构
作者: 李焕珠
来源:IT168
原文链接:结合使用Hadoop与Couchbase Server
