

上一期:[这周我蹲了一下 Headroom,它真把我那个烧钱的 Agent 给救回来了]
这期主角:headroom-core/src/transforms/smart_crusher/这个目录
一句话剧透:传统 zstd 那套是在跟"重复字符串"较劲,SmartCrusher 是在跟"哪些数据 LLM 根本不需要看"较劲——完全两个层面的事儿。
一、起因:上一期文章评论区那个犀利问题
上一期写完 Headroom,评论区有个老哥问得很狠:
"JSON 压缩听着挺玄乎,跟我用 gzip / zstd 压一遍再解开喂给 LLM,本质区别是啥?"
我当时回得有点虚,只敢说"它做的是语义层面的事"。这话不算错,但也算不上能说服人。所以这一期我决定钻进去,专门看看它那个名字最唬人的压缩器——SmartCrusher。
我的目标其实就一句话:搞清楚它到底在干啥,跟传统压缩算法到底差在哪儿,差得有没有道理。
翻完源码我可以负责任地说:差得很有道理,而且这种思路对所有做 agent 的人都有借鉴意义。
二、上来就泼一盆冷水:网上一半的拆解都瞎写
去搜 SmartCrusher 之前先打个预防针。我至少看到两种"广为流传"的拆解:
- A 版本:说它是"schema 抽取 + 常量折叠 + 行→列式重排"的无损结构压缩。
- B 版本:说它核心是 Kneedle 肘点检测算法,加 2σ 异常值保护、BM25 中间项打分。
A 版本只对了一小半,B 版本基本是脑补出来的。我直接去对了一下源码模块清单(crates/headroom-core/src/transforms/smart_crusher/ 这个目录下的文件),关键证据:
- 源码里根本没有
kneedle、knee_point、elbow任何相关的字符。 - 也没有
constant_fold这种显式模块。 - 真正存在的核心模块是:
crusher.rs(主流程)、analyzer.rs(统计推断)、planning.rs(策略规划)、compaction/walker.rs(递归遍历)、constraints.rs(保留约束)、hashing.rs(CCR 哈希)、outliers.rs(离群检测)。
所以这一期我只讲源码里真有的东西。后面的所有结论都能对到具体文件名甚至行号。
三、它的核心姿势:Lossless-First
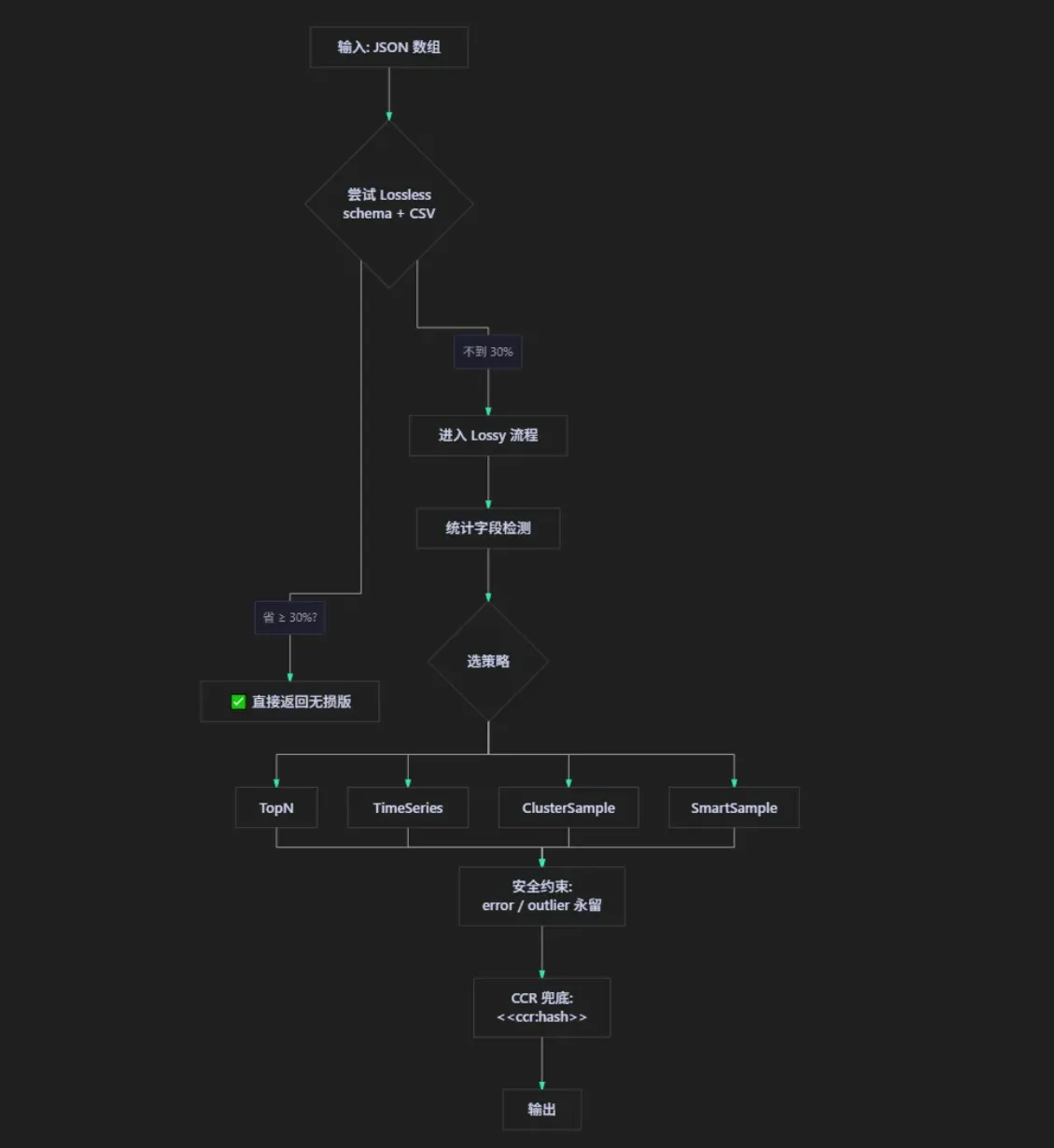
先说我读完源码后觉得最妙的一招——Lossless-First 策略,写在 crusher.rs:140-154。
人话翻译:它压一段 JSON,永远先尝试无损路径。如果无损就能省下至少 30%(这个阈值是 config.rs 里的 lossless_min_savings_ratio,默认 0.30),它就直接返回,根本不进有损流程。
为什么这招重要?因为做压缩这行最容易翻车的瞬间,就是"我以为这数据可以丢一点,结果丢的恰好是关键的那一行"。Lossless-First 的潜台词是:
"能不动语义就别动语义。语义都动不了的时候,我才考虑把哪些行抠掉。"
这种态度跟 zstd 那种"管他啥内容,先按字典编码哈希一遍"的暴力路线,气质上完全不一样。zstd 不关心你压的是日志还是诗,它就盯着重复子串。SmartCrusher 上来先问一句"我能不能不删?"
整个流程下来,原始数据没有任何一行被永久销毁——丢掉的部分都进了本地的 CcrStore,LLM 想看可以随时调 headroom_retrieve 拉回来。这就是上一期我提到的"可逆"在这一层的具体落地。
四、Lossless 这一支:是的,它确实会做 schema 抽取
无损这一支走的就是大家直觉里那套"列式表达"。
举个例子,工具调用返回这种典型形态:
[
{
"file": "/src/utils/helper.js", "line": 42, "type": "function", "status": "ok"},
{
"file": "/src/utils/logger.js", "line": 15, "type": "class", "status": "ok"},
{
"file": "/src/utils/timer.js", "line": 88, "type": "function", "status": "ok"}
// ... 再来 97 条结构一致的
]
这玩意儿喂 LLM,光那 100 个 "file"、100 个 "line"、100 个 "type"、100 个 "status" 就把 token 烧没了。Lossless 这一支会改写成 schema + 数据的形态,从 compaction/mod.rs 的注释能看到它叫 "dense CSV+Schema format"——字段名只出现一次,剩下全是数据行。
这一步严格说不是"压缩",更像是把 JSON 用更省 token 的方式写出来。语义没变,LLM 的理解也没变(事实上它对 LLM 更友好,因为重复键名对 LLM 也是噪声)。
但 SmartCrusher 真正区别于"换个序列化格式"的关键在下面——它会判断这次到底值不值得这么干。如果你这数组就 5 条记录,schema 抽取省下来的开销还不够 schema 本身的 token,那就别折腾,老老实实用原 JSON。这就是 0.30 阈值的意义。
顺便说一句,最近社区有个挺火的 TOON 格式(一种为 LLM 设计的紧凑序列化)也在做类似的事,但 TOON 是"格式层"的事,SmartCrusher 是"决策层 + 格式层"——它会判断要不要做格式压缩,并且只是它整个管线的第一步。这两者其实可以叠着用。
五、Lossy 这一支:才是这个项目真正的脑子
无损这一支不行了——比如数组太大、内容太散、schema 都对不齐——这时候 SmartCrusher 才掏出真家伙。
第一刀:统计字段检测,不靠字段名
这是我读完最佩服的一段,在 analyzer.rs:59-128 和 field_detect.rs 里。
绝大多数 JSON 处理库识别字段都靠字段名——看到 id 就当主键,看到 timestamp 就当时间戳。问题是 agent 拿到的 JSON 来自天南海北的工具,字段名千奇百怪:id / uid / userId / user_id / entity_ref,到了某些破系统里甚至叫 f1、f2。
SmartCrusher 不玩这套硬编码,源码注释里写得很直白:
analyzer.rs:1-18: "avoids hardcoded field name patterns. It uses statistical analysis to infer field semantics"
它怎么判断一个字段的语义?看分布:
| 检测目标 | 判断依据 |
|---|---|
detect_id_field_statistically |
唯一值比例 > 0.9,且匹配 UUID 模式或递增整数序列 |
detect_score_field_statistically |
数值有界(0-1 / 0-100),且常被排序 |
detect_temporal_field |
值是结构化日期/时间戳(完全不看字段名) |
detect_error_items_for_preservation |
值或键里命中 error_keywords.rs 那张关键词表 |
detect_structural_outliers |
偏离均值 >2σ,或属于罕见 schema |
这就是真正"工程师写出来的代码"——它知道现实世界的字段名根本不可信,所以直接看数据本身长啥样。这个思路其实跟数据库优化器估行数(cardinality estimation)是一脉相承的,老技术活在新场景里。
第二刀:四种策略,按数据形态选
走完字段检测,planning.rs 会根据检测结果挑一个策略:
| 策略 | 触发条件 | 思路 |
|---|---|---|
| TopN | 检测到 score 字段 | 按分数排序,留头部 N 条 |
| TimeSeries | 检测到时间字段 | 按时间排序,保留变点(mean shifts) + 边界 |
| ClusterSample | 高冗余 | 按内容相似度聚类,每簇取代表 |
| SmartSample | 都不沾,兜底 | compute_k_split:保留首尾 k 条 + 离群点 |
我专门停下来想了一下 TimeSeries 这条——为什么要保留变点而不是均匀采样?因为 LLM 在做诊断类任务时,最关心的就是"什么时候开始变了"。一段平稳的 CPU 占用 + 一个突起,删掉平稳那段没事,但那个突起必须留下。这跟我们做监控告警的本能完全一样。

注意:这里的"变点检测"是经典的 mean shift / outlier σ 阈值方法,不是某些拆解文里说的 Kneedle 肘点法。我去 grep 了源码,没有任何 kneedle 相关字符。这个细节我特意拎出来说,是因为如果你之后想给团队 PR 类似的算法,方向对了再写代码事半功倍。
第三刀:两条硬约束,不能逾越
不管选了哪种策略,constraints.rs 里有两条硬规矩:
KeepErrorsConstraint:只要这一项命中了error_keywords.rs里的关键词(fail / error / exception / timeout 这一票),它就永远不能被丢。KeepStructuralOutliersConstraint:只要这一项的 schema 跟主流不一样,它永远不能被丢。
这俩约束特别值得说道。第一条对应的是"诊断类任务里,错误日志是金子";第二条对应的是"奇怪的数据结构往往就是问题所在"。两个加起来,基本把"压完丢了关键信息"这个最大的风险堵死了。
我读到这里的时候笑了一下——这就是被生产坑过的人才会写的代码。新手压缩库不会优先想这种事。
六、CCR 兜底:那些被"丢"掉的,其实没真丢
到这一步如果还压不下来,进入最后一道工序——CCR(Compressed Context Reference)。
crusher.rs:86-95 里给出的标记格式:
<<ccr:abc123def456 42_rows_offloaded>>
这串东西会直接塞进给 LLM 的上下文里,替换掉那 42 行被卸载的数据。哈希前 12 位是 SHA-256 截取,原始数据则放进本地的 CcrStore。
LLM 看到这个标记,如果它觉得"嗯这块我得看看",可以主动调 headroom_retrieve 工具:
# LLM 实际发起的调用
headroom_retrieve("abc123def456")
# 返回那 42 行原始内容
这是上一期我吹爆的"可逆压缩"在这一层的具体形态。从这个标记的设计你能看出几个细节:
- 12 位哈希足够避免碰撞,但又比 64 位短得多——典型的工程取舍。
- 后面带
42_rows_offloaded,这是给 LLM 看的元信息,让它知道"这里被省略了 42 行,要不要展开自己决定"。这个细节非常贴心。 - 整个机制是惰性的——LLM 不查就不查,省了就是赚了;要查随时可以查,不会丢。

七、跟 zstd 比一比,到底差在哪?
回到开头那个评论区问题。我现在能给出一个比较硬的答案了:
| 维度 | zstd / gzip 之类 | SmartCrusher |
|---|---|---|
| 工作层面 | 字节序列 | JSON 语义 |
| 关心什么 | 重复子串、字典命中 | 字段含义、错误信号、变点 |
| 是否减少给 LLM 的信息量 | ❌ 完全不减少(解压后等价于原文) | ✅ 减少(lossy 时真的少了行数) |
| LLM 能不能直接读 | ❌ 必须先解压 | ✅ 输出仍是合法 JSON / 标记 |
| 能不能利用 prompt cache | ❌ 解压后字节几乎一致,但不会主动稳定前缀 | ✅ 主动维持前缀稳定 |
| 风险点 | 不会丢信息 | 可能丢非关键信息(被 Constraints + CCR 兜住) |
核心区别一句话:zstd 是减少字节,让传输便宜;SmartCrusher 是减少LLM 要读的内容,让推理便宜。
这俩根本不是同一个赛道。你完全可以在 SmartCrusher 输出之后再套一层 zstd 传输——但反过来不行,把 zstd 解压完的 JSON 喂给 LLM,token 一个都没省下来。
八、几个值得我们抄走的设计思想
读完这块代码,我自己有几条收获,可以直接搬到自己写 agent 中间件时用:
1. 永远先尝试无损
不要一上来就丢数据。先做无损改写(schema 抽取、字段名压缩、空白去除),看够不够。够就别再删。这条对所有压缩 / 总结类的中间件都成立。
2. 别相信字段名,相信数据分布
agent 接的工具五花八门,字段名根本指望不上。哪个字段是 ID、哪个是时间、哪个是分数——用统计判比硬编码靠谱十倍。
3. 错误条目和离群点必须有保护
诊断类、运维类、调试类任务里,这两类数据是金子。任何一个压缩器都该把它们列入"白名单",不能算入压缩对象。
4. 保留变点 > 均匀采样
时序数据上,均匀采样会把异常点抹平掉。识别变点(哪怕用最朴素的 mean shift)然后保留它,效果会好得多。
5. 可逆永远比"丢了再说"好
留个本地副本 + 一个 retrieve 工具,让 LLM 主动决定要不要看细节。这种设计的好处是犯错的代价从"答错"降到"多调一次工具",质量底线被锁死了。
九、缺点和槽点:必须老实讲
读到尾声我也发现几处不太爽的地方:
- 配置项有点多但默认值不够透明。
lossless_min_savings_ratio= 0.30 是凭啥拍板的?源码里没看到 benchmark 注释。我猜是经验值,但作为工程库,这种地方放个一句话理由会更好。 - 聚类策略
ClusterSample的相似度算法没有公开说明。从代码引用看是基于 schema + 内容指纹,但没有具体公式。这块对中文场景的鲁棒性我心里没谱。 - CCR 哈希前 12 位——理论上 12 位 SHA-256 的碰撞概率在大量条目下非零。如果你单次压缩规模到了百万行级别,可能要考虑碰撞兜底。当前代码里我没看到显式处理。
- 统计字段检测的样本下限没看清。如果数组只有 3 条,统计推断本身就不可信。这块要么我读漏了,要么作者后续会补。
这些不是大问题,但拿来做 PR 的话都是好切入点。
十、总结:从工具变成范式
把 SmartCrusher 拆完,我对 Headroom 的看法又升了半档。
我以前以为它就是个"省 token 的中间件",现在看下来,它其实是在告诉所有做 agent 工程的人:
"Agent 时代的压缩,不是字节级压缩,是语义级筛选。"
zstd 之于网络传输,是把比特尽量塞紧;SmartCrusher 之于 LLM 推理,是把"模型不需要看的东西"提前过滤掉,但保留召回路径(CCR)。这套思路一旦你接受了,会发现它能用的地方远不止 JSON:
- 代码上下文:我们做代码 agent 的,是不是也能"先尝试结构化提取,不行再做 lossy + 可逆"?
- 对话历史:哪些轮次是关键决策点(变点)?哪些是"嗯嗯好的"这种废话?
- RAG 检索结果:是不是也该按"错误关键词 / 离群 schema"做硬保留?
我已经在琢磨怎么把这套思路抄进我自己那个 SRE agent 里了。下一期就讲这个:用 SmartCrusher 的思路,给一个具体的中间件做语义层压缩——不直接抄它的代码,但抄它的脑子。
下一期预告:把 SmartCrusher 的设计思想搬进一个 SRE agent 的工具调用中间件,看看不抄代码只抄思路,能不能也压出 80% 来。

