
本篇将介绍前端本地存储里的Web SQL和IndexedDB,通过一个案例介绍SQL的一些概念。
1. 地图报表的案例
现在要做一个地图报表,如下图所示:
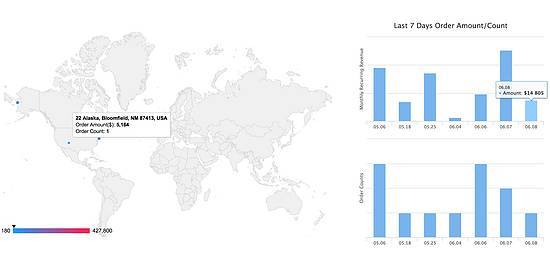
将所有的订单数据做一个图表展示,左边的地图展示每个city的成单情况,右边的图形,展示最近7天的成单情况。由于后端的数据需要前端做一些解析,如向谷歌请求每个city的经纬度,所以后端给前端原始的订单数据,前端进行格式化和归类展示。另外把原始数据直接放前端,前端处理起来可以比较灵活,想怎么展示就怎么展示,不用每次展示方式变的时候都需要找后端新加接口。
但是数据放在前端管理,相应地就会引入一个问题——如何高效地存储和使用这些数据。最起码处理起来不要让页面卡了。
2. cookie和localStorage
—cookie的数据量比较小,浏览器限制最大只能为4k,而—localStorage和sessionStorage适合于小数据量的存储,firefox和Chrome限制最大存储为5Mb,如下火狐的config:

localStorage是存放在一个本地文件里面,在笔者的Mac上是放在:
/Users/yincheng/Library/Application Support/Google/Chrome/Default/Local Storage/ http_www.test.com.localstorage
用文本编辑器打开这个二进制文件,可以看到本地存储的内容:

可以参照控制台的输出:
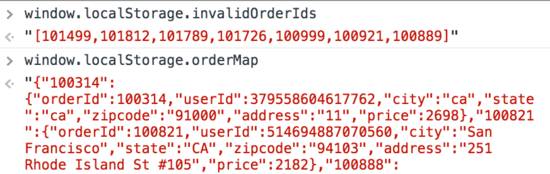
如果一个网站要用掉5Mb硬盘空间,那么打开过一百个网页就得花500Mb的空间,所以本地存储localStorage的空间限制得比较小。
另外,可以看到localStorage是以字符串的方式存储的,存之前要先JSON.stringify变成字符串,取的时候需要用JSON.parse恢复成相应的格式。localStorage适合于比较简单的数据存放和管理。
3. 管理复杂数据
后端给我这样的JSON数据:
- [
- {“orderId”:100314,”userId”:379558604617762,”city”:”ca”,”state”:”ca”,”zipcode”:”91000″,”address”:”11″,”price”:2698.00,”createTime”:1477651308000},
- {“orderId”:100821,”userId”:514694887070560,”city”:”San Francisco”,”state”:”CA”,”zipcode”:”94103″,”address”:”251 Rhode Island St #105″,”price”:2182.00,”createTime”:1481104358000}
- ]
我用这些数据去请求它们的经纬度。
这些数据的量比较大,有成百上千甚至几万条数据,—数据需要复杂的查询,需要支持:
- 订单按日期分类和排序
- 订单按照city分类
—如果自己管理JSON数据就会比较麻烦,所以这里尝试使用Web SQL来管理这些数据。
4. Web SQL
(1)什么是SQL
SQL作用在关系型数据库上面,什么是关系型数据库?关系型数据库是由一张张的二维表组成的,如下图所示:
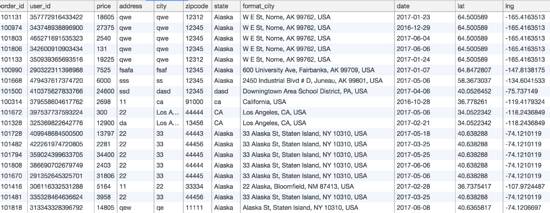
那什么是SQL呢?SQL是一种操作关系型DB的语言,支持创建表,插入表,修改和删除等等,还提供非常强大的查询功能。
常见的关系型数据库厂商有MySQL、SQLite、SQL Server、Oracle,由于MySQL是免费的,所以企业一般用MySQL的居多。
Web SQL是前端的数据库,它也是本地存储的一种,使用SQLite实现,SQLite是一种轻量级数据库,它占的空间小,支持创建表,插入、修改、删除表格数据,但是不支持修改表结构,如删掉一纵列,修改表头字段名等。但是可以把整张表删了。同一个域可以创建多个DB,每个DB有若干张表,如下图示意:
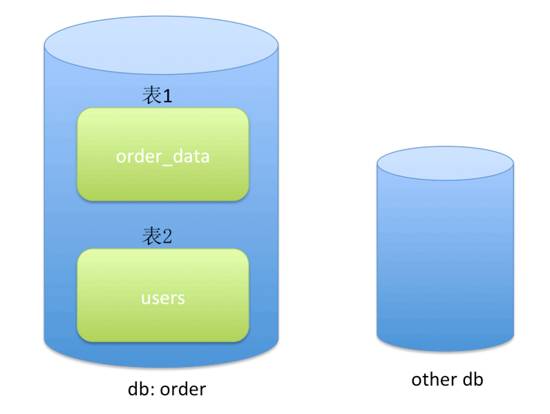
(2)创建一个DB
如下代码所示:
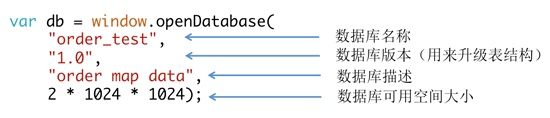
使用openDatabase,传4个参数,指定数据库大小,如果指定太大,浏览器会提示用户是否允许使用这么多空间,如Safari的提示:
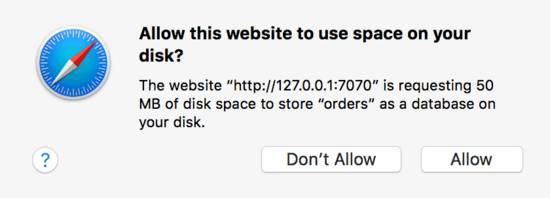
如果不允许,浏览器将会抛异常:
QuotaExceededError (DOM Exception 22): The quota has been exceeded.
这样就创建了一个数据库叫order_test,返回了一个db对象,使用这个db对象创建一张表
(3)创建表
如下代码所示:
- db.transaction(function(tx){
- tx.executeSql("create table if not exists order_data(order_id primary key, format_city, lat, lng, price, create_time)", [], null, function(tx, err){
- throw(`execute sql failed: ${err.code} ${err.message}`);
- });
- });
传一个回调给db.transaction,它会传一个SQLTransaction的实例,它表示一个事务,然后调executeSql函数,传四个参数,第一个参数为要执行的SQL语句,第二个参数为选项,第三个为成功回调函数,第四个为失败回调函数,这里我们抛一个异常,打印失败的描述。我们执行的SQL语句为:
create table if not exists order_data(order_id primary key, format_city, lat, lng, price, create_time)
意思是创建一张order_data表,它的字段有6个,第一个order_id为主键,主键用来标志这一列,并且不允许有重复的值。
现在往这张表插入数据。
(4)插入数据
准备好原始数据和对数据做一些处理,如下所示:
- var order = {
- orderId: 100314, format_city: "New York, NY, USA",
- lat: 40.7127837, lng: -74.0059413, price: 150, createTime: 1473884040000};//把时间戳转成年月日2017-06-08类型的var date = dataProcess.getDateStr(order.createTime);
然后执行插入:
- tx.executeSql(`insert into order_data
- values(${order.orderId}, '${order.format_city}',
- ${order.lat}, ${order.lng}, ${order.price}, '${date}')`);
就可以在浏览器控制台看到刚刚创建的数据库、表,如下图所示:
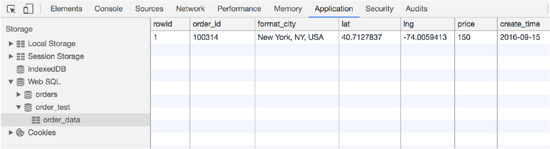
如果把刚刚的那条数据再插入一遍会怎么样呢?如刷新一下页面,它又重新执行。
(5)主键唯一约束
插入一个重复主键,这里为id,executeSql的失败函数将会执行,如下所示:

所以一般id是自动生成的,mysql可以指定某个整数字段为auto_increment,而web sql对整数字段不指定也是auto_increment,需要在创建的时候指定当前字段为integer,如下语句:
- create table student(id integer primary key
- auto_increment
- , age, score);
作用是创建一张student表,它的id是自动自增的,执行insert插入时会自动生成一个id:
- insert into student(grade, score) values(5, 88);
这样插入几次,得到如下表:
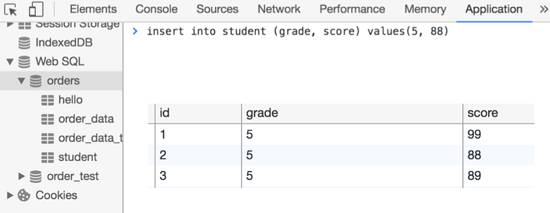
可以看到id由1开始自动增长。经常利用这种自增功能生成用户的id、订单的id等等。
上面指定了id为整型,就不能插入一个字符串的数据,否则会报错。而如果没指定,可以插入数字也可以插入字符串,当然同一字段最好类型要一致。如mysql、SQL Server等数据库都是强类型的。
这里有一个细节需要注意,后端的mysql的id一般采用64位的长整型,这个数最大值为一个19位数:
9223372036854775807
而JS的最大整数为一个16位数,大于这个数的值将会是不可靠的,如下图所示:

因此如果发生这种情况的话,需要让后端把ID当作字符串的方式传给你。这个我在《 为什么0.1 + 0.2不等于0.3? 》这篇文章里面做过讨论。
(6)全部的数据
把所有的数据都插入之后,得到如下表:
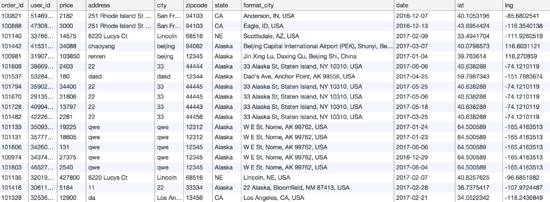
然后我们开始做查询。
(7)Select查询
—a)查出每个城市的单数和,按日期升序。便于地图按city展示,可以执行以下SQL:
- — select format_city as city, count(order_id) as ‘count’, sum(price) as amount from order_data group by format_city order by date
结果如下图所示:
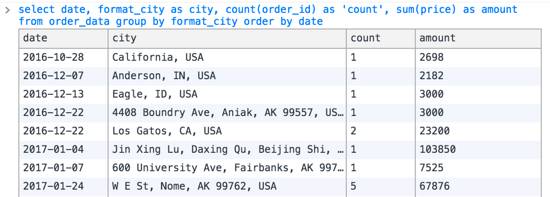
b)然后再—查一下最近7天每一天的单数,用于右边柱状图的展示,执行以下SQL:
- —select date, count(order_id) as ‘count’, sum(price) as amount from order_data group by date order by date desc limit 0, 7
得到:
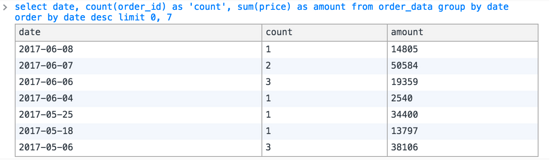
c)查询某个orderId是否存在,因为数据需要动态更新,例如每两个小时更新一次,如果有新数据需要去查询格式化的地址以及经纬度。而每次请求都是拉取全部数据,因此需要找出哪些是新数据。可以执行:
- — select order_id from order_data where order_id = ${order.orderId}
如果返回空的结果集,说明这个orderId不存在。
上面是在控制台执行,在代码里面怎么获取结果呢,如下图所示:

某些字段可能会被重复查询,如order_id,format_city,如果对这些字段做一个索引,那么可以提高查询的效率。
(8)建立索引
由于order_id是主键,自动会有索引,其它字段需要手动创建一个索引,如对format_city添加一个索引可执行:
- — create index if not exists index_format_city on order_data(format_city)
为什么创建索引可以提高查询效率呢?因为如果没建索引要找到某个字段等于某个值的数据,需要遍历所有的数据条项,查找复杂度为O(N),而建立索引一般是使用二叉查找树或者它的变种,查找复杂度变成O(logN),mysql是使用的B+树。有兴趣的可继续查找资料。
另外字符串可使用哈希变成数字,字符串索引要比数字低效很多。
使用索引的代价是增加存储空间,降低插入修改的效率。所以索引不能建太多,如果查询的次数要明显高于修改那么建立索引是好的,相反如果某个字段需要被频繁修改,那可能不太适合建立索引。
5. 关系型数据库的优缺点
(1)优点
—SQL支持非常复杂的查询,可以联表查询、使用正则表达式查询、嵌套查询,还可以写一个独立的SQL脚本。
上面的案例,—如果不使用SQL,那两个查询自己写代码筛选数据也可以实现,但是会比较麻烦,特别是数据量比较大的时候,如果算法写得不好,就容易有性能问题。而使用DB数据的查询性能就交给DB。它还是异步的,不会有堵塞页面的情况。
(2)缺点
一般来说,存在以下缺点:—
不方便横向扩展,例如给数据库表添加一个字段,如果数据量达到亿级,那么这个操作的复杂性将会是非常可观的。—
—海量数据用SQL联表查询,性能将会非常差。
—关系型数据库为了保持事务的一致性特点,难以应对高并发
(3)Web SQL被deprecated
在 w3c的文档 上,可以看到:
—This document was on the W3C Recommendation track but specification work has stopped. The specification reached an impasse: all interested implementors have used the same SQL backend (Sqlite), but we need multiple independent implementations to proceed along a standardisation path.
大意是说WebSQL现有的实现是基于现成的第三方SQLite,但是我们需要独立的实现。火狐也不打算支持。也就是说主要原因是web sql太过于依赖SQLite,或许W3C可能会在以后重新制订一套标准。
虽然已经不建议使用了,但是上面还是花了很多篇幅介绍web sql,主要是因为SQL是通用的,我的主要目的并不是要向读者介绍web sql的API,怎么使用web sql,而是给读者介绍一些SQL的核心概念,如怎么建表,怎么插入数据,毕竟SQL是通用的,就算再过个几十年它也很难会过时。
接下来再介绍第二种数据库非关系型数据库
6. 非关系型数据库
非关系型数据库根据它的存储特点,常用的有:
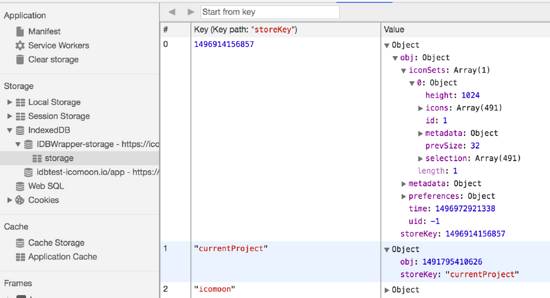
(1)key-value型,如Redis/IndexedDB,value可以为任意数据类型,如下图所示:
(2)json/document型,—如MongoDB,value按照一定的格式,可对value的字段做索引,IndexedDB也支持,如下图所示:
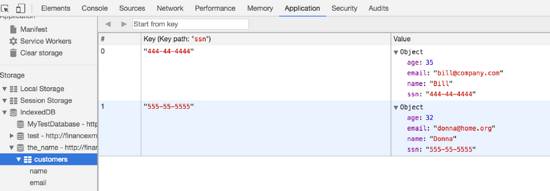
非关系型数据库也叫NoSQL数据库。
—NoSQL是Not Only SQL的简写,意思为不仅仅是SQL,但其实它和SQL没什么关系,只是为了不让人觉得它太异类。它的特点是存储比较灵活,但是查找没有像关系型SQL一样好用。适用于数据量很大,只需要单表key查询,一致性不用很高的场景。
7. IndexedDB
(1)IndexedDB的一些概念
IndexedDB是本地存储的第三种方式,它是非关系型数据库。它的建立数据库、建表、插入数据等操作如下代码如下,这里不进行拆分讲解,具体API细节读者可查MDN等相关文档。
- //创建和打开一个数据库var request = window.indexedDB.open("orders", 7);var db = null;
- request.onsuccess = function(event){
- db = event.target.result;
- //如果order_data表已经存在,则直接插入数据 if(db.objectStoreNames.contains("order_data")){
- var orderStore = db.transaction("order_data", "readwrite").objectStore("order_data");
- //insertOrders(orderStore); }
- };
- request.onupgradeneeded = function(event){
- db = event.target.result;
- //如果order_data表不存在则创建,并插入数据 if(!db.objectStoreNames.contains("order_data")){
- var orderStore = db.createObjectStore("order_data", {keyPath: "orderId"});
- insertOrders(orderStore);
- }
- };
- function insertOrders(orderStore){
- var orders = orderData.data;
- for(var i = 0; i < orders.length; i++){
- orderStore.add(orders[i]); //add是一个异步的操作,返回一个IDBRequest,有onsucess }
- }
执行完之后就有了一张order_data的表,如下所示:
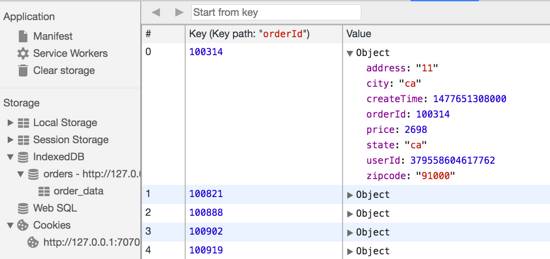
—现在要查询某个orderId的数据,可执行以下代码:
- function query(orderId){
- db.transaction("order_data", "readonly") //IDBTransaction .objectStore("order_data") //IDBObjectStore .get(orderId) //IDBRequest .onsuccess = function(event){
- var order = event.target.result;
- console.log(order)
- };
- }
结果如下图所示:

怎么查询value字段里面的数据呢?如要查询state为CA的订单,那么给state这个字段添加一个索引就可以查询 了,如下所示:

这里就可以知道,为什么要叫IndexedDB或者索引数据库了,因为它主要是通过创建索引进行查询的。
上面只返回了一个结果,但是一般需要获取全部的结果,就得使用游标cursor,如下代码所示:
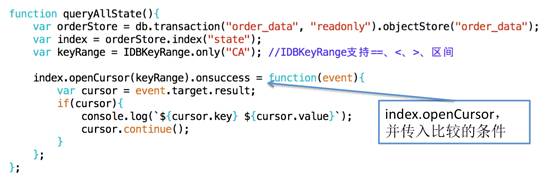
打印结果如下:

IndexedDB还支持插入json格式不一样的数据,如下代码:
- var specilaData = {
- orderId: 'hello, world',
- text: "goodbye, world"};
- var orderStore = db.transaction("order_data", "readwrite").objectStore("order_data");
- orderStore.add(specilaData).onsuccess = function(event){
- orderStore.get('hello, world').onsuccess = function(event){
- console.log(event.target.result);
- };
- };
结果如下图所示:

(2)非关系型数据库的横向扩展
上面说关系型数据库不利于横向扩展,而在一般的非关系型数据库里面,每个数据存储的类型都可以不一样,即每个key对应的value的json字段格式可以不一致,所以不存在添加字段的问题,而相同类型的字段可以创建索引,提高查询效率。
—NoSQL做不了复杂查询,如上面的案例要按照日期/city归类的话,需要自己打开一个游标循环做处理。所以我选择用Web SQL主要是这个原因。
(3)兼容性
WebSQL兼容性如下caniuse所示:
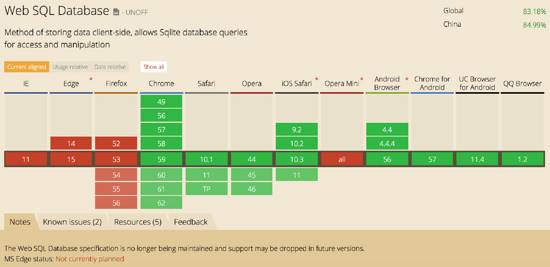
主要是IE和火狐不支持,而IndexedDB的兼容性会好很多:

8. 数据库与Promise
—数据库的查找,添加等都是异步操作,有时候你可能需要先发个请求获取数据,然后插入数据,重复N次之后,再查询数据。例如我需要先一条条地向谷歌服务器解析地址,再插入数据库,然后再做查询。在查询数据之前需要保证数据已经都全部写到数据库里面了,可以用Promise解决,在保证效率的同时达到目的。如下代码所示:

9. SQL注入
谈SQL一般会离不开SQL注入的话题,什么是SQL注入攻击呢?
—假设有个表单,支持用户查询自己在某个地方的订单,如下图所示:

所写的SQL语句是这样的:
- — select * from order_data where user_id = 514694887070560 and state = ‘${userData.state}’
—userId根据用户的登陆信息可以知道,而state则使用用户传来的数据,那么就变成了一道填(song)空(ming)题,如下图所示:

正常的查询如下图所示:

现在进行脚本注入,如我要查一下所有用户的订单情况,如下所示:
- — select * from order_data where user_id = 514694887070560 and state = ‘ CA’ union select * from order_data where ”=’ ‘;
加粗的字就是我在空格里面填入的东西,它就会拼成一句合法的SQL语句——查询order_data表的所有数据,结果如下:

由于数据库是放在远程服务器,我怎么知道你这张表叫做order_data呢?这就需要猜,根据一般的命名习惯,如果order_data不对,那么对方服务将会返回出错,那就再换一个,如order/orders等,不断地猜,一般可以在较少次数内猜中。
—我还猜测有张用户表,存放着用户的密码,要查一下某个人的密码,执行以下SQL语句:
- —select * from order_data where user_id = 514694887070560 and state = ‘CA’ union select order_id, order_data.user_id, price, address, user.password as city , zipcode, state, format_city, date, lat, lng from order_data join user on user.user_id = order_data.user_id and ”=”;
结果如下:
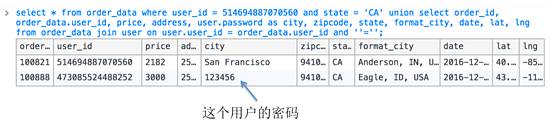
第二个city就是那个用户的密码,如果数据库是明文存储密码,那就更便利了。
—还可以再做一些增删改的操作,这个就比查询其它用户信息更危险了。那怎么防止SQL注入呢?
——如果字段类型是数字,则没有注入的风险,而如果字段是字符串则存在。需要把字符串里面的引号进行转义把它变成查询的内容,在引号里面是使用连在一起的两个引号表示一个引号。
—更常见的是底层框架先把sql语句编译好,传进来的字符串只能做为内容查询,这种通常是最安全的,就是有时候不太灵活,特别是查询条件比较多样时,如果一个条件就写一句sql还是挺烦的,并且条件还可以组合。
10. 分布式数据库
—如果网站日访问量太大,一个数据库服务很可能会扛不住,需要搞几台相同的数据库服务器分担压力,但是要保证这几个数据库数据一致性。这个有很多解决方案,最简单的如mysql的repliaction:
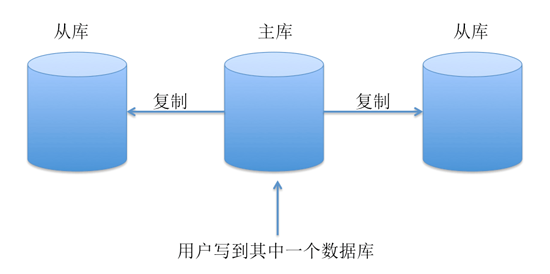
假设线上有3个数据库,用户的一个操作写到了其中的一个数据库里面,这个库就叫主库master,其它两个库叫从库slave,主库会把新数据远程复制到另外两个从库。
11. 数据库备份
谈到数据库离不开另外一个话题——备份,备份很重要,假设你的网站某一天被攻击了,一夜之间几十万个用户的数据没了,要是找不回来,或者写了十年的博客全没了,就真的得一夜白头了。例如笔者会不对期地对自己的博客网站做备份:
用wordpress和db的备份文件,可以在一个小时之内从0恢复整个博客网站。
备份mysql数据库可以执行mysqldump的命令,以root用户的身份:
- mysqldump order > order.bak.mysql –u root –p
就可以把order这个数据库备份起来,恢复的时候只需执行:
- mysql -u root -p < order.bak.mysql
就可以把order这个数据库导进来。
综合以上,本文谈到了本地存储的三种方式:
- localStorage/sessionStorage
- Web SQL
- IndexedDB
并比较了它们的特点。还谈了下DB结合Promise做一些操作和SQL注入等。
最主要是分析了关系型数据库和非关系型数据库的特点,关系型数据库是一名老将,而非关系型随着大数据的产生应运而生,但它又不局限于在大数据上使用。html5也增加了这两种类型的数据库,为做Web Application做好准备。虽然Web SQL很早前被deprecated,但是只要你不用支持IE和Firefox还是可以用的,它的好处是查询比较方便,而IndexedDB存储比较灵活,查询不方便。说不定在不久的将来会有一种全新的web关系型数据库出现。现在很多网站都使用IndexedDB存储它们的数据。
所以可以两者尝试学习和使用一下,一方面为做那种数据驱动类型的网页提供便利,另一方面可以对数据库的概念有所了解,知道后端是如何建表如何查询数据返回给你的。
作者:人人网FED博客
来源:51CTO

