


在上一篇文章《大数据背后的神秘公式(上):贝叶斯公式》中我们讲到贝叶斯公式在联邦党人文集作者公案和天蝎号核潜艇搜救中大显身手后,开始引起学术界的注意和重视,而其上世纪八十年代在自然语言处理领域的成功,向我们展示了一条全新的问题解决路径。计算能力的不断提高和大数据的出现使它的威力日益显现,一场轰轰烈烈的“贝叶斯革命”正在发生。
一、 真正的突破
自然语言处理就是让计算机代替人来翻译语言、识别语音、认识文字和进行海量文献的自动检索。但是人类的语言可以说是信息里最复杂最动态的一部分。人们最初想到的方法是语言学方法,让计算机学习人类的语法、分析语句等等。尤其是在乔姆斯基(有史以来最伟大的语言学家)提出 “形式语言” 以后,人们更坚定了利用语法规则的办法进行文字处理的信念。遗憾的是,几十年过去了,在计算机语言处理领域,基于这个语法规则的方法几乎毫无突破。
其实早在几十年前,数学家兼信息论的祖师爷香农 (Claude Shannon)就提出了用数学方法处理自然语言的想法。遗憾的是当时的计算机根本无法满足大量信息处理的需要,所以他的这一想法并没有引起重视。
率先成功利用数学方法解决自然语言处理问题的是语音和语言处理大师贾里尼克 (Fred Jelinek)。他引入一个全新的视角,认为语音识别就是根据接收到的一个信号序列推测说话人实际发出的信号序列(说的话)和要表达的意思。这就把语音识别问题转化为一个通信问题,而且进一步可以简化为用贝叶斯公式处理的数学问题。
一般情况下,一个句子中的每个字符都跟它前面的所有字符相关,这样公式中的条件概率计算就非常复杂,难以实现。为了简化问题,他做了两个假设:
1. 说话人说的句子是一个马尔科夫链,也就是说,句子中的每个字符都只由它前一个字符决定;
2. 独立输入假设,就是每个接受的字符信号只由对应的发送字符决定。
这样的简化看起来有点简单粗暴,每个字符在语义上都是和文章的其他部分相关的,怎么可能只跟它前一个字符相关呢?很多人不相信用这么简单的数学模型能解决复杂的语音识别、机器翻译等问题。其实不光是一般人,就连很多语言学家都曾质疑过这种方法的有效性。但事实证明,这个基于贝叶斯公式的统计语言模型比任何当时已知的借助某种规则的解决方法都有效。贾里尼克和贝克夫妇在七十年代分别独立提出用这个模型进行语音识别,八十年代微软公司用这个模型成功开发出第一个大词汇量连续语音识别系统。现在我们手机上的语音识别和语音输入功能都已经非常成熟而且好用了。
更加可贵的是,这种语音识别系统不但能够识别静态的词库,而且对词汇的动态变化具有很好的适应性,即使是新出现的词汇,只要这个词已经被大家高频使用,用于训练的数据量足够多,系统就能正确地识别。这反映出贝叶斯公式对现实变化的高度敏感,对增量信息有非常好的适应能力。
自然语言处理方面的成功开辟了一条全新的问题解决路径:
1.原来看起来非常复杂的问题可以用贝叶斯公式转化为简单的数学问题;
2.可以把贝叶斯公式和马尔科夫链结合以简化问题,使计算机能够方便求解;虽然我们不完全了解为什么这种看似粗暴的简化并不影响我们的研究过程,但从实践看来它非常有效;
3.将大量观测数据输入模型进行迭代——也就是对模型进行训练,我们就可以得到希望的结果。
随着计算能力的不断提高、大数据技术的发展,原来手工条件下看起来不可思议的进行模型训练的巨大工作量变得很容易实现,它们使贝叶斯公式巨大的实用价值体现出来。
二、 经典统计学的困难和贝叶斯革命
1. 经典统计学的困难
当贝叶斯方法在实际应用中不断证明自己的同时,经典统计学却遇到了困境。经典统计学比较适合于解决小型的问题,同时该方法要求我们获得足够多的样本数据,而且要求这些样本能够代表数据的整体特征。在处理涉及几个参数的问题时,它可以得心应手。但如果相对于问题的复杂程度,我们只掌握少量的信息时,经典统计学就显得力不从心了,原因就是数据的稀疏性问题。
都大数据时代了,还存在数据稀疏性问题吗?答案是肯定的。具体来说,一个取决于n个参数,并且每个参数只有两种表现(0或者1)的系统,共有2的n次方种现象。如果某类癌症的产生过程中有100个基因参与(这其实很保守了,人类总共有几万个基因),那么它有2的100次方种可能的基因图谱;根据采样定理进行估算,采用经典统计学方法至少需要获得1%-10%的样本才能确定其病因,也就是需要制作出数万亿亿亿个患有该疾病的病人的基因图谱!这不具备可操作性。所以用经典统计学方法无法解释由相互联系、错综复杂的原因(相关参数)所导致的现象。
2 .贝叶斯网络带来工具革命
而目前的情况是,相对简单的问题已经解决得差不多了,剩下的都非常复杂。龙卷风的形成、星系的起源、致病基因、大脑的运作机制等,要揭示隐藏在这些问题背后的规律,就必须理解它们的成因网络,把错综复杂的事件梳理清楚。由于经典统计学失效,科学家别无选择,他们必须从众多可能奏效的法则中选择一些可以信任的,并以此为基础建立理论模型。为了能做出这样的选择,为了能在众多可能性中确定他们认为最为匹配的,过去,科学家多少是依靠直觉来弥补数据上的缺失和空白。而贝叶斯公式正好以严谨的数学形式帮他们实现了这一点。科学家把所有假设与已有知识、观测数据一起代入贝叶斯公式,就能得到明确的概率值。而要破译某种现象的成因网络,只需将公式本身也结成网络,即贝叶斯网络,它是贝叶斯公式和图论结合的产物。
网络化想法的提出也不是一帆风顺的。直到上世纪80年代,美国数学家朱迪亚·珀尔才证明,使用贝叶斯网络应该可以揭示复杂现象背后的成因。操作原理是这样的:如果我们不清楚一个现象的成因,首先根据我们认为最有可能的原因来建立一个模型;然后把每个可能的原因作为网络中的节点连接起来,根据已有的知识、我们的预判或者专家意见给每个连接分配一个概率值。接下来只需要向这个模型代入观测数据,通过网络节点间的贝叶斯公式重新计算出概率值。为每个新数据、每个连接重复这种计算,直到形成一个网络图,任意两个原因之间的连接都得到精确的概率值为止,就大功告成了。即使实验数据存在空白或者充斥噪声和干扰信息,不懈追寻各种现象发生原因的贝叶斯网络依然能够构建出各种复杂现象的模型。贝叶斯公式的价值在于,当观测数据不充分时,它可以将专家意见和原始数据进行综合,以弥补测量中的不足。我们的认知缺陷越大,贝叶斯公式的价值就越大
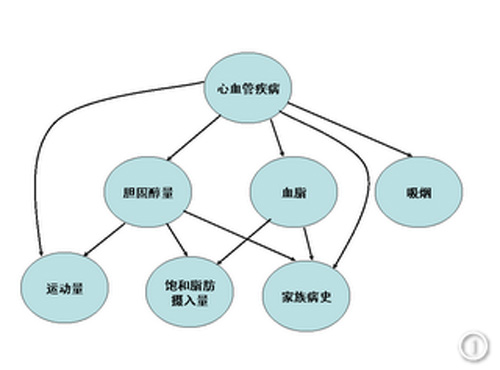
心血管疾病成因的贝叶斯网络
和前面提到的马尔可夫链类似,我们可以假设贝叶斯网络中每个节点的状态值取决于其前面的有限个状态。不同的是,贝叶斯网络比马尔可夫链灵活,它不受马尔可夫链的链状结构的约束,因此可以更准确地描述事件之间的相关性。可以说,马尔可夫链是贝叶斯网络的特例,而贝叶斯网络是马尔可夫链的推广,它给复杂问题提供了一个普适性的解决框架。
为了确定各个节点之间的相关性,需要用已知数据对贝叶斯网络进行迭代和训练。由于网络结构比较复杂,理论上,用现有的计算机是不可计算的(基于冯·诺依曼结构的计算机无法解决这种NP复杂度的问题,NP(Non-deterministic Polynomial)指用非确定机在多项式时间内可以解决的问题类)。但对于一些具体的应用,可以根据实际情况对网络结构(采用网络拓扑的图同构技术)和训练过程进行简化,使它在计算上可行。如果量子计算机开发成功,将能够完全解决其计算问题。这样,贝叶斯公式为科学家开辟的新路就完全打通了。
今天一场轰轰烈烈的“贝叶斯革命”正在发生:生物学家用贝叶斯公式研究基因的致病机制;基金经理用贝叶斯公式找到投资策略;互联网公司用贝叶斯公式改进搜索功能,帮助用户过滤垃圾邮件;大数据、人工智能和自然语言处理中都大量用到贝叶斯公式。既然在手工时代,我们无法预测到今天贝叶斯公式与计算机结合的威力,那么我们怎么能忽视贝叶斯网络与量子计算机结合可能蕴藏的巨大潜力呢?
3.人类大脑的构建方式?
贝叶斯公式不仅在自然科学领域掀起革命,它的应用范围也延伸到了关于人类行为和人类大脑活动的研究领域。教育学家突然意识到,学生的学习过程其实就是贝叶斯公式的运用;心理学家证明贝叶斯方法是儿童运用的唯一思考方法,其他方法他们似乎完全不会。进一步,心理学研究的成果使科学家思考人类的大脑结构是否就是一个贝叶斯网络。这个公式不仅是研究人类思维的工具,它可能就是大脑本身的构建方式。这个观点十分大胆,但获得越来越广泛的认可。因为贝叶斯公式是我们在没有充分或准确信息时最优的推理结构,为了提高生存效率,进化会向这个模式演进。贝叶斯公式突然渗透到一切科学领域,提供了通用的研究框架,这是十分罕见的事情。
人工智能近年来取得了长足的进步,但目前的人工智能通常需要从大量的数据中进行学习,而人类具有“仅从少量案例就形成概念”的能力,两者之间存在巨大差距。比如,尽管你这辈子只见过一个菠萝,但你一眼就能看出菠萝的特征,很快就能从一堆水果中认出菠萝来,甚至还能在纸上画出菠萝的简笔画,而目前的人工智能算法得看成千上万张菠萝的图片才能做到。
不过,这种情况或许已经开始改变了。2015年底,一篇人工智能论文登上了《 科学 》杂志的封面,为人们带来了人工智能领域的一个重大突破: 三名分别来自麻省理工学院、纽约大学和多伦多大学的研究者开发了一个“只看一眼就会写字”的计算机系统。只需向这个系统展示一个来自陌生文字系统的字符,它就能很快学到精髓,像人一样写出来,甚至还能写出其他类似的文字——更有甚者,它还通过了图灵测试,我们很难区分下图中的字符是人类还是机器的作品。这个系统采用的方法就是贝叶斯程序学习(Bayesian Program Learning)——一种基于贝叶斯公式的方法。这不但是人工智能领域的重大突破,而且为我们认识人脑的学习机制提供了重要参考。
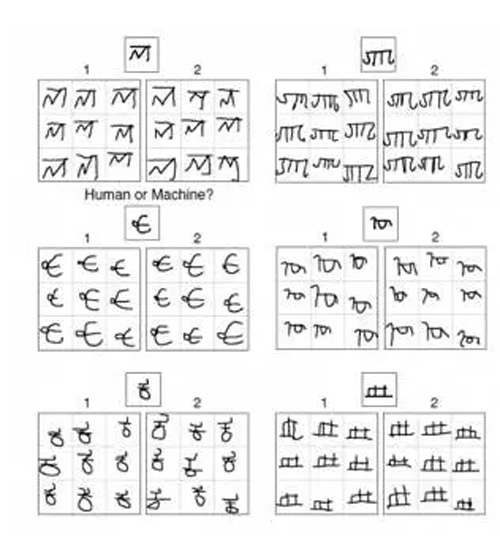
人和机器作品对比图
三 理念的革命
这不仅仅是一场科学的革命,同样也是一场理念的革命。当科学不断强调其对世界认识的客观性时,贝叶斯公式却融入了主观性因素:它并不向我们表述世界,而是表述我们所掌握的知识和经验。这些带有观察者个人因素的知识是脱离研究现象本身的;而它在向我们描述外部现实世界的同时,也描述了观察者对现实的认知的缺陷。更重要的,它迫使我们认识到,科学理论和科学模型反映的是现实的心理意象,而不是现实本身。而现实为我们提供数据,以保证对现实的意象不会离现实本身太远。在寻找各种现象原因的同时,它也在规范着我们的思想。
四 、贝叶斯公式这么牛,与我何干?
我们经常需要在信息不充分或者不准确的情况下进行判断和决策,一条街上哪个饭馆最靠谱?在自习室惊鸿一瞥的女神有没有男朋友?老公的公文包里发现一只口红,他有没有出轨?新开发的App应该等做得尽善尽美再发布,还是应该尽早发布,用互联网的力量帮助它完善?我应该选择哪个工作offer或者还是考公务员才能使自己的收益最大化?
贝叶斯公式为我们提供了一些决策原则:
平时注意观察和思考,建立自己的思维框架,这样在面临选择时就容易形成一个接近实际情况的先验概率,这样经过少量的试错和纠错的迭代循环就可能得到理想的结果;在经过很多次选择和实践的历练后就能够形成自己的直觉,在面对陌生情况时,根据自己的经验和少量信息就能够快速地做出比较准确的判断。
大数据时代获得信息的成本越来越低,社会也变得更加开放和包容,初始状态(先验概率)的重要性下降了,即使最初选择不理想,只要根据新情况不断进行调整,仍然可以取得成功。所以如果当下觉得很难做出选择,那就倾听内心的声音,让直觉来选择,这有利于治疗选择恐惧症。
以开发App的例子来说,先按照自己的想法弄个可用的原型出来,然后充分利用互联网的力量,让活跃的用户社区帮助它快速迭代,逐渐使它的功能和体验越来越好。
对新鲜事物保持开放的心态,愿意根据新信息对自己的策略和行为进行调整。
“大胆假设,小心求证”,“不断试错,快速迭代”,这些都可以看成贝叶斯公式的不同表述。英国哲学家以赛亚·伯林(Isaish Berlin)曾经援引古希腊诗人的断简残片“狐狸多知而刺猬有一大知”,将人的策略分为狐狸和刺猬两类。刺猬用一个宏大的概念解释所有现象,而狐狸知道很多事情,用多元化的视角看待问题,它也愿意包容新的证据以使得自己的模型与之相适应。在这个快速变化的时代,固守一个不变的信条的刺猬很难适应环境的变化,而使用贝叶斯公式的灵活的狐狸才更容易生存。
本文作者:王晓峰
来源:51CTO


