
文章目录`
一 树的概念与应用场景
1.1 二叉查找树
1.2 AVL树
1.3 红黑树
1.4 B树
二 树的操作与源码实现
2.1 TreeMap/TreeSet实现原理
写在前面
之前在网上看到过很多关于Java集合框架实现原理文章,但大都在讲接口的作用与各类集合的实现,对其中数据结构的阐述的不多,例如红黑树的染色和旋转是怎么进行的等等,本篇文章从 数据结构的基本原理出发,逐步去分析Java集合里数据结构的应用与实现。
一 树的概念与应用场景
树是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点组成一个具有层次关系的集合。把 它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树有以下特点:
每个节点有零个或多个子节点;
没有父节点的节点称为根节点;
每一个非根节点有且只有一个父节点;
除了根节点外,每个子节点可以分为多个不相交的子树;
与树相关的概念
节点的度:一个节点含有的子树的个数称为该节点的度;
树的度:一棵树中,最大的节点的度称为树的度;
叶节点或终端节点:度为零的节点;
非终端节点或分支节点:度不为零的节点;
父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
深度:对于任意节点n, n的深度为从根到n的唯一路径长,根的深度为0;
高度:对于任意节点n, n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
堂兄弟节点:父节点在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
注:参照亲戚关系,这些概念很好理解,家族谱也是一种树结构。:grinning:
树的分类
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
其中有序树又分为:
二叉树:每个节点最多含有两个子树的树称为二叉树;
完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树;
满二叉树:所有叶节点都在最底层的完全二叉树;
AVL树:当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
二叉查找树:树中的每个节点,它的左子树中所有项小于X中的项,它的右子树中的所有项大于X中的项。
霍夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
1.1 二叉查找树
二叉查找树是一种有序二叉树,它的查找、插入的时间复杂度为O(logN)
二叉查找是是一种有序二叉树.
主要特点
若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值。
若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值。
任意节点的左右子树叶为二叉查找树
没有键值相等的节点。
就就是说二叉查找树上的节点是排好序的:左子树 < 根节点 < 右子树。
性能分析
在最坏的情况下,即当先后插入的关键字有序时,构造成的二叉查找树蜕变为单支树,输的深度为n,其平均查找长度为(n+1)/2。
在最好的情况下,二叉查找树的形态和折半查找的判定树相同,其时间复杂度为O(log2(N))。
我们来看看二叉查找树上的相关操作。
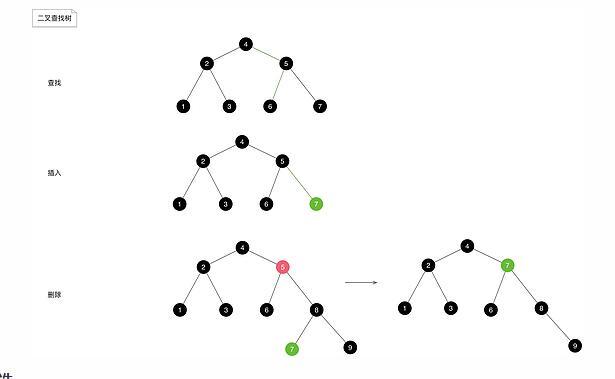
构造
当我们用一组数值构造一棵二叉查找树时,就相当于对这组数值进行了排序,在最坏情况下,即该组数值是从小到达排好序的,构造出来的二叉树的所有节点都 没有左子树,这种情况下的时间复杂度为O(N2)。(N的平方)
另外,树排序的问题使得CPU Cache性能较差,特别是当节点是动态内存分配时。而堆排序的CPU Cache性能较好。另一方面,树排序是最优的增量排序(incremental sorting)算法, 保持一个数值序列的有序性。
查找
由于二叉查找树具有左子树 < 根节点 < 右子树的特点,因此在二叉查找树b中查找x的过程如下:
若b是空树,则查找失败,否则:
若x等于根节点的值,则查找成功,否则:
若x小于b根节点的值,则查找左子树,否则
若x大于b根节点的值,则查找右子树。
整个流程是一个递归的过程。
插入
插入的过程也是查找的过程,在二叉查找树中插入节点x的过程如下:
若b是空树,则x作为根节点插入,否则:
若x的值等于根节点的值,则直接返回,否则:
若x的值小于根节点的值,则将x插入当该根节点的左子树中,否则
将x插入该根节点的右子树中。
这也是一个递归的过程,这里我们要关注两点:
插入的过程也是查找的过程
二叉查找树不允许有相同值的节点
删除
在二叉查找树上删除一个节点,分为三种情况:
若删除的是叶子节点,则不会破坏树的结构,只需要修改其双亲节点的指针即可。
若删除的节点只有一个孩子节点,则用它的孩子节点代替它的位置即可,如此也不会破坏红黑树的结构。
若删除的节点有两个孩子节点,这种情况复杂一下,我们通常会找到要删除节点X的左子树里的最大元素或者右子树里的最小元素,然后用M替换掉X,再删除节点,因为此时M最多只会有一个
节点(如果左子树最大元素则没有右子节点,若是右子树最小元素则没有左子节点),若M没有孩子节点,直接进入情况1处理,若M只有一个孩子,则直接进入情况2处理。
另外,如果删除的次数不多,可以采用 懒惰删除 的方式,即当一个元素删除时,它仍然留在树中,只是被比较为已删除,这种方式在有重复项是特别有用, 另外如果删除的元素又重新插入,这种方式可以避免新单元的创建开销。
1.2 AVL树
AVL树是带有平衡条件的二叉查找树。
主要特点
AVL树中的任何阶段的两棵子树高度最大差别为1.
AVL树还有个平衡因子的概念,平衡因子 = 左子树高度 - 右子树高度,因此平衡因子为-1,0,1的为平衡二叉树,其他的都是不平衡的。
另外,把一棵不平衡的二叉查找树变成一棵平衡二叉树,我们称之为 AVL旋转 。
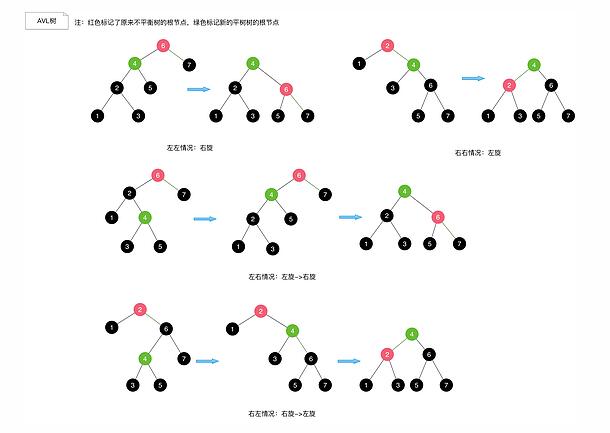
我们来看看不同情况下AVL旋转如何进行。
左左情况:右旋
右右情况:左旋
左右情况:先左旋,再右旋
右左情况:先右旋,再左旋
注:所谓左左指的是左边的左子树多了一个,其他的依此类推。
具体操作如下所示,我们可以看到左左情况和右右情况只需要单旋转就可以完成,左右情况与右左情况需要先把它们变成左左情况与右右情况 再进行旋转,因此这两种情况需要双旋转才能完成。
性能分析
查找、插入与删除在平均和最坏的情况下的时间复杂度为O(logN)。
AVL树也是二叉查找树的一种,它的很多操作都可以向我们上面描述的二叉查找树的操作那样进行。删除操作有点例外,我们在进行删除操作
时可以把要删除的节点向下旋转形成一个叶子节点,然后直接删除这个叶子节点,因为旋转成叶子节点期间,做多有logN个节点被旋转,每次 AVL旋转花费的事件固定,所以删除操作的时间复杂度是O(logN)。
1.3 红黑树
红黑树是平衡二叉树的变种,它的操作的时间复杂度是O(logN).
红黑树是一种具有着色性质的树,具有以下特点:
每个节点被着成红色或者黑色
根是黑色的
叶子节点都是黑色的,叶子节点指的是NULL节点,有些红黑树图中可能没有标记出来。
如果一个节点是红色的,那么他额子节点必须是黑色的,也就是不会存在两个红色节点毗邻。
从一个节点到一个叶子节点(NULL节点)的每一条路径必须包含相同数目的黑色节点。
红黑树也是一种二叉查找树,查找操作与二叉查找树相同,插入与删除操作有所不同。
1.4 B树
B树是一种自平衡的树,能够保持数据有序,B树为系统大块数据的读写操作做了优化,通常用在数据库与文件系统的实现上。
我们前面讲解了二叉查找树、AVL树,红黑树,这三种都是典型的二叉查找树结构,其查找的事件复杂度O(logN)与树的深度有关,考虑这么一种情况,如果有 大量的数据,而节点存储的数据有限,这种情况下,我们只能去扩充树的深度,就会导致查找效率低下。
怎么解决这种问题,一个简单的想法就是:二叉变多叉。
这里我们想象一下常见的文件系统,它也是一种树结构,在查找文件时,树的深度就决定了查找的效率。因此B树就是为了减少数的深度从而提高查找效率的一种 数据结构。
主要特点
一个阶为M的B树具有以下特点:
注:M阶指的是M叉查找树,例如M = 2,则为二叉查找树。
数据项存储在树叶上
非叶节点存储直到M-1个关键字以指示搜索方向:关键字代表子树i+1中最小的关键字
树的根或者是一片树叶,或者其儿子数都在2和M之间。
除根外,所有非树叶节点的儿子树在M/2与M之间。
所有的树叶都在相同的深度上拥有的数据项都在L/2与L之间。
性能分析
B树在查找、插入以及删除等操作中,时间复杂度为O(logN)。
二 树的操作与源码实现
在文章 01Java关于数据结构的实现:表、栈与队列 中我们 讨论了ArrayList与LinkedList的实现,它们的瓶颈在于查找效率低下。因而Java集合设计了Set与Map接口,它们在插入、删除与查找等基本操作都有良好的表现。
2.1 TreeMap/TreeSet实现原理
TreeSet实际上是基于TreeMap的NavigableSet的实现,它在功能上完全依赖于TreeMap,TreeMap是一个基于红黑树实现的Map,它在存储时对元素进行排序。
因此只要理解了TreeMap实现即可,TreeSet在功能上完全依赖于TreeMap。
TreeMap具有以下特点:
TreeMap是一个有序的key-value集合,基于红黑树实现。
没有实现同步
TreeMap实现以下接口:
NavigableMap:支持一系列导航方法,比如返回有序的key集合。
Cloneable:可以被克隆。
Serializable:支持序列化。
成员变量
//比较器
private final Comparator<? super K> comparator;
//根节点
private transient TreeMapEntry<K,V> root = null;
//集合大小
private transient int size = 0;
//修改次数
private transient int modCount = 0;
构造方法
public TreeMap() {
//默认比较器
comparator = null;
}
public TreeMap(Comparator<? super K> comparator) {
//指定比较器
this.comparator = comparator;
}
public TreeMap(Map<? extends K, ? extends V> m) {
//默认比较器
comparator = null;
putAll(m);
}
public TreeMap(SortedMap<K, ? extends V> m) {
//指定比较器
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
内部类
TreeMap里面定义了静态内部类TreeMapEntry来描述节点信息。
static final class TreeMapEntry<K,V> implements Map.Entry<K,V> {
//键
K key;
//值
V value;
//指向左子树的引用
TreeMapEntry<K,V> left = null;
//指向右子树的引用
TreeMapEntry<K,V> right = null;
//指向父节点的引用
TreeMapEntry<K,V> parent;
//节点颜色,默认为黑色
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
TreeMapEntry(K key, V value, TreeMapEntry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
/**
* Returns the key.
*
* @return the key
*/
public K getKey() {
return key;
}
/**
* Returns the value associated with the key.
*
* @return the value associated with the key
*/
public V getValue() {
return value;
}
/**
* Replaces the value currently associated with the key with the given
* value.
*
* @return the value associated with the key before this method was
* called
*/
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
操作方法
在正式介绍TreeMap里的增、删、改、查操作之前,我们先来看看TreeMop里关于节点染色,树的旋转等操作的实现,它们是TreeMap实现的基础。
节点染色
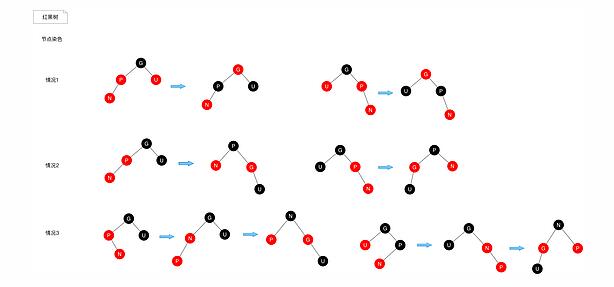
在介绍染色规则之前,我们先来回顾一下红黑树的特点:
每个节点被着成红色或者黑色
根是黑色的
叶子节点都是黑色的,叶子节点指的是NULL节点,有些红黑树图中可能没有标记出来。
如果一个节点是红色的,那么他额子节点必须是黑色的,也就是不会存在两个红色节点毗邻。
从一个节点到一个叶子节点(NULL节点)的每一条路径必须包含相同数目的黑色节点。
关于节点染色,我们有多种情况需要考虑。
首先说明
若新节点位于树的根上,没有父节点,直接将其染成黑色即可。这个在代码中无需操作,因为节点默认就是黑色的。
若新节点的父节点是黑色,这个时候树依然满足红黑树的性质,并不需要额外的处理。
以上两种情况无需额外的处理,我们再来考虑需要处理的情况。
情况1:如果新节点N的父节点P是红色,且其叔父节点U也为红色,我们可以将父节点P与叔父节点U染成黑色,祖父节点G染成红色。
情况2:如果新节点N的父节点P是红色,且其叔父节点U为黑色或者没有叔父节点,P为其父节点P的右子节点,P为为其父节点G的左子节点。这种情况我们针对祖父节点G做一次右旋。并将P染成黑色,染成红色
情况3:如果新节点N的父节点P是红色,且其叔父节点U为黑色或者没有叔父节点,P为其父节点P的右子节点,P为为其父节点G的左子节点。这种情况下我们对做一次左旋调换,调换P与N的位置,这样情况3变成了 情况2,剩下的按照情况2处理即可。
我们来看看具体的源码实现。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
//染色
private void fixAfterInsertion(TreeMapEntry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
//新节点N(即x)在其祖父节点的左子树上,叔父节点在左子树上。
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
TreeMapEntry<K,V> y = rightOf(parentOf(parentOf(x)));
//情况1:如果新节点N的父节点P是红色,且其叔父节点U也为红色,我们可以将父节点P与叔父节点U染成黑色,祖父节点G染成红色。
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//情况2:如果新节点N的父节点P是红色,且其叔父节点U为黑色或者没有叔父节点,P为其父节点P的右子节点,P为为其父节点G的左
//子节点。这种情况我们针对祖父节点G做一次右旋。并将P染成黑色,染成红色
else {
//情况3:x为其父节点的右子节点,先对其父节点进行左旋,调换两者的位置
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
}
//情况1:新节点N(即x)在其祖父节点的右子树上,叔父节点在左子树上,这种情况和在右子节点的情况相似,知识旋转方向相反罢了。
else {
TreeMapEntry<K,V> y = leftOf(parentOf(parentOf(x)));
//如果新节点N的父节点P是红色,且其叔父节点U也为红色,我们可以将父节点P与叔父节点U染成黑色,祖父节点G染成红色。
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//情况2:如果新节点N的父节点P是红色,且其叔父节点U为黑色或者没有叔父节点,P为其父节点P的右子节点,P为为其父节点G的左
//子节点。这种情况我们针对祖父节点G做一次右旋。并将P染成黑色,染成红色
else {
//情况3:x为其父节点的左子节点,先对其父节点进行右旋,调换两者位置。
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
}
节点旋转
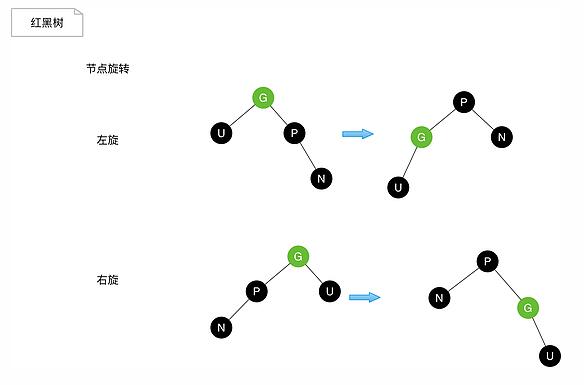
左旋
之前在网上看到一组关于左旋、右旋的动态图,很形象,这里也贴出来。
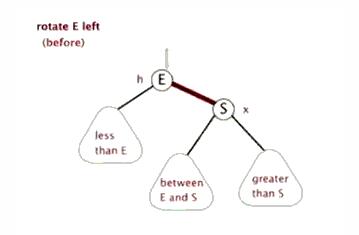
找到要旋转节点p的右节点r,然后将r的左子节点赋值给p的右子节点,如果r的左子节点为空,则直接将r节点设置为P的父节点。
将原来p的父节点设置成r的父节点,如果原来p的父节点为空,则直接接r设置成根节点,如果根节点不空且其做子节点为p,则将r设置为新的左子节点,如果根节点不空且其右子节点为p,则将r设置为新的右子节点,
再讲r的左子节点设为p,p的父节点设置为r,左旋完成。
右旋
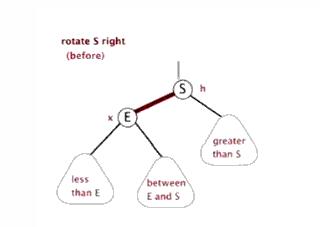
找到要旋转节点p的左子节点l,然后将l的右子节点赋值给p的左子节点,如果l的右子节点为空,则直接将l节点设置为P的父节点。
将原来p的父节点设置成l的父节点,如果原来p的父节点为空,则直接接l设置成根节点,如果根节点不空且其做子节点为p,则将l设置为新的左子节点,如果根节点不空且其右子节点为p,则将l设置为新的右子节点,
再讲l的右子节点设为p,p的父节点设置为l,右旋完成。
我们来看看具体的源码实现。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
//左旋
private void rotateLeft(TreeMapEntry<K,V> p) {
if (p != null) {
//找到要旋转节点p的右节点r
TreeMapEntry<K,V> r = p.right;
//然后将r的左子节点赋值给p的右子节点
p.right = r.left;
//如果r的左子节点为空,则直接将r节点设置为P的父节点
if (r.left != null)
r.left.parent = p;
//将原来p的父节点设置成r的父节点
r.parent = p.parent;
//如果原来p的父节点为空,则直接接r设置成根节点
if (p.parent == null)
rroot = r;
//如果根节点不空且其做子节点为p,则将r设置为新的左子节点
else if (p.parent.left == p)
p.parent.left = r;
//如果根节点不空且其右子节点为p,则将r设置为新的右子节点
else
p.parent.right = r;
//再讲r的左子节点设为p,p的父节点设置为r,左旋完成
r.left = p;
p.parent = r;
}
}
//右旋
private void rotateRight(TreeMapEntry<K,V> p) {
if (p != null) {
//找到要旋转节点p的左子节点l
TreeMapEntry<K,V> l = p.left;
//然后将l的右子节点赋值给p的左子节点
p.left = l.right;
//如果l的右子节点为空,则直接将l节点设置为P的父节点
if (l.right != null) l.right.parent = p;
//将原来p的父节点设置成l的父节点
l.parent = p.parent;
//如果原来p的父节点为空,则直接接l设置成根节
if (p.parent == null)
root = l;
//如果根节点不空且其右子节点为p,则将l设置为新的右子节点
else if (p.parent.right == p)
p.parent.right = l;
//如果根节点不空且其做子节点为p,则将l设置为新的左子节点
else p.parent.left = l;
//再讲l的右子节点设为p,p的父节点设置为l,右旋完成。
l.right = p;
p.parent = l;
}
}
}
put
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
public V put(K key, V value) {
//找到根节点
TreeMapEntry<K,V> t = root;
//如果根节点为空,则设置该元素为
if (t == null) {
if (comparator != null) {
if (key == null) {
comparator.compare(key, key);
}
} else {
if (key == null) {
throw new NullPointerException("key == null");
} else if (!(key instanceof Comparable)) {
throw new ClassCastException(
"Cannot cast" + key.getClass().getName() + " to Comparable.");
}
}
root = new TreeMapEntry<>(key, value, null);
//集合大小为1
size = 1;
//修改次数自增
modCount++;
return null;
}
int cmp;
TreeMapEntry<K,V> parent;
//获取比较器
Comparator<? super K> cpr = comparator;
//如果比较器不空,则用指定的比较器进行比较
if (cpr != null) {
//循环递归,从根节点开始查找插入的位置,即查找的它的父节点,查找方式和我们上面讲的二叉排序树的查找方式相同
do {
parent = t;
cmp = cpr.compare(key, t.key);
//插入值小于当前节点,则继续在左子树上查询
if (cmp < 0)
tt = t.left;
//插入值大于当前节点,则继续在右子树上查询
else if (cmp > 0)
tt = t.right;
//如果相等,则替换当前的值
else
return t.setValue(value);
} while (t != null);
}
//如果比较器为坤宁宫,则使用默认的比较器
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
tt = t.left;
else if (cmp > 0)
tt = t.right;
else
return t.setValue(value);
} while (t != null);
}
//根据查找到的父节点,构造节点,并根据比结果将其插入到对应的位置
TreeMapEntry<K,V> e = new TreeMapEntry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//给插入的节点染色
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
}
插入操作采用了二叉排序树的查找算法,整个流程如下:
如果当前TreeMap没有根节点,将当前节点作为根节点插入,否则,
根据提供的比较器(如果没有提供则使用默认的比较器)进行查找比较,查找该节点的插入位置,即它的父节点的位置。
查找到父节点后,根据比较结果插入到对应位置,并进行染色处理。
remove
前面我们讲了插入操作,删除操作要比插入操作复杂一下,我们先来描述一下删除操作的大概流程:
将红黑树当成一棵二叉查找树,进行节点删除。
通过旋转和着色,使其重新变成一棵复合规则的红黑树。
二叉查找树时怎么做删除的。前面我们已经说过,在二叉查找树上删除一个节点,分为三种情况:
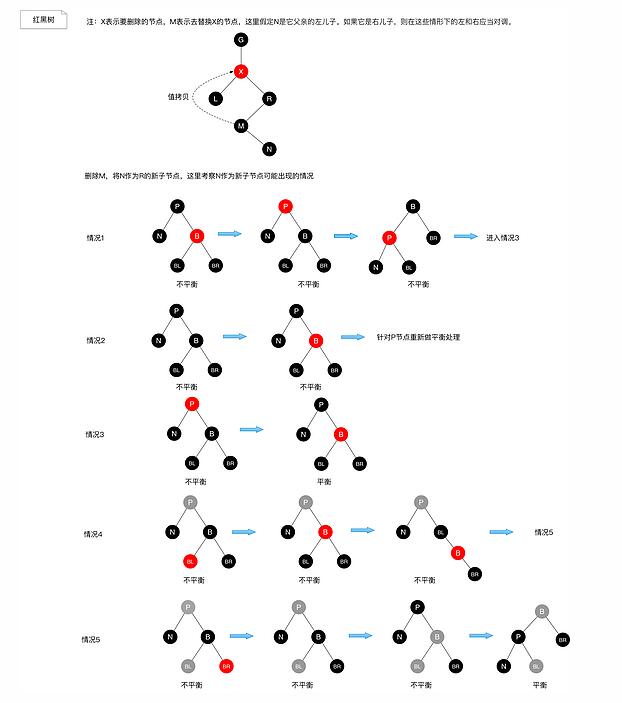
若删除的是叶子节点,则不会破坏树的结构,只需要修改其双亲节点的指针即可。
若删除的节点只有一个孩子节点,则用它的孩子节点代替它的位置即可,如此也不会破坏红黑树的结构。
若删除的节点有两个孩子节点,这种情况复杂一下,我们通常会找到要删除节点X的左子树里的最大元素或者右子树里的最小元素,然后用M替换掉X,再删除节点,因为此时M最多只会有一个
节点(如果左子树最大元素则没有右子节点,若是右子树最小元素则没有左子节点),若M没有孩子节点,直接进入情况1处理,若M只有一个孩子,则直接进入情况2处理。
注:这里的替换指的是值拷贝,值拷贝并不会破坏红黑树的性质。
这样三种情况都可以当做第一种或者第二种情况处理。
在删除节点时,我们有两个问题需要注意:
如果删除的额是红色节点,不会违反红黑树的规则。
如果删除的是黑色节点,那么这个路径上就少了一个黑色节点,则违反了红黑树规则。
这样我们可以得知只有在插入的节点是黑色的时候才需要我们进行处理,具体说来:
情况1:若删除节点N的兄弟节点B是红色,这种情况下,先对父节点P进行左旋操作,结合对换P与B的颜色。此时左子树仍然少了一个黑色节点,此时进入情况3.
情况2:若删除节点N的父亲节点P,兄弟节点B以及B的儿子节点都是黑色,则将B染成红色,这样P到叶子节点的所有路径都包含了相同的黑色节点,但是P的父节点G到叶子节点的路径却少了 一个黑色节点。这个时候我们要重新按照这套规则对P节点再进行一次平衡处理。
情况3:若删除节点N的父亲节点P是红色,兄弟节点B是黑色,则交换P与B颜色,这样在B所在路径上增加了一个黑色节点,弥补了已经删除的,树重新达到平衡。
情况4: 若删除节点N的兄弟节点B是黑涩,B的左孩子节点BL是红色,B的右孩子节点BR是黑色,P为任意颜色。则减缓B与BL的颜色,右旋节点B。此时N所在路径并没有增加黑色节点,没有达到平衡,进入情况5.
情况5:若删除节点N的兄弟节点B是黑色,B的右孩子节点BR是红色,B的左孩子节点BL为任意颜色,P为任意颜色。则BR染成黑色,P染成黑色,B染成原来P的颜色;左旋节点,这样 N路径上增加了一个黑色节点,B路径上少了一个黑色节点B,又增加了一个黑色节点BR,刚好达到平衡。
以上的流程看起来比较复杂,本质上来说就是我们删除了一个黑色节点,破坏了当前路径黑色节点的个数,解决的方法要么为这条路径再添加一个黑色节点,要么将其他路径的黑色节点都去掉一个。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
public V remove(Object key) {
TreeMapEntry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
private void deleteEntry(TreeMapEntry<K,V> p) {
//操作记录自增
modCount++;
//集合大小自减
size--;
///如果要删除的节点p的左右子节点都不为空,则查找其替代节点并进行节点替换
if (p.left != null && p.right != null) {
//查找其替代节点,替代节点为左子树的最大元素或者右子树的最小元素
TreeMapEntry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
//查找替代节点的孩子节点,replacement指的是我们图中说来的N节点,p指的是图中的
TreeMapEntry<K,V> replacement = (p.left != null ? p.left : p.right);
//删除p,并重新建立replacement节点的连接
if (replacement != null) {
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
pp.left = p.right = p.parent = null;
//如果删除的黑色节点,则需要重新平衡树
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
//查找其替代节点,替代节点为左子树的最大元素或者右子树的最小元素
static <K,V> TreeMapEntry<K,V> successor(TreeMapEntry<K,V> t) {
if (t == null)
return null;
//查找右子树的最小元素,即最左孩子
else if (t.right != null) {
TreeMapEntry<K,V> p = t.right;
while (p.left != null)
pp = p.left;
return p;
}
//查找左子树的最大元素,即最右孩子
else {
TreeMapEntry<K,V> p = t.parent;
TreeMapEntry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
pp = p.parent;
}
return p;
}
}
static <K,V> TreeMapEntry<K,V> predecessor(TreeMapEntry<K,V> t) {
if (t == null)
return null;
else if (t.left != null) {
TreeMapEntry<K,V> p = t.left;
while (p.right != null)
pp = p.right;
return p;
} else {
TreeMapEntry<K,V> p = t.parent;
TreeMapEntry<K,V> ch = t;
while (p != null && ch == p.left) {
ch = p;
pp = p.parent;s
}
return p;
}
}
}
我们再来看看deleteEntry()方法的实现流程:
如果要删除的节点p的左右子节点都不为空,则查找其替代节点并进行节点替换。
查找替代节点的孩子节点,replacement指的是我们图中说来的N节点,p指的是图中的M,如果p是黑色节点,则删除p后需要重新进行
树的平衡处理。
get
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable{
public V get(Object key) {
TreeMapEntry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final TreeMapEntry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
TreeMapEntry<K,V> p = root;
//从根节点开始查找,根据比较结果决定从左子树开始查找还是从右子树开始查找
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
pp = p.left;
else if (cmp > 0)
pp = p.right;
else
return p;
}
return null;
}
}
TreeMap的查找流程和二叉查找树的查找流程是一样的,这里是从根节点开始查找,根据比较结果决定是下一步是从左子树开始查找,还是从右子树开始查找。
作者:佚名
来源:51CTO


