市场上很多玩家已经建造了MapReduce工作流用来日常处理兆兆字节的历史数据。但是谁愿意等待24小时来拿到更新后的分析报告?这篇博客会向你介绍Lambda Architecture,它被设计出来既可以利用批量处理方法,也可以使用流式处理方法。这样我们就可以利用Apache Spark(核心, SQL, 流),Apache Parquet,Twitter Stream等工具处理实时流式数据,实现对历史数据的快速访问。代码简洁干净,而且附上直接明了的示例!
Apache Hadoop: 简要历史
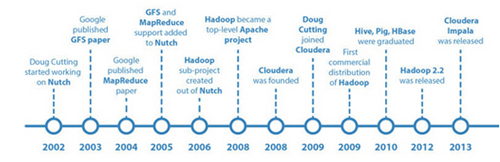
Apache Hadoop的丰富历史开始于大约2002年。Hadoop是Doug Cutting创立的, 他也是Apache Lucene这一被广泛使用的文本检索库的创造者. Hadoop的起源与Apache Nutch有关, Apache Nutch是一个开源的web搜索引擎, 本身也是Lucene项目的一部分. Apache Nutch在大约10年前成为一个独立的项目.
事实上,许多用户实现了成功的基于HadoopM/R的通道,一直运行到现在.现实生活中我至少能举出好几个例子:
- Oozie协调下的工作流每日运行和处理多达8TB数据并生成分析报告
- bash管理的工作流每日运行和处理多达8TB数据并生成分析报告
现在是2016年了
商业现实已经改变,所以做出长远的决定变得更有价值。除此以外,技术本身也在演化进步。Kafka, Storm, Trident, Samza, Spark, Flink, Parquet, Avro, Cloud providers等时髦的技术被工程师们和在商业上广泛使用.
因此,现代基于Hadoop的 M/R通道 (以及Kafka,现代的二进制形式如Avro和数据仓库等。在本例中Amazon Redshift用作ad-hoc查询) 可能看起来像这样:
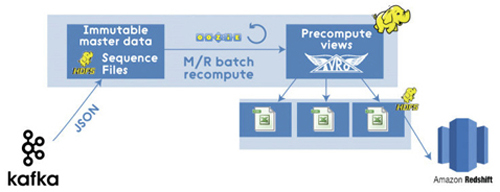
以上M/R通道看起来很不错,但是它仍然是传统上具有许多缺点的批处理。由于在新数据不断进入系统时,批处理过程通常需要花费很多时间来完成,它们主要是提供给终端用户的乏味的数据罢了。
Lambda 架构
Nathan Marz为通用,可扩展和容错性强的数据处理架构想出了一个术语Lambda架构。这个数据架构结合了批处理和流处理方法的优点来处理大批量数据。
我强烈推荐阅读 Nathan Marz 的书 ,这本书从源码角度对Lambda架构进行了完美的诠释。
层结构
从顶层来看,这是层的结构:
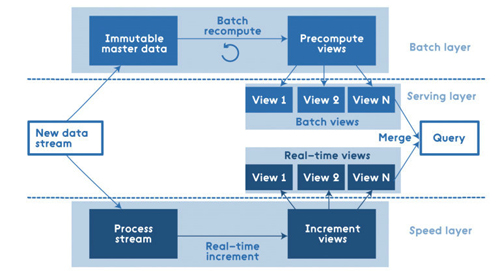
所有进入系统的数据被分配到了批处理层和高速层来处理。批处理层管理着主数据集(一个不可修改,只能新增的原始数据)和预计算批处理视图。服务层索引批处理视图,因此可以对它们进行低延时的临时查询。高速层只处理近期的数据。任何输入的查询结果都合并了批处理视图和实时视图的查询结果。
焦点
许多工程师认为 Lambda架构就包含这些层和定义数据流程,但是 Nathan Marz在他的书中把焦点放在了其他重要的地方,如:
- 分布式思想
- 避免增量架构
- 关注数据的不可变性
- 创建再计算算法
- 数据的相关性
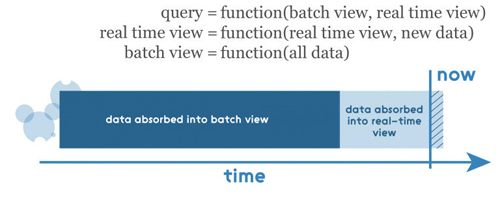
正如前面所提到的,任何输入的查询结果都会从批处理视图和实时视图的查询结果返回,因此这些视图需要被合并。在这里,需要注意的一点是,一个实时视图是上一个实时视图和新的数据增量的函数,因此一个增量算法可以在这里使用。批处理视图是所有数据的视图,因此再计算算法可以在这里使用。
均衡取舍
我们生活中的一切问题都存在权衡,Lambda架构(Lambda Architecture)不例外。 通常,我们需要解决几个主要的权衡:
完全重新计算vs.部分重新计算
某些情况下,可以考虑使用Bloom过滤器来避免完全重新计算
重算算法 vs. 增量算法
使用增量算法是个很大的诱惑,但参考指南,我们必须使用重算算法,即使它更难得到相同的结果
加法算法 vs. 近似算法
Lambda Architecture 能与加法算法很好地协同工作。 因此,在另一种情况下,我们需要考虑使用近似算法,例如,使用HyperLogLog处理count-distinct的问题等。
实现
有许多实现Lambda架构的方法,因为对于每个层的底层解决方案是非常独立的。每个层需要底层实现的特定功能,有助于做出更好的选择并避免过度决策:
批量层(Batch Layer):写一次,批量读取多次
服务层(Serving layer):随机读取,不支持随机写入,批量计算和批量写入
速度层(Speed layer):随机读取,随机写入;增量计算
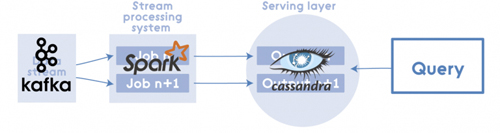
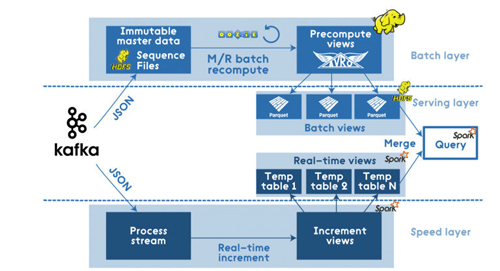
例如,其中一个实现方案的构成(使用Kafka,Apache Hadoop,Voldemort,Twitter Storm,Cassandra)可能如下图所示:
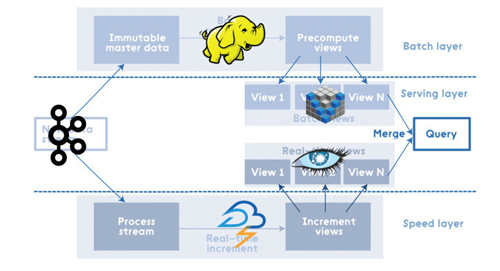
Apache Spark
Apache Spark可以被认为是用于Lambda架构各层的集成解决方案。其中,Spark Core 包含了高层次的API和优化的支持通用图运算引擎,Spark SQL用于SQL和结构化数据处理、 Spark Streaming 可以解决高拓展、高吞吐、容错的实时流处理。在批处理中使用Spark可能小题大做,而且不是所有方案和数据集都适用。但除此之外,Spark算是对Lambda Architecture的合理的实现。
示例应用
下面通过一些路径创建一个示例应用,以展示Lambda Architecture,其主要目的是提供#morningatlohika tweets(一个由我在Lviv, Ukraine发起的本地技术演讲,)这个hash标签的统计:包括之前到今天这一刻的所有时间。
源码在GitHub 上,有关这个主题的更多信息可以在Slideshare上找到。
批处理视图(Batch View)
简单地说,假定我们的主数据集包含自开始时间以来的所有更新。 此外,我们已经实现了一个批处理,可用于创建我们的业务目标所需的批处理视图,因此我们有一个预计算的批处理视图,其中包含所有与#morningatlohika相关的标签统计信息:

编号很容易记住,因为,为方便查看,我使用对应标签的英文单词的字母数目作为编号。
实时视图
假设应用程序启动后,同时有人发如下tweet:
“Cool blog post by @tmatyashovsky about #lambda #architecture using #apache #spark at #morningatlohika”
此时,正确的实时视图应该包含如下的hash标签和统计数据(本例中都是1,因为每个hash标签只用了一次):

查询
当终端用户查询出现是,为了给全部hash标签返回实时统计结果,我们只需要合并批处理视图和实时视图。所以,输出如下所示编码(hash标签的正确统计数据都加了1):

场景
示例中的场景可以简化为如下步骤:
用Apache Spark创建批处理视图(.parquet)
在Spark中缓存批处理视图
将流处理应用连接到Twitter
实时监视包含#morningatlohika 的tweets
构造增量实时视图
查询,即,即时合并批处理视图和实时视图
技术细节
此源代码是基于Apache Spark 1.6.x(注:再引入结构流之前)。 Spark Streaming架构是纯微型批处理架构:
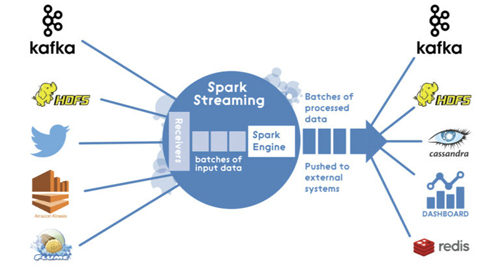
所以当我处理一个流媒体应用程序时,我使用DStream来连接使用TwitterUtils的Twitter:

在每个微批次中(使用可配置的批处理间隔),我正在对新tweets中的hashtags统计信息进行计算,并使用updateStateByKey()状态转换函数来更新实时视图的状态。简单地说,就是使用临时表将实时视图存储在存储器中。
查询服务反映了批处理的合并过程和通过代码表示的DataFrame实时视图:
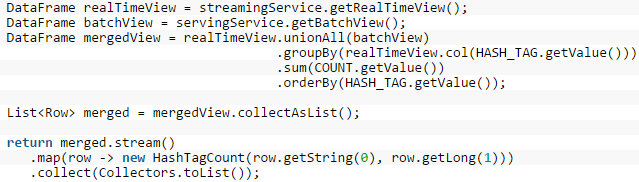
成果
在简化的方案下,文章开头提到的基于Hadoop 的M/R 管道可以通过Apache Spark进行如下优化:
本章结语
正如上文提到的 Lambda架构有优点和缺点,所以结果就是有支持者和反对者。一些人会说批处理视图和实时视图有很多重复的逻辑,因为最终他们需要从查询的角度创建出可以合并的视图。因此,他们创建了Kappa架构——一个Lambda架构的简化方案。Kappa 架构的系统去掉了批处理系统,取而代之的是数据从流处理系统中快速通过:
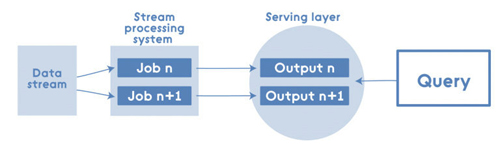
即便在此场景中,Spark也能发挥作用,比如,参与流处理系统: