

一、起因:我那个 SRE agent,跑一晚上烧了我三百块
先说我为啥盯上这个项目。
我手上有个内部用的小玩意儿——一个跑在告警平台上的 SRE 排查 agent。逻辑很糙:告警进来,它去捞最近五分钟的日志,再去查几个相关服务的指标,再调一下 trace,然后让 Claude 给出"大概是哪儿炸了"的判断。
听起来挺优雅,对吧?跑起来才发现,最大的成本不在思考,在喂料。一次排查动不动就把六七万 token 塞进去,里面 80% 是日志,重复的 stack trace 一糊一大片,JSON 里同一个字段在不同对象里出现一千次。Claude 看完每次都很有耐心地告诉我:"根据日志显示,xxxx 服务出现了 OOM"——废话,我知道是 OOM,我想知道为什么 OOM。
那一周对账,光这一个 agent 烧了我三百多。我老板没说啥,我自己心里慌。
正好那两天 GitHub Trending 上 chopratejas/headroom 蹭蹭涨星,README 里直接挂着一行字:
"Up to 80% token savings. Open-source, runs locally."
就这一行,我就去翻了它的代码。
二、它到底是个啥?一句话讲明白
很多上下文压缩的方案是"让模型自己总结一下历史",听起来挺聪明,实际上你得多调一次 LLM,省了输入又花了输出,还可能把关键信息总结没。
Headroom 的思路完全是另一套——它根本不让 LLM 来干这个活。
它在 agent 和 LLM 之间插一个本地压缩层,这层会:
- 看一眼内容是啥——是 JSON、是源码、是日志、还是普通文本?
- 路给对应的压缩器——JSON 走 SmartCrusher,源码走 AST 压缩,文本走它自己训的小模型。
- 该删的删、该折叠的折叠、该去重的去重,原文本地留底。
- LLM 看到的是瘦身版,但如果它真的需要某个细节,它可以反向调一个工具把原文捞回来(这点是这个项目里我最欣赏的设计,下面会单独讲)。
我画了张架构图凑合看一下:
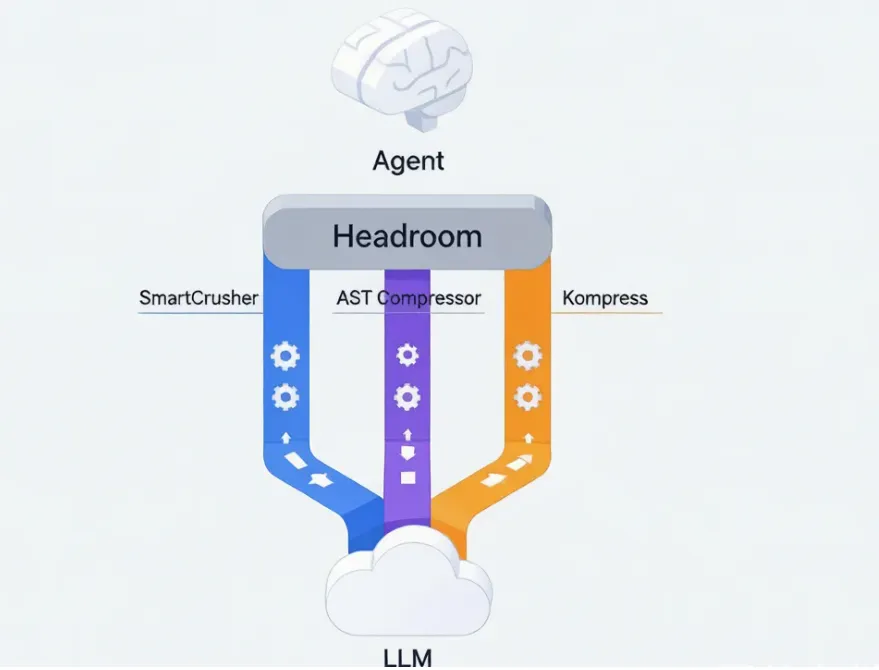
整个流程跑在本地,数据不出你的机器,对那种合规要求苛刻的场景挺友好。
三、四种接法,怎么舒服怎么来
这是它最讨我喜欢的地方——不强迫你改代码。
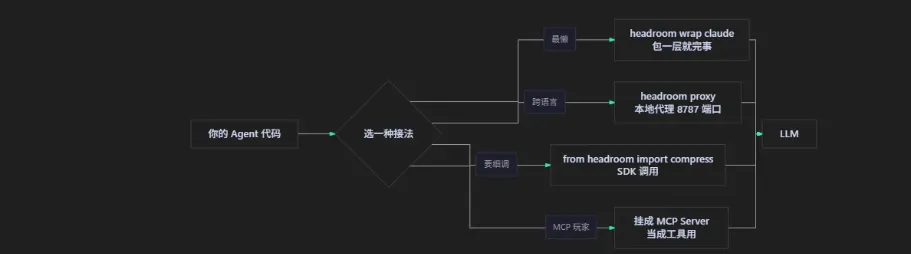
我把这四种用法挨个看了一遍,结合我那个 SRE agent 的形态,最后选了 proxy 模式——因为我那玩意儿是 Go 写的,懒得动它。
1. Wrap 模式:一行命令,最适合 Claude Code / Cursor 这种 CLI
headroom wrap claude
headroom wrap cursor
headroom wrap aider
headroom wrap copilot
包完之后你正常用 Claude Code,它背后的所有上下文都会先过一遍 Headroom。你完全无感。这是写 README 的人在炫技:他知道大部分用户根本不想学新东西。
2. Proxy 模式:开个端口,谁都能接
headroom proxy --port 8787
然后把你 agent 里 OPENAI_BASE_URL 或者 ANTHROPIC_BASE_URL 改成 http://localhost:8787,齐活。Go、Rust、Java、PHP,不挑语言。
3. Library 模式:要嵌进自己的逻辑里
from headroom import compress
compressed = compress(messages, model="claude-sonnet-4-5")
或者更优雅地用它的 SDK Wrapper,连 compress 都不用自己调:
from headroom import withHeadroom
from anthropic import Anthropic
client = withHeadroom(Anthropic())
# 之后所有 client.messages.create 都自动压
4. MCP Server 模式
挂成 MCP,让其他支持 MCP 的客户端把它当成"压缩工具"调用,适合多 agent 系统里做共享中间件。
四、它具体怎么压的?拆开看不复杂
我比较好奇的是:到底是怎么做到 92% 还不掉精度的?
翻了一圈代码和它附的几篇 paper 引用,大致是这么三层活:
第一层:ContentRouter——内容分诊台
这块是它的灵魂。任何一段输入进来,先做一次"这是啥"的判定:
| 内容类型 | 路由去向 | 典型场景 |
|---|---|---|
| JSON 数组 / 对象 | SmartCrusher |
tool 返回值、API response |
| 源代码 | CodeCompressor(AST 感知) |
代码库探索、补全上下文 |
| 日志、纯文本 | Kompress-base(自训小模型) |
日志、文档、RAG 片段 |
| 历史对话 | HistoryCompressor |
多轮对话回看 |
判错了怎么办?它内部有打分机制,评估压缩前后的语义保留度,过低就退回原文。这个 fallback 我觉得比那些"一压到底"的方案靠谱多了。
第二层:六个专用压缩器
- SmartCrusher:JSON 专用。识别结构、合并重复字段、把数组同构对象列成"列式"格式。我那个 SRE agent 调监控接口拿到的指标 JSON,最直接受益。
- CodeCompressor:基于 AST,支持 Python / JS / Go / Rust / Java / C++。能区分函数体和注释、签名和实现,根据当前问题决定保留哪一层。
- Kompress-base:作者自己在 HuggingFace 上训的一个小模型,专门干文本压缩。这个我没去复现训练,但人家放了模型权重,可信度比"我们用 GPT 总结一下"高得多。
- LogCompressor:日志去重和模板提取,把"用户 X 登录失败"这种重复行折叠成一行加计数。
- HistoryCompressor:对话历史专用。
- 基础降重 / 截断器:兜底用。
第三层:CCR(Reversible Compression)——可逆压缩
这是它真正让我决定要在生产用的原因。
普通压缩工具压完就压完了,丢了的细节再也回不来。Headroom 不一样:原文留在本地,压缩版的内容里会带一个引用句柄,比如 [ref: log_chunk_a3f]。LLM 在推理过程中如果觉得"这块好像有信息我需要看",它可以主动调一个 headroom_retrieve 工具,把原文展开。
这就让"压缩"这件事从"破坏性操作"变成了"惰性加载"。我看到这个设计的瞬间,就知道这哥们做过生产系统——只有在生产里被坑过,才会提前把后悔药备好。
第四层(彩蛋):CacheAligner
这块比较细。Anthropic / OpenAI 都有 prompt cache,缓存命中价格能差几倍。Headroom 在压缩的时候会刻意保持前缀稳定,让缓存更容易命中。压缩 + 缓存命中双 buff,账单上的反应就更明显了。
五、官方实测 + 我的"演练"
光看 README 数字没意思,我把它的官方 benchmark 拉出来对比,再结合我那个 SRE agent 的实际形态,估了一下我能省多少。
官方公开的实测数据
| 工作负载 | 压缩前 Token | 压缩后 Token | 节省 |
|---|---|---|---|
| 代码搜索(100 条结果) | 17,765 | 1,408 | 92% |
| SRE 故障排查 | 65,694 | 5,118 | 92% |
| GitHub Issue 分类 | 54,174 | 14,761 | 73% |
| 代码库探索 | 78,502 | 41,254 | 47% |
而且作者很有职业道德,把"压缩之后会不会变蠢"也单独跑了 benchmark:
| 评测集 | 压缩前 | 压缩后 | 备注 |
|---|---|---|---|
| GSM8K(数学推理) | 87% | 87% | 完全一致 |
| TruthfulQA(事实问答) | 53% | 56% | 反而涨了 3 分 |
| SQuAD v2(阅读理解) | 97% | 97% | 同时压了 19% |
| BFCL(工具调用) | 97% | 97% | 同时压了 32% |
注意 TruthfulQA 那一行——压完反而变准了。我猜测原因是噪声本来就在干扰模型,把噪声去掉模型反而清醒。这个观察跟我自己平时调 prompt 的经验是吻合的:很多时候不是上下文不够,是上下文太脏。
套到我那个 SRE agent 上
我那个 agent 的输入大致是:
- 30% 日志(重复严重)
- 25% 监控指标 JSON(重复严重)
- 20% trace 信息(半结构化)
- 15% 历史告警上下文
- 10% 系统 prompt + 用户输入
按 Headroom 各类压缩器的官方平均压缩比往这个分布上一套,估出来的总节省大概是 80% 左右。换算回我之前一晚上三百块的账单,理论上能压到 六十块。
我自己估完都觉得有点夸张,所以专门去翻了它 issue 区有没有人吐槽"实际没那么神"——翻了大概三十条 issue,主要的负面反馈集中在两类:
- 第一次冷启动有点慢:Kompress-base 模型加载需要十几秒。这个能理解。
- AST 压缩对小众语言(比如 Elixir、Haskell)支持不到位:会退化成普通文本压缩。也合理。
没有看到"压完答错了"这种致命吐槽。这个口碑在 5k+ star 的新项目里算很干净的。
六、上手成本和踩坑预判
如果你想接进自己项目,我把会卡住人的几个点提前列出来:
装它
# Python(推荐,特性最全)
pip install "headroom-ai[all]"
# Node.js
npm install headroom-ai
# Docker(生产推荐)
docker pull ghcr.io/chopratejas/headroom:latest
[all] 会把所有子模块一起装,包括 proxy / mcp / ml / code / memory。如果你只用 proxy,可以装 [proxy] 减小体积。Python 要 3.10+,老版本会报奇怪的类型错误。
配 LLM 厂商
它的 proxy 默认朝 Anthropic 转。如果你用的是 OpenAI 兼容的端点(包括国内一堆代理),需要在配置里指明 upstream,否则启动会卡住没报错。这个我看 issue 区有人翻过车。
CCR(可逆压缩)的工具注册
如果你想让 LLM 用 headroom_retrieve 反查原文,得在你的 agent 工具列表里把这个工具暴露出去。Wrap 模式自动帮你做了,proxy 模式需要你自己注册。这点 README 写得不算清楚,要看 docs 才能搞明白。
跨 agent 共享记忆
from headroom import SharedContext
ctx = SharedContext()
ctx.put("这个项目的数据库连接串是 xxx")
# 在另一个 agent 里
db_url = ctx.get("数据库连接串") # 自动去重、自动关联
这个我蹲了一下,本质是用本地 SQLite 当 KV,再做嵌入检索。简洁,没炫技,但对多 agent 协作场景很实用。
Headroom Learn——它会自己学
headroom learn --agent claude --source ./sessions/
把过去的对话扔进去,它会找出 agent 频繁犯的错,写进 CLAUDE.md / AGENTS.md,下次自动加载。这功能介于"花活"和"实用"之间,我个人会先观察两周再决定要不要用。
七、它适合谁?不适合谁?
这部分我必须说人话。
适合的场景
- agent 输入里有大量重复 / 结构化噪声:日志多、JSON 多、tool output 长,提升立竿见影。
- 多轮对话堆很长的:HistoryCompressor 是亲妈。
- 生产环境怕信息丢:CCR 让你能放心用,丢不了关键信息。
- 多 agent 系统:proxy + SharedContext,统一压、统一记。
- 预算敏感的中小团队:你账单减 60%,老板看见报表会笑。
不适合的场景
- 输入本身就很短:每次 1k token 以内的,加压缩层反而引入额外延迟(虽然不多,但有)。
- 你的内容主要是非英文非中文的小语种:Kompress-base 主要在英文上训,中文够用,但小语种可能拉胯。
- 极致追求延迟(毫秒级 SLA):路由 + 压缩有几十毫秒开销,对话场景无感,但如果你做的是实时语音那种就别加了。
- 你的 agent 本来就用了厂商的官方 prompt cache 且做得很到位:收益会被吃掉一部分,得自己评估。
八、总结评价:这是 2026 年我目前看到最"有工程师味儿"的 agent 周边
我看 GitHub 项目的口味比较挑,喜欢那种"作者明显被坑过、知道自己在解什么"的项目。Headroom 完全是这类。
它身上有几个非常成熟的判断:
- 不让 LLM 干压缩——成本和不确定性双双省下来。
- 按内容类型分诊——而不是一刀切。
- 可逆——CCR 的设计是对生产环境的尊重。
- 多种接入——wrap / proxy / library / MCP,作者懂用户懒。
- 前缀稳定——主动迎合 prompt cache,是只有真做过推理优化的人才会想到的细节。
要说不足,我也老实讲:
- 文档分散:README + docs site + 几篇 paper 引用,新手摸索成本中等偏上。
- 小语种 / 小众文件类型支持有限:现阶段是英文 + 主流编程语言为主。
- 生态还在长:MCP 模式、Learn 模式都偏新,可能会改 API。
- 作者背景偏 Netflix 工程口味:你能感觉到它特别擅长高并发、长文本场景;轻量场景可能"杀鸡用牛刀"。
但综合起来,我会推荐任何在生产里跑 agent 的团队都至少试一下 proxy 模式——零代码改动、零风险、跑一周拉账单看效果,这种买卖太划算了。

