

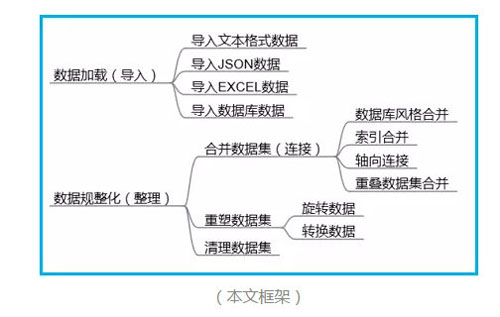
数据加载
导入文本数据
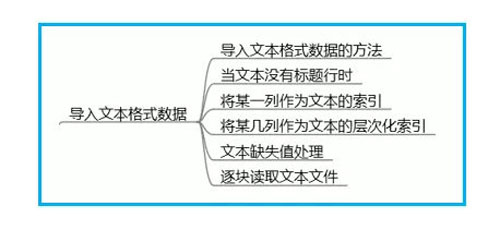
1、导入文本格式数据(CSV)的方法:
方法一:使用pd.read_csv(),默认打开csv文件。

9、10、11行三种方式均可以导入文本格式的数据。
特殊说明:第9行使用的条件是运行文件.py需要与目标文件CSV在一个文件夹中的时候可以只写文件名。第10和11行中文件名ex1.CSV前面的部分均为文件的路径。
方法二:使用pd.read.table(),需要指定是什么样分隔符的文本文件。用sep=””来指定。

2、当文件没有标题行时
可以让pandas为其自动分配默认的列名。
也可以自己定义列名。

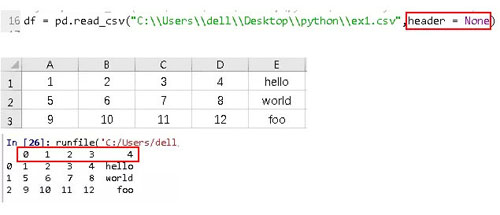
3、将某一列作为索引,比如使用message列做索引。通过index_col参数指定’message’。

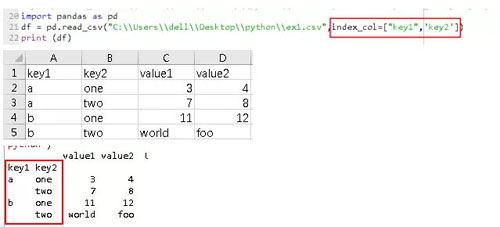
4、要将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可。
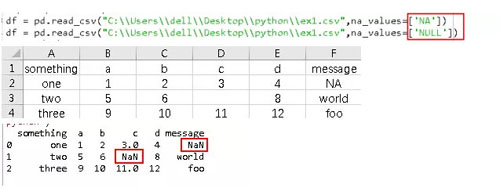
5、文本中缺失值处理,缺失数据要么是没有(空字符串),要么是用某个标记值表示的,默认情况下,pandas会用一组经常出现的标记值进行识别,如NA、NULL等。查找出结果以NAN显示。
6、逐块读取文本文件
如果只想读取几行(避免读取整个文件),通过nrows进行制定即可。

7、对于不是使用固定分隔符分割的表格,可以使用正则表达式来作为read_table的分隔符。

(’\s+’是正则表达式中的字符)。
导入JSON数据
JSON数据是通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标注形式之一。通过json.loads即可将JSON对象转换成Python对象。(import json)
对应的json.dumps则将Python对象转换成JSON格式。
导入EXCEL数据

直接使用read_excel(文件名路径)进行获取,与读取CSV格式的文件类似。
导入数据库数据
主要包含两种数据库文件,一种是SQL关系型数据库数据,另一种是非SQL型数据库数据即MongoDB数据库文件。
数据库文件是这几种里面比较难的,本人没有接触数据库文件,没有亲测,所以就不贴截图了。
数据整理
合并数据集
1、数据库风格的合并
数据库风格的合并与SQL数据库中的连接(join)原理一样。通过调用merge函数即可进行合并。

当没有指明用哪一列进行连接时,程序将自动按重叠列的列名进行连接,上述语句就是按重叠列“key”列进行连接。也可以通过on来指定连接列进行连接。

当两个对象的列名不同时,即两个对象没有共同列时,也可以分别进行指定。
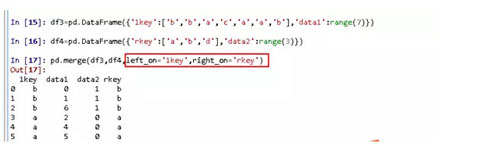
Left_on是指左侧DataFrame中用作连接的列。
right_on是指右侧DataFrame中用作连接的列。
通过上面的语句得到的结果里面只有a和b对应的数据,c和d以及与之相关的数据被消去,这是因为默认情况下,merge做的是‘inner’连接,即sql中的内连接,取得两个对象的交集。也有其他方式连接:left、right、outer。用“how”来指明。

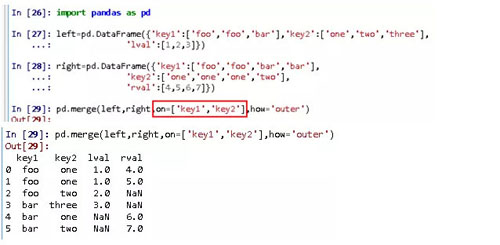
也可以根据多个键(列)进行合并,用on传入一个由列名组成的列表即可。
2、索引上的合并
(1)普通索引的合并
Left_index表示将左侧的行索引引用做其连接键
right_index表示将右侧的行索引引用做其连接键
上面两个用于DataFrame中的连接键位于其索引中,可以使用Left_index=True或right_index=True或两个同时使用来进行键的连接。

(2)层次化索引
与数据库中用on来根据多个键合并一样。
3、轴向连接(合并)
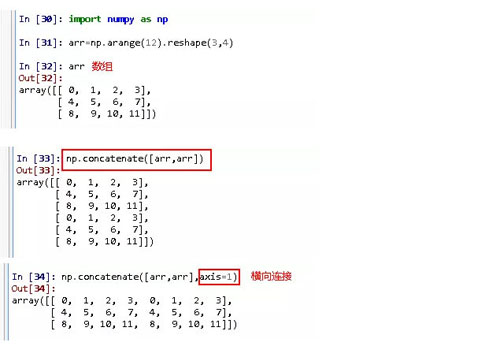
轴向连接,默认是在轴方向进行连接,也可以通过axis=1使其进行横向连接。
(1)对于numpy对象(数组)可以用numpy中的concatenation函数进行合并。
(2)对于pandas对象(如Series和DataFrame),可以pandas中的concat函数进行合并。

·4、合并重叠数据
对于索引全部或部分重叠的两个数据集,我们可以使用numpy的where函数来进行合并,where函数相当于if—else函数。

对于重复的数据显示出相同的数据,而对于不同的数据显示a列表的数据。同时也可以使用combine_first的方法进行合并。合并原则与where函数一致,遇到相同的数据显示相同数据,遇到不同的显示a列表数据。

重塑数据集
1、旋转数据
(1)重塑索引、分为stack(将数据的列旋转为行)和unstack(将数据的行旋转为列)。
(2)将‘长格式’旋转为‘宽格式’
2、转换数据
(1)数据替换,将某一值或多个值用新的值进行代替。(比较常用的是缺失值或异常值处理,缺失值一般都用NULL、NAN标记,可以用新的值代替缺失标记值)。方法是replace。

一对一替换:用np.nan替换-999

多对一替换:用np.nan替换-999和-1000.

多对多替换:用np.nan代替-999,0代替-1000.
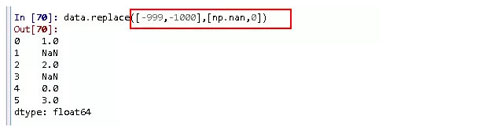
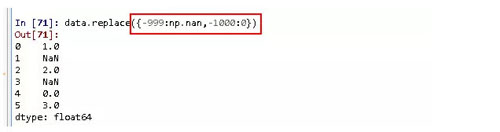
也可以使用字典的形式来进行替换。
(2)离散化或面元划分,即根据某一条件将数据进行分组。
利用pd.cut()方式对一组年龄进行分组。

默认情况下,cut对分组条件的左边是开着的状态,右边是闭合状态。可以用left(right)=False来设置哪边是闭合的。

清理数据集
主要是指清理重复值,DataFrame中经常会出现重复行,清理数据主要是针对这些重复行进行清理。

利用drop_duplicates方法,可以返回一个移除了重复行的DataFrame.

默认情况下,此方法是对所有的列进行重复项清理操作,也可以用来指定特定的一列或多列进行。

默认情况下,上述方法保留的是第一个出现的值组合,传入take_last=true则保留最后一个。

