

你有没有这种感觉?刷视频、看新闻,到处都在说"大模型"、"Agent"、"Token"、"MCP"……这些词像潮水一样涌来,但你心里其实有点慌——我连这些词到底什么意思都不知道,是不是要被时代抛下了?
别急。这篇文章用大白话,从零开始,把 AI 时代最核心的 5 个概念讲透。读完,你能在饭桌上、会议室、家庭群里,自信地聊 AI。
楔子:一个真实的场景
小王是个产品经理,不会写代码。某天他用了 ChatGPT,给它说:"帮我做个登记表单的网页。"
5 秒后,ChatGPT 真的给出了一段代码。小王把代码复制到记事本,存成 index.html,双击打开——一个能用的网页出现在浏览器里。
那一刻,小王脑子里炸了:原来不会写代码的人,也能"做"出软件?
但当他兴奋地想做更复杂的功能时,问题来了:
- 为什么有的回答几秒就出,有的要等半天?
- 为什么聊到一半 AI 突然"失忆"了?
- 为什么有的 AI 能直接帮他改文件,有的只会"嘴上说"?
- 群里有人说 "Cursor 的 Agent 功能爆炸好用",这又是啥?
这些问题的答案,藏在今天要讲的 5 个概念里:Token、LLM、Tools、MCP、Agent。
一、Token:AI 眼中的"字",决定了你的钱包
1.1 一个反直觉的事实
请回答:"Hello World" 这句话,对 AI 来说是几个"字"?
- 答案不是 11(字符数)
- 答案也不是 2(单词数)
- 答案是 2 个 Token:
Hello和World(注意 World 前面带空格)
再来一个:"我爱编程"这4个汉字呢?
- 在 GPT 系列模型里,大约是 6-8 个 Token
- 因为中文每个汉字往往要占 2-3 个 Token
这就是 Token 的反直觉之处:它不是字符,也不是单词,而是 AI 模型自己定义的"语言基本单位"。
1.2 用做菜来类比
想象你是一个厨师,但你不认识"蔬菜"、"水果"这些完整的词,你只认识:
- "胡"、"萝卜"、"菠"、"菜"、"苹"、"果"…… 这样的小片段
你做菜时,每次抓食材都是抓一小撮一小撮的。AI 处理语言也一样——它把所有文字打成"碎片",每个碎片就是一个 Token,然后一片一片地处理。
为什么要这样切?因为如果让 AI 记住人类所有的词(中文几十万词、英文上百万词),模型会大到没法用。切成 Token 后,常用片段就那么几万种,AI 才"装得下"。
1.3 Token 怎么影响你?
第一,它决定了你的账单。
OpenAI 的 GPT-4 收费大概是:
- 输入:每 1000 个 Token 约 0.005 美元
- 输出:每 1000 个 Token 约 0.015 美元
听起来不多?我们算笔账:
| 场景 | Token 量 | 费用估算 |
|---|---|---|
| 问一句"今天天气怎么样" | ~10 Token | 几乎为零 |
| 让 AI 写一篇 2000 字文章 | ~5000 Token | 约 0.03 美元(2毛钱) |
| 让 AI 阅读一本 30 万字的小说 | ~600,000 Token | 约 3 美元(22元) |
| 一个客服机器人每天对话 1000 次 | ~10,000,000 Token | 约 50 美元(360元) |
第二,它决定了 AI 的"记忆力"。
每个模型一次能处理的 Token 数有上限,这叫上下文窗口。
- GPT-3.5:16,000 Token(约一万多字)
- GPT-4 Turbo:128,000 Token(约一本中篇小说)
- Claude 3.5:200,000 Token(约两本《三体》第一部)
- Gemini 1.5 Pro:1,000,000 Token(一本完整长篇小说+剧本)
超过这个量,AI 就会"忘记"前面说的话。这就是为什么聊久了 AI 会"失忆",开始前后矛盾。
1.4 一张图看懂 Token

一句话总结:Token 是 AI 的"字",它决定了你花多少钱、AI 能记住多少东西。
1.5 常见误区
❌ 误区1:Token 就是单词。
✅ 真相:英文里一个常见单词通常是 1 个 Token,但生僻词、长词、组合词会被切成多个。
❌ 误区2:中文比英文更省 Token。
✅ 真相:恰恰相反!同样的意思,中文常常比英文多花 30%-50% 的 Token,因为现有的 Tokenizer 是英文友好的。
❌ 误区3:Token 用完了就报错。
✅ 真相:超过上限不会报错,但 AI 会"丢掉"最前面的对话,造成回答前后矛盾。
二、LLM:一个"接话天才"的诞生
2.1 LLM 到底是什么?
LLM 全称 Large Language Model(大语言模型)。它本质上是一个超大型的"猜下一个字"的机器。
听起来很弱?但当这个"猜字"能力强到极致,它就能写小说、写代码、聊哲学、做翻译……
2.2 用培养孩子来类比
想象你养了一个孩子,你想把他培养成全才。你怎么做?
第一步:海量阅读(预训练)
你把人类历史上所有的书、网页、论文、新闻、代码……全部塞给孩子,让他每天就玩一个游戏:
- 你说:"今天天气真" → 他猜:"好"
- 你说:"白日依山" → 他猜:"尽"
- 你说:"def add(a, b): return" → 他猜:"a + b"
- 你说:"Once upon a" → 他猜:"time"
孩子玩这个游戏玩了几万亿次。慢慢地,他不仅学会了语言规律,还学会了:
- 语法(哪些词能搭配)
- 常识(火是热的,冰是冷的)
- 推理(A大于B,B大于C,所以A大于C)
- 代码模式(看到 for 循环知道接下来该写什么)
这就是预训练。它需要几万块顶级显卡,训练几个月,烧掉上亿美元。
第二步:调教礼仪(对齐训练)
光会"接话"还不够。你问他"怎么造原子弹",他可能真的会告诉你,因为书上有。你需要教他什么该说、什么不该说、怎么说才有用。
具体怎么教?请来一群人类标注员,让他们当老师:
- 模型给出 3 个回答,标注员选最好的一个
- 不断重复,模型学会"什么样的回答最受欢迎"
这一步叫 RLHF(人类反馈强化学习)。它让 AI 从"什么都能说"变成"说人话、说有用的话"。
2.3 那段神奇的"涌现"
当模型小的时候(比如几亿参数),它只会做一些简单的接话游戏。但当模型规模突破某个临界点(大约 100 亿参数以上),神奇的事情发生了——它突然学会了一些"没人教过"的能力:
- 你给它一个数学题,它居然能一步步推理
- 你让它用某种风格写文章,它真的能模仿
- 你给它一段没见过的代码,它能猜出在干什么
这种能力被称为"涌现"(Emergence)——量变引发质变。这是 LLM 最神奇、也最让科学家困惑的地方:我们知道它有效,但不完全知道为什么。
2.4 LLM 的工作流程
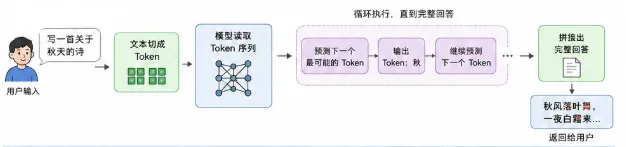
注意:模型每次只生成一个 Token,然后把之前所有内容(包括自己刚生成的)作为新输入,再生成下一个 Token。这就是为什么 ChatGPT 的回答是"一个字一个字蹦出来"的。
2.5 为什么 AI 会"胡说八道"?
这是个高频问题。AI 为什么会一本正经地编造不存在的内容?业界叫这种现象"幻觉"(Hallucination)。
原因很简单:LLM 本质是"猜最可能的下一个字",而不是"查证事实"。
举个例子:你问它"鲁迅和周树人是什么关系?"
模型脑子里转的不是去图书馆查资料,而是在它见过的所有文本里找规律——"鲁迅"和"周树人"这两个词,最常出现在什么样的上下文里?
如果训练数据足够多,它会答对:"是同一个人。"
如果训练数据里这两个词关联较弱,它可能瞎编:"是亲兄弟。"
LLM 不是搜索引擎,它是"概率引擎"。所以涉及到精确事实(日期、数字、人名),永远要交叉验证。
2.6 7B、70B、175B 是什么意思?
你常看到模型名字后面带个"B",比如 Llama-3-70B、GPT-4 据传是 1.8T。
- B = Billion(十亿)
- 70B 表示这个模型有 700 亿个参数
参数是什么?可以理解为模型大脑里的"神经元连接"。参数越多,模型越聪明,但运行越贵、越慢。
| 规模 | 类比 | 能力 | 部署 |
|---|---|---|---|
| 7B | 小学生 | 简单对话、基础任务 | 一张消费级显卡就能跑 |
| 70B | 大学生 | 复杂推理、写代码 | 需要服务器级显卡 |
| 175B+ | 博士专家 | 顶尖能力,接近 GPT-4 | 需要多卡集群 |
一句话总结:LLM 是一个被"海量阅读 + 礼仪调教"打造出来的"接话天才",它的回答本质是"概率最高的猜测",不是"事实查询"。
三、Tools 工具:给 AI 装上"手"
3.1 LLM 的致命短板
LLM 再聪明,也有个根本问题:它只会"嘴上说",不会"动手做"。
举个例子,你问 LLM:"帮我查一下今天上海的天气。"
它会怎么回答?
- 老老实实版:"抱歉,我无法访问实时信息,但根据历史数据,上海6月通常多雨……"
- 胡说版:"今天上海晴,25度。"(瞎编的)
为什么会这样?因为 LLM 是一个"封闭的大脑":
- ❌ 不能上网
- ❌ 不能读你的文件
- ❌ 不能执行任何命令
- ❌ 不知道现在几点
- ❌ 不能调用任何外部服务
它就像一个被关在小黑屋里的天才——脑子很好用,但出不了门。
3.2 Tools 是什么?
Tools(工具/函数调用)就是给 AI 打开小黑屋的门,给它装上"手",让它能操作真实世界。
具体来说,开发者会给 AI 准备一些"工具",比如:
get_weather(city)—— 查天气read_file(path)—— 读文件send_email(to, subject, body)—— 发邮件run_python(code)—— 跑代码
AI 不直接执行这些工具,而是"决定调用哪个工具",由外部程序真正执行。
3.3 一个完整的例子
你对 AI 说:"帮我看下今天北京天气,如果下雨就提醒我带伞。"
AI 内部的运作:
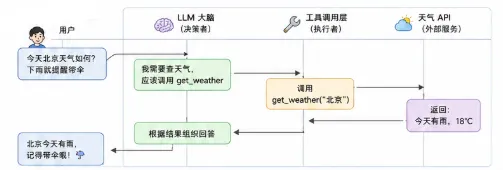
整个过程:
- AI 理解你的意图:你要查天气
- AI 决策:需要调用
get_weather工具 - 工具真正执行,返回数据
- AI 拿到数据,组织成人话回答你
3.4 Tools 让 AI 从"嘴炮"变"实干家"
有了 Tools,AI 能做的事情爆炸式增长:
| 任务 | 没有 Tools | 有 Tools |
|---|---|---|
| 查最新股价 | "我没有实时数据" | 实时查询返回 |
| 改你的代码 | "你应该这样改..." | 直接帮你改了 |
| 订机票 | "你可以去携程..." | 直接帮你下单 |
| 发邮件给同事 | "邮件模板如下..." | 邮件已发送 |
这就是 Cursor、Claude Code、Devin 这些工具能"真的帮你干活"的根本原因——它们给 LLM 配了一套强大的工具集。
3.5 安全问题:要给 AI 多大的权限?
工具越强大,风险越大。想象一下:
- 你让 AI "清理一下我的下载文件夹"
- 它误解为 "清理我的硬盘"
- 调用
delete_folder("/")工具 - 💥 系统挂了
所以现实中,给 AI 配工具一般遵循三条原则:
- 最小权限:只给完成任务必要的工具,不多给
- 人工确认:危险操作(删文件、转账、发邮件)必须人确认
- 沙箱执行:在隔离环境中运行,错了也炸不到主系统
一句话总结:Tools 是 AI 的"手",让它从只会说话的脑袋,变成能真正改变世界的"完整人"。
四、MCP:AI 时代的"USB-C 标准"
4.1 在 MCP 之前,世界有多痛苦
假设你是 Cursor 的开发者。用户想让 AI 能接入这些服务:
- GitHub(管代码)
- Notion(管笔记)
- Slack(发消息)
- Figma(看设计稿)
- 公司内网数据库
- ……
怎么接?每个服务的 API 都不一样:
- GitHub 用 REST API + Token 认证
- Notion 用 GraphQL API + OAuth 认证
- Slack 用 WebSocket + Bot Token
- Figma 又是另一套
- 每接入一个,写一堆适配代码
更糟的是:
- Claude Desktop 想接这些服务,要重写一遍
- ChatGPT 想接这些服务,再写一遍
- Cursor 想接这些服务,又写一遍
N 个 AI 工具 × M 个外部服务 = N × M 套对接代码,开发者疯了,用户也用得很碎。
4.2 USB-C 的故事
你想想 5 年前用手机有多麻烦:
- 安卓手机 —— Micro USB
- 苹果手机 —— Lightning
- 老款笔记本 —— 圆口电源
- 新款笔记本 —— USB-C
- 数码相机 —— Mini USB
- ……
出门要带 5 种线,绝望。
然后 USB-C 出现了。一根线,搞定所有设备。
MCP 就是 AI 工具领域的 USB-C。
4.3 MCP 是什么?
MCP = Model Context Protocol(模型上下文协议),由 Anthropic(Claude 的母公司)在 2024 年 11 月推出的开放标准。
它定义了一套统一的"语言",规定:
- AI 工具怎么向外部服务请求数据
- 外部服务怎么向 AI 暴露能力
- 数据格式、认证方式、调用流程……全部统一
结果:每个外部服务只需要写一个 MCP Server,所有支持 MCP 的 AI 工具(Claude、Cursor、各种 IDE)都能直接接入。
4.4 架构对比
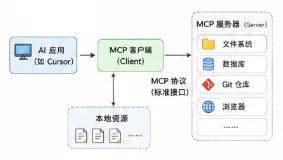
4.5 MCP 的三个角色
- MCP Host(宿主):AI 应用本身。比如 Claude Desktop、Cursor、各种 IDE。
- MCP Client(客户端):宿主内置的连接器,负责跟 Server 通信。
- MCP Server(服务端):包装某个具体服务的代理。比如"GitHub MCP Server"就是把 GitHub API 包装成 MCP 标准格式。
普通用户不需要关心 Client,只需要:
- 下载支持 MCP 的 AI 工具(如 Claude Desktop)
- 安装需要的 MCP Server(如 GitHub Server)
- 配置完成,AI 就能直接操作 GitHub 了
4.6 MCP 的现状
- 谁推的:Anthropic(Claude 母公司)
- 谁支持:Claude Desktop、Cursor、Continue、Zed 等已支持,OpenAI 据传也在考虑
- 生态:GitHub 上已有几百个开源 MCP Server,覆盖 GitHub、Slack、PostgreSQL、Google Drive 等等
- 趋势:正在成为事实标准
一句话总结:MCP 是让 AI 接入外部世界的统一插头标准。它解放了开发者,也让普通用户能"插拔式"扩展 AI 能力。
五、Agent:AI 从"实习生"进化成"员工"
5.1 三代 AI 使用方式
要理解 Agent,得先看 AI 是怎么一步步进化的:
第一代:纯聊天(2022年的 ChatGPT)
你:帮我写一个排序函数
AI:好的,代码如下 [代码]
你:(复制粘贴)(自己运行)(出错了)
你:报错了,第5行错了
AI:可能是XX原因,你试试这样改 [新代码]
你:(再复制粘贴)(再运行)(还是错)
你:还是不行
AI:可能是YY原因……
痛点:AI 嘴炮,所有体力活都得你来。
第二代:带工具的助手(GPT-4 + Plugins 时代)
你:帮我写一个排序函数,存到 sort.py
AI:(自己调用 write_file 工具)已保存
你:跑一下看看
AI:(自己调用 run_python 工具)报错了,错误信息:xxx
你:那你修一下
AI:(自己调用 edit_file 工具)已修复,再跑一次 [运行结果]
进步:AI 真的能操作文件、执行命令,但还是你一步步催。
第三代:Agent(Devin、Claude Code、Cursor Agent 时代)
你:帮我写一个排序函数,写完测试一下,能用了再告诉我
AI:好的(开始工作)
→ 创建 sort.py
→ 写入代码
→ 运行测试
→ 发现错误
→ 自己分析原因
→ 修改代码
→ 重新测试
→ 测试通过
→ 汇报:完成了,函数已通过 3 个测试用例
质变:你下任务,AI 自己规划、自己执行、自己验收。真正的"员工"模式。
5.2 Agent 的三大核心能力
一个真正的 Agent 必须具备三种能力,缺一不可:
能力一:规划(Planning)
拿到任务后,自己拆解步骤。
例子:你说"帮我搭一个个人博客",Agent 自己拆:
- 选技术栈(Next.js + Tailwind)
- 初始化项目结构
- 设计页面(首页、文章页、关于页)
- 实现导航、文章列表、文章详情
- 配置部署到 Vercel
- 测试整个流程
能力二:工具使用(Tool Use)
根据每一步需求,自主选用合适的工具。
例子:
- 初始化项目 → 调用
run_command("npx create-next-app") - 创建文件 → 调用
write_file - 安装依赖 → 调用
run_command("npm install") - 测试网页 → 调用
open_browser+take_screenshot
能力三:反思与迭代(Reflection)
执行中遇到问题,能自己调整。
例子:
- 部署失败 → 看错误日志 → 发现是配置问题 → 修改配置 → 重新部署 → 成功
- 测试报错 → 分析原因 → 修改代码 → 重测 → 通过
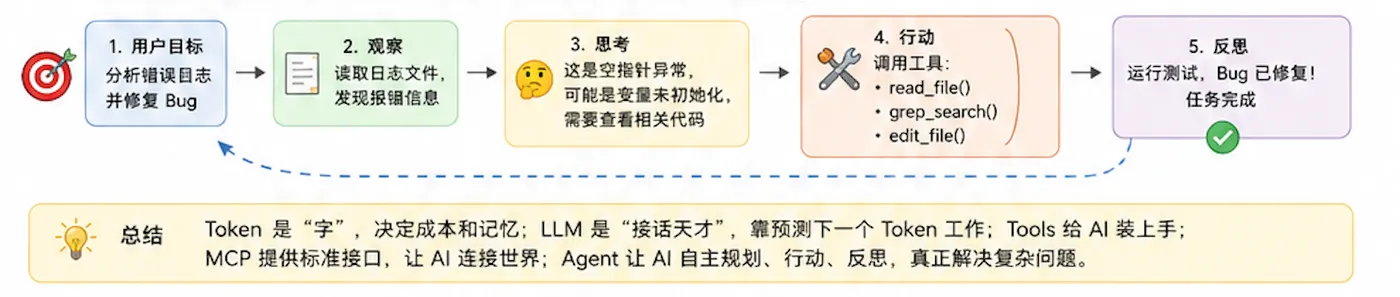
5.3 Agent 完整工作流
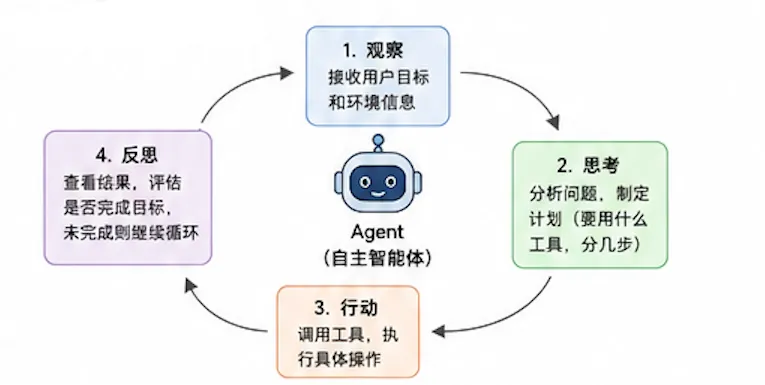
5.4 当前主流 Agent 产品
| 产品 | 定位 | 适合谁 |
|---|---|---|
| Claude Code | 命令行 Coding Agent | 程序员,命令行重度用户 |
| Cursor (Agent模式) | IDE 内置 Agent | 程序员,喜欢图形界面 |
| Devin | 完全自主软件工程师 | 想 AI 全包干活的人 |
| GitHub Copilot Workspace | 任务级辅助 | GitHub 重度用户 |
| Manus | 通用任务 Agent | 非程序员(中国出品) |
5.5 Agent 还做不到什么?
吹完优点,得说说局限:
❌ 复杂决策仍需人介入:涉及商业判断、伦理问题,Agent 会犹豫或出错。
❌ 长时任务容易跑偏:任务超过几个小时,Agent 可能"迷路",需要人重新校准方向。
❌ 创造力有限:能做"按部就班"的活,但真正的创新还得靠人。
❌ 成本高:Agent 每次操作都消耗大量 Token,复杂任务可能花几十美元。
❌ 可解释性差:它为什么这么决策?有时候连开发者都说不清。
一句话总结:Agent = LLM + Tools + 规划能力 + 反思能力,是 AI 时代的"数字员工"。它已经能干很多活,但还离"完美自主"有距离。
六、五个概念串成一张图
到这里,我们把所有概念串起来:
用一句话串联:
你用自然语言对 Agent 下任务,Agent 调用 LLM 这个大脑思考(思考时按 Token 计费),LLM 决定要调用哪些 Tools 来操作真实世界,所有 Tools 都通过 MCP 这个统一协议接入各种外部服务——这就是完整的 AI Coding 工作链路。
七、对照表:5个概念的人话版
| 概念 | 人话版 | 类比 | 你应该关心的 |
|---|---|---|---|
| Token | AI 的"字数单位" | 收银台的扫码计费 | 花了多少钱、AI 记不记得住 |
| LLM | AI 的"大脑" | 阅读量上亿的学霸 | 准不准、会不会胡说 |
| Tools | AI 的"手" | 大脑+遥控器 | AI 能做什么、安不安全 |
| MCP | AI 工具的"USB 标准" | 统一充电口 | 接入哪些服务、好不好用 |
| Agent | AI 的"自主员工" | 实习生→正式员工 | 它会规划吗、能反思吗 |
八、读完以后,你能做什么?
1. 听得懂别人聊 AI
朋友说"这个 Agent 调用工具调爆 Token"——你瞬间懂:他在说一个智能体调用工具太多导致花费过高。
2. 选对 AI 工具
- 简单聊天:用 ChatGPT、Claude、豆包
- 写代码:用 Cursor、Claude Code
- 自动化任务:用支持 Agent 模式的工具
- 接入企业服务:找支持 MCP 的工具
3. 控制成本
知道 Token 收费机制后,你会:
- 把无用历史对话清掉(节省上下文)
- 复杂任务拆开做(避免单次太长)
- 选合适的模型(不是越贵越好)
4. 避免被忽悠
有人吹"我们的 AI 是 1000B 参数的最强 Agent"——你能问出关键问题:"用的什么 LLM?调用了哪些工具?是怎么规划的?"
写在最后
AI 时代不是"会用 AI 的人"和"不会用 AI 的人"之间的分别。
真正的分水岭,是"理解 AI 怎么运作的人"和"只会喊口号的人"之间的差距。
这五个概念,是你打开 AI 世界的第一把钥匙。
下一篇,我会带你从零搭建你的第一个 AI Coding 工作环境,让这些概念真正变成你手里的生产力。
喜欢的话,点个「在看」让更多人看见 ❤️
下篇预告:《零基础搭建你的第一个 AI Coding 环境》
关于本号
白话说 AI · 用最通俗的语言讲清楚最酷的技术
拒绝晦涩 · 拒绝堆砌 · 拒绝焦虑营销
转发给那个还在 AI 门外的朋友

