

系列:loopat 三篇实践笔记
上一篇:01|我蹲了一下 loopat:它不是又一个 Agent,而是把上下文当成工作区来管
下一篇:03|如果把 loopat 放进团队:我会怎么设计协作规则
这一篇只聊架构:为什么它要搞 Loop、sandbox、vault、git worktree,而不是简单套个 Agent 聊天界面。

一、先说我的直觉:它在反对"一次性会话"
我看 loopat 的时候,脑子里一直有个词:现场。
现在很多 Agent 工具的问题是,会话结束就散场。你这次解释过的背景、这次做过的判断、这次试错过的命令,下次还要再来一遍。
loopat 想把这些东西留住。不是靠一条 memory,而是靠一个可复现的工作现场。
这个现场就叫 Loop。
二、Loop:不是任务卡,是 AI 工作现场
官网给的公式:
Loop = context + AI + workdir
拆开看就是:
context:聊天、知识、记忆、notesAI:Claude Agent SDKworkdir:一个独立工作目录 / Git worktree
在 loopat 里,一个 Loop 可以从聊天线程创建,也可以围绕某个代码任务创建。它不是"问 AI 一个问题",而是把当前任务相关的上下文、文件、终端、记忆都绑在一起。
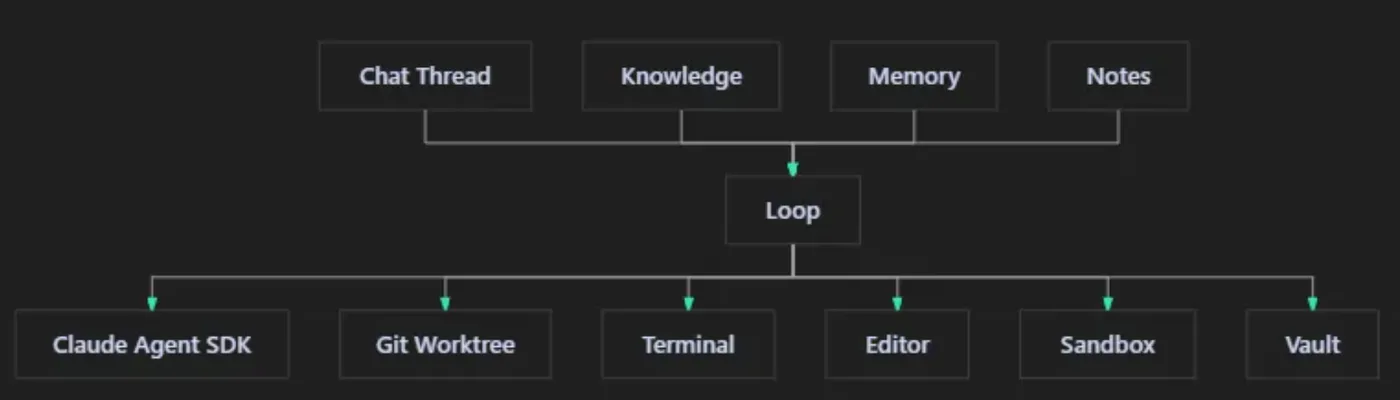
我觉得这一步挺关键。很多工具把 Agent 当作"聪明终端",loopat 把 Agent 当作"工作现场里的参与者"。
三、Context:Knowledge + Notes + Memory
官网里有个明确说法:
Context = Knowledge + Notes + Memory
这三个词听着像一回事,但我理解下来差别很大。
Knowledge:团队认可的知识
比如项目架构、服务依赖、常见坑、部署流程。它应该稳定、可 review、可共享。
Notes:过程中的观察
比如这次排查发现了一个疑点,或者某个方案试了一半暂时放弃。它不一定能进正式知识库,但下次接手的人应该看到。
Memory:个体或团队的偏好
比如"这个项目默认用 pnpm"、"线上日志入口在 Loki"、"某服务别直接重启,先 drain"。它更像经验提示。
普通 AI 工具经常把这三类东西混在一起,最后 memory 变垃圾桶。loopat 至少在概念上把它们拆开了。
四、Git worktree:让每个 Loop 有自己的战场
README 里有个点很重要:一个 Loop 可以对应一个 Git worktree。
这意味着它不是在你的主工作区里乱改,而是给任务开一个独立战场。
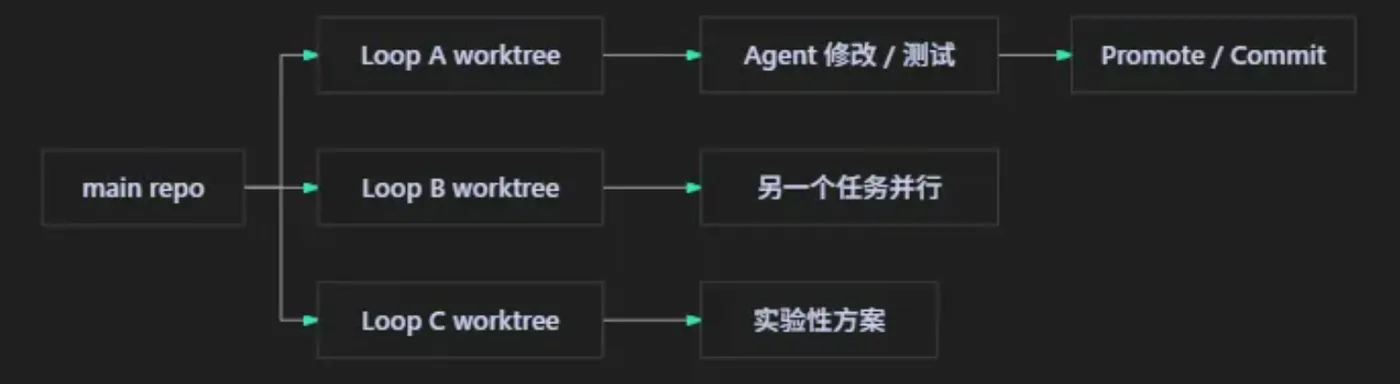
我喜欢这个设计,因为它解决了 Agent 开发里一个很烦的问题:AI 改到一半,你不确定现场还能不能回去。
worktree 把每个 Loop 的变更边界划清楚。成功就 promote,失败就扔掉。很土,但很有效。
五、Sandbox:Agent 不能默认拿全权限
loopat 默认提到 bubblewrap / bwrap,Docker sandbox 也在规划里。Docker 运行还需要 --privileged、SYS_ADMIN 这类权限,这说明它真在做 mount namespace 级别的隔离。
这块我挺看重。
Agent 不是普通脚本。它会读文件、跑命令、调用工具、改代码。如果你直接把宿主机环境变量和文件系统全给它,迟早出事。
loopat 的思路是:
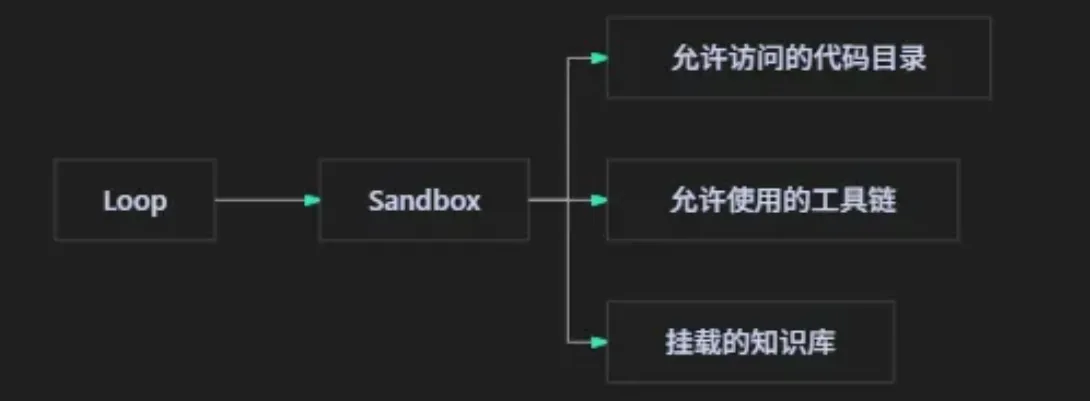
这不是完美安全模型,但比"Agent 直接跑在我电脑上"强一大截。
六、Vault:凭据也要按 Loop 隔离
loopat 还强调 credential vault,并提到 git-crypt。
这个设计很现实。团队里最容易乱的不是代码权限,而是 API Key、部署 Key、云账号 token。
如果所有 Agent 都读同一套环境变量,会出现两个问题:
- 权限过大。一个只该读日志的任务拿到了生产写权限。
- 难审计。出了问题不知道是哪次 Loop 用了哪个 key。
loopat 的方向是:每个 Loop 可以绑定自己的 vault overlay。也就是说,任务需要什么凭据,就挂什么凭据。
我不会说它已经把企业权限治理做完了,但这个抽象是对的。
七、Chat:不是聊天窗口,是上下文入口
第一篇提到过,loopat 把团队聊天线程当一等上下文来源。
我继续拆一下这件事。
多数 AI 工具里,Chat 是输出界面;在 loopat 里,Chat 更像任务入口。
一个线程里通常包含:
- 为什么做这件事
- 谁提的需求
- 已经讨论过哪些方案
- 哪些约束不能碰
- 哪个链接是证据
这些东西本来就是上下文。如果还要人手动复制给 Agent,就说明工具没真正进入协作流。
loopat 从 chat spawn Loop,本质是把"讨论"升级成"执行现场"。
八、它的架构代价
这套架构不是免费的。
第一,复杂度上来了。普通 Agent 工具只要管模型和文件,loopat 要管 chat、git、sandbox、vault、memory、knowledge。
第二,安装门槛上来了。Bun、bubblewrap、mise、podman、Docker,这些词一出现,Windows 用户和非工程团队基本会劝退。
第三,治理成本上来了。谁能创建 Loop?谁能 promote 到共享知识?vault 谁审批?memory 写错了谁清理?这些都要制度配合。
所以 loopat 不适合"我想快速试试 AI 编程"的人。它适合已经把 AI 用进团队流程、开始被上下文和权限问题折磨的人。
九、我会抄哪些设计
如果不直接用 loopat,我也会抄三件事。
1. Loop 这个边界
以后我自己的 Agent 任务都应该有一个明确的工作单元:输入、上下文、工作目录、输出、沉淀物,不能只是一次对话。
2. Knowledge / Notes / Memory 分层
不要把所有东西都塞进 memory。稳定知识、过程观察、偏好提示必须分开。
3. Sandbox + Vault 默认存在
Agent 只要能执行命令,就必须有权限边界。不要等出事才补。
十、总结评价
loopat 的架构野心不小。它想做的不是一个 Agent UI,而是一个 AI 协作操作系统的雏形。
这话听着大,但从它的设计能看出来:Loop 是进程,Context 是文件系统,Sandbox 是权限边界,Vault 是凭据管理,Chat 是调度入口,Knowledge 是长期存储。
当然,它现在还早。文档、生态、部署体验都没有到"闭眼上"的程度。
但我喜欢这种方向:别再把 Agent 当聊天框,应该把它放进一个可复现、可审计、可沉淀的工作现场。
这就是 loopat 架构给我的最大启发。
上一篇:[01|我蹲了一下 loopat:它不是又一个 Agent,而是把上下文当成工作区来管](
下一篇:[03|如果把 loopat 放进团队:我会怎么设计协作规则]

