

过去一周,开发者圈里有一个仓库涨得很凶:Addy Osmani 的 addyosmani/agent-skills。
按公开 Star History 页面显示,这个项目近期总星标已到 56.7k+,GitHub 仓库页面在我查阅时约 56.9k stars、6.1k forks。网上流传的口径是“本周新增约 15,000 stars,日增约 2.6k”;这个增长速度很夸张,但更值得关注的不是数字,而是它代表的一个变化:AI 编码工具正在从“补全代码片段”,转向“带着工程规范、检查清单和执行流程来协作”。
agent-skills 的作者是 Addy Osmani,Google Chrome 团队的工程负责人之一,长期写性能、前端工程和 AI 辅助开发相关内容。这个仓库的定位很直接:把生产级工程经验封装成一组可被 AI Coding Agent 调用的技能,让 Claude Code、Cursor、Copilot、Gemini CLI 等工具在做代码审查、调试、重构、性能优化、安全检查时,不只是泛泛地“帮我看看”,而是按一套明确流程工作。
官方 README 当前列出的技能数量已经从早期传播里的 21 个扩展到 24 个。如果你看到“21 个生产级 AI 编码技能”的说法,它大概率来自稍早版本;这类项目更新很快,发布文章时建议以 GitHub README 为准。
它到底是什么?
agent-skills 不是一个新的 IDE,也不是一个模型。它更像是给 AI 编码助手准备的一套“工程作业指导书”。
每个技能通常由一个 SKILL.md 文件描述,里面会告诉 AI:
- 什么时候应该使用这个技能。
- 需要先收集哪些上下文。
- 应该按什么步骤分析。
- 输出时要包含哪些证据、风险和验证结果。
- 哪些事情不能省略,比如测试、回归风险、性能基线、安全边界。
这听起来像 Prompt 模板,但它比普通 Prompt 更接近“可复用的工作流”。普通 Prompt 往往写成一句“请帮我优化性能”;Skill 会把任务拆成检查点,例如先建立基线,再定位瓶颈,再提出改动,再验证收益,再写出回滚策略。

为什么会突然火?
我认为它踩中了三个真实痛点。
第一,AI 编码工具已经足够会写代码,但经常“不像资深工程师那样做事”。它可能很快给出一个能跑的实现,却漏掉边界条件、回归测试、性能基线、安全影响和迁移成本。agent-skills 试图把这些工程习惯显式写进上下文。
第二,团队真正想要的不是“更会聊天的 AI”,而是“可复制的工程流程”。代码审查、重构、安全检查、性能分析本来就有方法论,把它们写成 Skill 后,同一个团队里的不同人、不同工具可以复用同一套检查标准。
第三,它适配多个主流工具。官方文档提到可以用于 Claude Code、Cursor、GitHub Copilot、Gemini CLI 等环境。也就是说,它不是押注某一家平台,而是把“技能文件”当成跨工具资产。

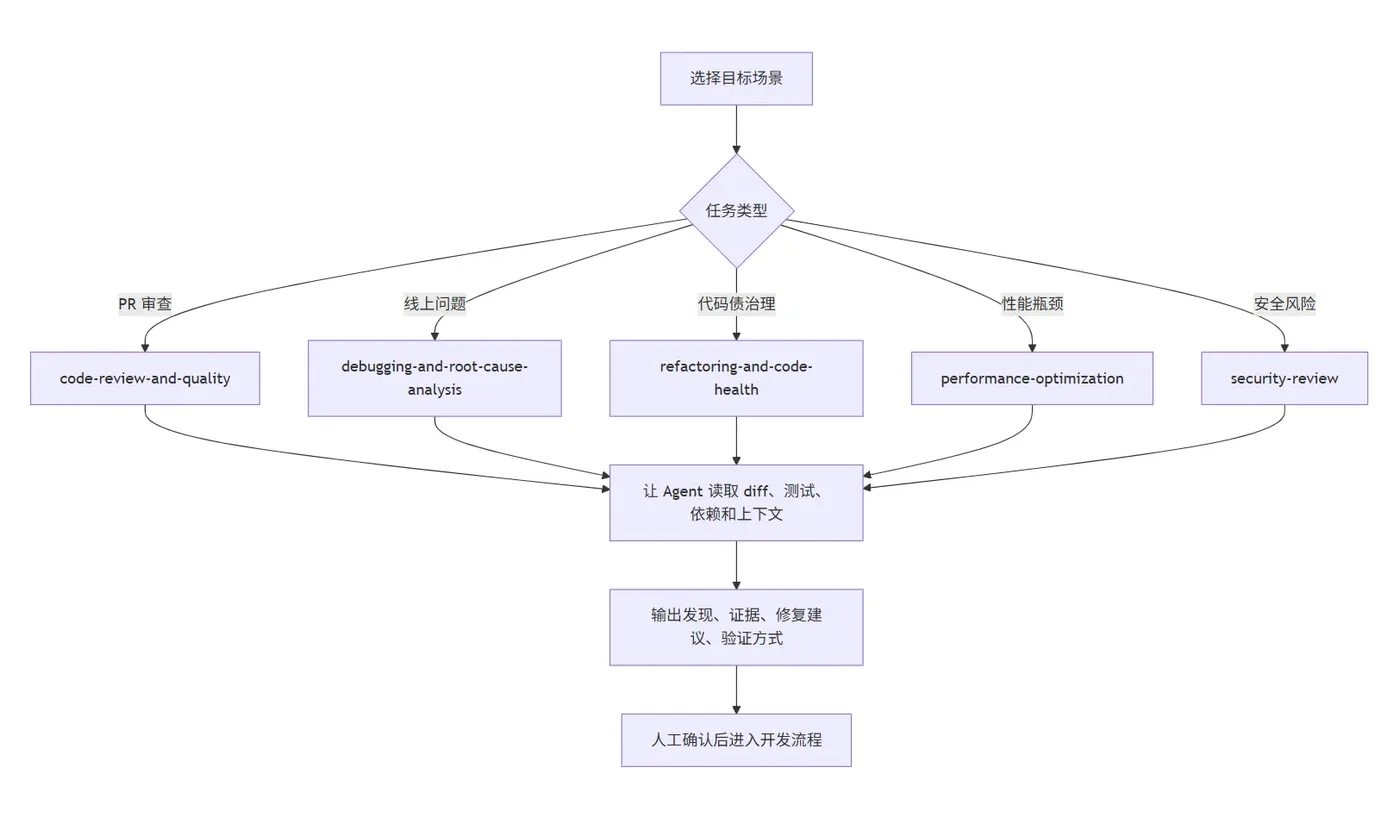
一个典型流程是:
- 从 GitHub 克隆或复制需要的技能目录。
- 按目标工具放到对应位置,例如 Claude Code、Cursor、Copilot 或 Gemini CLI 的技能/规则目录。
- 在 AI 编码工具里明确调用某个技能,例如“用 code-review-and-quality 帮我审查这个 PR”。
- 让 Agent 读取项目上下文,而不是只看单个文件。
- 要求输出包含证据、风险、测试建议和优先级。
- 对 Agent 的建议做人工复核,再合并到团队规范。
实践一:用它做代码审查
官方的 code-review-and-quality 技能不是简单地让 AI “挑毛病”。它强调从正确性、可维护性、测试覆盖、可读性和风险级别等角度输出审查意见。
比较实用的调用方式是:
Use the code-review-and-quality skill to review this pull request.
Focus on correctness, regression risk, missing tests, and maintainability.
Return findings first, with file/line references and severity.
这和成熟团队里的 Review 习惯很接近:不要先夸,不要先总结,先列风险。AI 被这种结构约束后,输出会更像工程审查,而不是泛泛的建议清单。
从公开 Issues 看,用户也在围绕安装、路径、工具兼容性等问题反馈。比如 Release 记录中能看到对 Copilot agent 文件命名、Chrome DevTools MCP 安装配置、marketplace 相对路径安装等问题的修正。这说明它不是“写完就放着”的 Prompt 合集,而是在被真实工具链打磨。
实践二:用它做性能优化
Addy Osmani 本人长期关注 Web Performance,所以 performance-optimization 是这个仓库里最值得看的技能之一。
一个可靠的性能优化流程应该是:
- 先建立性能基线,比如 Lighthouse、Web Vitals、bundle size、接口耗时、渲染耗时。
- 再定位瓶颈,而不是直接改代码。
- 然后提出最小改动。
- 最后用同一指标复测。
可以这样调用:
Use the performance-optimization skill.
Start by identifying the current performance baseline and likely bottlenecks.
Do not propose code changes until you list the evidence and measurement plan.
这句话的关键是“先证据,后改动”。很多 AI 优化建议的问题在于,它们看起来很合理,但没有基线,也没有复测。agent-skills 的价值就在于把“测量”放回流程里。

实践三:用它做安全检查
安全检查类技能的价值在于让 AI 不只搜索 password、token 这类关键词,而是按威胁模型去看:
- 输入是否可信。
- 权限边界是否清楚。
- 敏感数据是否被记录或返回。
- 依赖项是否存在已知风险。
- 错误处理是否泄露内部信息。
- 是否有 SSRF、SQL 注入、XSS、路径穿越等常见攻击面。
适合的调用方式是:
Use the security-review skill.
Build a threat model first, then inspect authentication, authorization,
input validation, secrets handling, logging, and dependency risk.
这类技能尤其适合做“提交前自查”和“高风险模块专项审查”。但要注意,AI 安全审查不能替代 SAST、依赖扫描、渗透测试和人工安全评审,它更适合作为第一轮高覆盖检查。
它和普通 Prompt 最大的不同
普通 Prompt 解决的是“这一次怎么问”。Skill 解决的是“以后这类事都怎么做”。
| 对比项 | 普通 Prompt | agent-skills |
|---|---|---|
| 复用方式 | 靠复制粘贴 | 文件化、目录化、可版本管理 |
| 工程约束 | 容易漏 | 写进技能说明 |
| 团队协作 | 难统一 | 可作为团队规范共享 |
| 工具适配 | 单次对话为主 | 面向 Claude Code、Cursor、Copilot、Gemini CLI 等 |
| 输出质量 | 取决于提问者 | 由流程和检查清单托底 |
如果你是个人开发者,它能帮你把“资深工程师的自检流程”带进日常编码。如果你是团队负责人,它更像一份可落地的 AI Coding 规范模板。
适合谁用?
我认为最适合三类人。
第一类是已经在用 Claude Code、Cursor、Copilot 的开发者。你不需要换工具,只需要把技能文件接入现有工作流,就能明显改善 Agent 的输出结构。
第二类是团队里的 Tech Lead 或架构负责人。你可以把代码审查、性能、安全、重构这些高频流程沉淀成团队技能,减少“每个人问 AI 的方式都不一样”带来的质量波动。
第三类是正在建设 AI 工程平台的团队。agent-skills 展示了一种很轻量的能力组织方式:不用先做复杂平台,先把标准流程文件化、版本化。
局限也很明显
首先,Skill 不是魔法。它不能保证 AI 一定理解复杂业务,也不能替代测试和人工判断。它提高的是工作流质量,而不是把模型变成无错工程师。
其次,跨工具适配会带来细节差异。Claude Code、Cursor、Copilot、Gemini CLI 对“技能”“规则”“上下文”的加载方式不同,落地时要按各自文档配置。公开 Release 里反复修安装路径和 agent 文件命名,也说明这部分仍在快速演进。
第三,团队如果直接照搬全部技能,可能会变成新的噪音。更好的做法是先选 3 到 5 个高频场景:代码审查、调试、性能、安全、重构。跑顺以后,再逐步扩展。
我的评价
agent-skills 的爆火不是偶然。它抓住了 AI 编码下一阶段的核心问题:不是“AI 会不会写代码”,而是“AI 能不能按工程团队认可的流程交付”。
它最有价值的地方不是 24 个技能本身,而是它提供了一种组织 AI 能力的范式:把经验写成文件,把流程放进版本库,把质量要求变成 Agent 每次工作时都能读取的上下文。
如果说 2023 到 2025 年的 AI 编码主题是“生成更多代码”,那么 2026 年更重要的主题可能是“让 AI 生成更可信的工程结果”。agent-skills 正好站在这个转折点上。
我的建议是:不要把它当成一个网红仓库收藏一下就完事。真正值得做的是,选一个你团队最痛的场景,把对应 Skill 接进现有工具,连续用一周,然后观察三个指标:
- Review 是否更聚焦真实风险。
- Debug 是否更快收敛到根因。
- 性能和安全建议是否有证据、有验证、有回滚思路。
如果这三个指标有改善,它就不只是“本周新星”,而是可以进入团队工程体系的一块积木。

