
用语言模型写代码、查数据库、跑自动化流程这些事情大家早就习以为常了。Vibe Coding 到今年二月刚好满一年,绝大多数人或多或少都在用它搞定代码库、写文档、处理各种杂活。但有一个问题始终是避免不了的:任务一多Agent 就开始丢三落四甚至开始一本正经地胡说八道。
MCP 让外部工具的接入变得很方便,Playwright、Supabase、Slack 这些都能挂上去,但代价是Context Rot [1]。简单说就是输入 Token 一多模型性能就会塌方式下降。
我们先看看上下文窗口里到底装了些什么。
Claude的内存结构拆解

拿 Claude 举例,它的上下文窗口大致是这么分配的:系统提示词占 1.4%系统工具(包括 MCP 工具)占 8.3%,Agent 上下文(技能、工具描述、对话历史)吃掉约 70%,用户实际能用的提示词空间反而很小。
Anthropic 的研究数据表示:真正用来放系统级指令的部分只有大约 10%,剩下全被对话历史、工具输出和各种中间结果给填满了。一旦膨胀到 200K Token 的量级模型根本分不清什么才是重点。
模型健忘、幻觉频发的根本原因就是 Context Rot。一个缓解思路是 Ralph Wiggum Loop,可以更合理地利用上下文窗口。
CodeAct
CodeAct[2] 是 2024 年的一篇论文,核心思想非常简单:既然语言模型天然擅长写代码为什么不直接让它用可执行代码来和外部世界交互?说白了就是用代码当动作空间。这个想法对任何写过程序的人来说都不陌生。
举个最简单的例子,假设要做一个学生数据库管理系统,现在需要查 2025 年入学的所有学生。如果让语言模型自己在上下文里逐条扫描记录来"推理",那既慢又不靠谱。但换个思路直接写一条 SQL:
SELECT *
FROM students
WHERE enrollment_year = 2025;
跑一下就完事了。把检索的工作交给数据库引擎,这才是正常开发者的做法。
CodeAct 的逻辑完全一样,与其把海量数据塞进上下文让模型去"理解"(顺便制造 Context Rot),不如让模型写一段代码、执行它、拿到结果。
Image from [2] — CodeAct in multi-turn interaction framework


回到刚才的学生数据库场景,CodeAct 的工作流是这样的:先接收用户的自然语言查询——
Find me the record of students who have been enrolled in the year 2025
然后通过一次 LM 调用理解意图,生成 Python 代码,在编译器里跑一遍,检查输出。结果满意就直接返回,不满意就继续迭代修正,直到拿到正确答案。
1、原子工具使用:CodeAct 匹配或超越 JSON/Text
第一组实验测的是最基础的场景:单个 API 调用。在 API-Bank 基准上作者对比了文本格式调用、JSON 格式调用和 CodeAct(Python 函数调用)三种方案。
即便在这种完全用不上控制流优势的简单场景下,CodeAct 在多数模型上的正确率都持平甚至更高。GPT-4、Claude 这些闭源模型在三种格式上都表现稳定,但开源模型从 CodeAct 中获益明显更大。合理的解释是:预训练阶段见过大量代码的模型,用代码表达动作比用 JSON 更自然、更顺手。

Image from [2] — Atomic API call correctness comparison.
2、复杂多工具任务:CodeAct 实现更高成功率
真正拉开差距的是多工具组合场景。M3ToolEval 基准包含 82 个人工精选的多工具任务,CodeAct 在这里的优势就很明显了——模型可以在一个代码块里组合多个工具、用循环和条件语句控制流程、存储中间变量、跨步骤复用输出。
数据上看,最佳模型的成功率绝对提升了 20.7%,交互轮次平均减少 2.1 轮。有意思的是,模型越强,从结构化动作空间里获得的收益就越大。
Image from [2] — Success rate comparison
Image from [2] — Full M3ToolEval results


3、多轮自调试
CodeAct 带来了一个很有意思的能力:自调试。因为动作本身就是代码,执行出错会产生 traceback,模型直接拿到结构化的错误反馈,下一轮就可以针对性地修复。
论文里展示了一个典型案例:CodeActAgent 先用 Pandas 下载数据,然后训练回归模型、可视化系数,中间碰到 matplotlib 报错就自己修,发现缺失值就自己处理。整个过程不是简单的工具调用,而是基于执行反馈的迭代推理。
Image from [2] — Multi-turn interaction example.

4、微调后的 CodeActAgent 进一步提升性能
作者构建了 CodeActInstruct 数据集(约 7k 条多轮轨迹),在此基础上微调出了 CodeActAgent。相比基础的 LLaMA-2 和 Mistral 有大幅提升,在 MINT 任务上表现突出,跟更大规模的模型相比也有竞争力。
比如 CodeActAgent(Mistral-7B),在同等规模的开源模型里排在前列,通用 Agent 任务得分明显提高,同时在 MMLU、GSM8K、HumanEval 等通用能力评测上也没有退化。
Image from [2] — CodeActAgent evaluation.

从实验数据整体来看,CodeAct 做到的不只是格式上的改进。它实质上重构了 Agent 的动作空间——模型获得了控制流、数据流、可复用变量和自动反馈循环。工具使用不再是一个接一个地调 API,而是变成了可编程的推理过程。交互步骤更少,任务成功率更高,特别是在需要组合多个工具的场景下。
实现
我先试了 langchain-codeact[3] 这个包,但坑不少,而且只兼容 Anthropic 的模型,所以干脆自己撸了一个小原型。
实验环境用的 Google Colab + OpenAI API。生产环境建议用隔离沙箱。
导入依赖
import os
import re
import io
import contextlib
from openai import OpenAI
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
client = OpenAI()
两个工具函数:一个从 LM 输出里提取 Python 代码块,另一个用内置的 exec() 执行它。
def extract_python_code(text: str):
pattern = r"```python(.*?)```"
match = re.search(pattern, text, re.S | re.I)
return match.group(1).strip() if match else None
def run_python(code: str):
buf = io.StringIO()
try:
with contextlib.redirect_stdout(buf):
exec(code, {})
return buf.getvalue()
except Exception as e:
return f"Execution error: {e}"
CodeAct 循环,这里用 GPT-5-mini 作为底座模型,因为需要推理能力。
SYSTEM_PROMPT="""
You are a CodeAct agent.
Always solve using Python code.
Return ONLY a python code block.
Do not explain in text.
"""
def codeact_run(user_problem, max_iters=3):
messages= [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_problem}
]
for step in range(max_iters):
resp=client.chat.completions.create(
model="gpt-5-mini",
messages=messages
)
text=resp.choices[0].message.content
print("\n===== MODEL OUTPUT =====\n")
print(text)
code=extract_python_code(text)
if not code:
print("\n No code block — retrying\n")
messages.append({
"role": "user",
"content": "Return python code block only."
})
continue
print("\n EXECUTING PYTHON:\n")
print(code)
output=run_python(code)
print("\n PYTHON OUTPUT:\n")
print(output)
returnoutput
print("Failed to obtain executable code.")
returnNone
整个流程就是:让 LM 理解问题、写 Python 代码,extract_python_code() 提取代码,run_python() 执行,拿到结果。
problem="""
A batter hits a baseball at 45.847 m/s at 23.474 degrees.
Outfielder throws it back at 24.12 m/s at 39.12 degrees.
Find final distance from batter.
Assume no air resistance and g = 9.8.
"""
codeact_run(problem)
输出:
===== MODEL OUTPUT =====
```python
import math
# Given values
v1 = 45.847 # m/s, initial hit speed
theta1_deg = 23.474 # degrees
v2 = 24.12 # m/s, outfielder throw speed
theta2_deg = 39.12 # degrees
g = 9.8 # m/s^2
# Convert to radians
theta1 = math.radians(theta1_deg)
theta2 = math.radians(theta2_deg)
# Range of the initial hit (from batter, to the right is positive)
R1 = (v1**2) * math.sin(2 * theta1) / g
# Outfielder throws back toward the batter: horizontal velocity is negative
vx2 = -v2 * math.cos(theta2)
vy2 = v2 * math.sin(theta2)
# Time of flight for the throw (starting and ending at ground level)
t2 = 2 * vy2 / g
# Horizontal displacement of the throw relative to outfielder's position
dx2 = vx2 * t2
# Final x-position relative to batter (batter at x=0)
x_final = R1 + dx2
# Distance from batter (absolute)
distance_from_batter = abs(x_final)
print(f"Initial landing distance from batter (R1): {R1:.3f} m")
print(f"Horizontal displacement from outfielder's throw (dx2): {dx2:.3f} m")
print(f"Final position relative to batter (x_final): {x_final:.3f} m")
print(f"Final distance from batter: {distance_from_batter:.3f} m")
EXECUTING PYTHON:
import math
Given values
v1 = 45.847 # m/s, initial hit speed
theta1_deg = 23.474 # degrees
v2 = 24.12 # m/s, outfielder throw speed
theta2_deg = 39.12 # degrees
g = 9.8 # m/s^2
Convert to radians
theta1 = math.radians(theta1_deg)
theta2 = math.radians(theta2_deg)
Range of the initial hit (from batter, to the right is positive)
R1 = (v1*2) math.sin(2 * theta1) / g
Outfielder throws back toward the batter: horizontal velocity is negative
vx2 = -v2 math.cos(theta2)
vy2 = v2 math.sin(theta2)
Time of flight for the throw (starting and ending at ground level)
t2 = 2 * vy2 / g
Horizontal displacement of the throw relative to outfielder's position
dx2 = vx2 * t2
Final x-position relative to batter (batter at x=0)
x_final = R1 + dx2
Distance from batter (absolute)
distance_from_batter = abs(x_final)
print(f"Initial landing distance from batter (R1): {R1:.3f} m")
print(f"Horizontal displacement from outfielder's throw (dx2): {dx2:.3f} m")
print(f"Final position relative to batter (x_final): {x_final:.3f} m")
print(f"Final distance from batter: {distance_from_batter:.3f} m")
✅ PYTHON OUTPUT:
Initial landing distance from batter (R1): 156.731 m
Horizontal displacement from outfielder's throw (dx2): -58.119 m
Final position relative to batter (x_final): 98.612 m
Final distance from batter: 98.612 m
'Initial landing distance from batter (R1): 156.731 m\nHorizontal displacement from outfielder\'s throw (dx2): -58.119 m\nFinal position relative to batter (x_final): 98.612 m\nFinal distance from batter: 98.612 m\n'
到这里可以看到 CodeAct 是怎么让模型动手干活的——写代码、执行、拿结果,LLM 有了"编程的手",不再只是被动回答问题。
但还有一个问题没解决。
模型能写代码了,可如果输入本身就极其庞大呢?几百页的报告、几个 G 的日志、整个代码仓库——单次前向传播根本消化不了这么多信息。
那如果代码不只是用来调 API、查数据库,而是用来组织模型自身的推理过程呢?
这就是递归语言模型(Recursive Language Models)要解决的事情。模型不再写代码去调用外部工具,而是写代码来调用自己——把大任务拆成小任务,分别处理,最后把结果拼起来。
> CodeAct 是代码作为动作接口,RLM 是代码作为推理控制器。
## RLM 递归语言模型

RLM [4] 由 Alex Zhang 和 Omar Khattab 在 2025 年 10 月提出。他们在论文中明确表示受到了 CodeAct 的启发,但认为 CodeAct 在面对超长上下文的推理任务时力不从心。
用伪代码描述 RLM 的工作方式:
huge document
→ split into sections
→ model analyzes each section
→ model summarizes
→ model calls itself on summaries
→ final answer
论文给出的正式定义是:"一种通用推理策略,将长提示词视为外部环境的一部分,允许 LLM 以编程方式检查、分解并递归地在提示词片段上调用自身。"
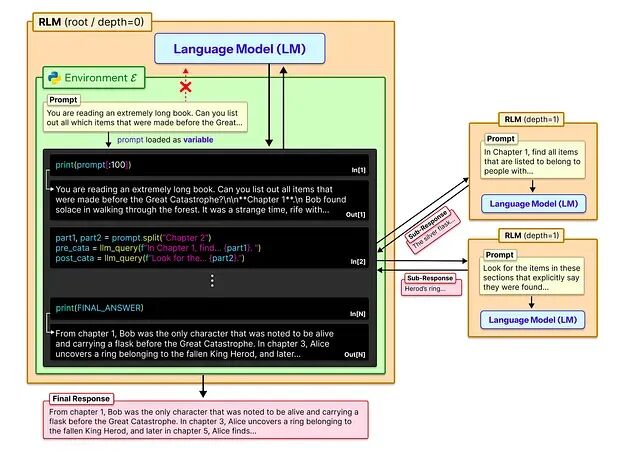
Image from [4]
上图来自 RLM 论文 [4],展示的是如何处理一整本书这样的超大上下文。RLM 不会把完整文本硬塞进模型(塞不进去),而是把提示词当作外部环境来对待。具体操作是:先把提示词作为变量加载到 REPL 环境里,然后用代码把它拆成可管理的小块。根语言模型(depth = 0)通过代码执行检查文本的不同部分,挑出跟任务相关的块,对这些块发起递归子调用(depth = 1)。每个子调用只看自己那一小段上下文,返回中间结果,最后由根模型把这些结果聚合起来生成最终响应。这套机制绕过了上下文窗口的硬限制,让模型可以通过结构化分解和受控递归处理任意长度的输入。
### 不同上下文长度下的性能表现
RLM 的核心主张是能把推理能力扩展到标准 LLM 固定上下文窗口之外。实验数据很支持这个论断。
在 S-NIAH(恒定复杂度)、OOLONG(线性复杂度)、OOLONG-Pairs(二次复杂度)三个基准上,基础语言模型的表现都是随输入长度增加快速崩塌的,任务复杂度越高崩得越厉害。RLM 则一路稳住了——哪怕输入规模到了百万 Token 量级,远远超过底层模型的原生窗口大小,表现依然稳健。

Image from [4] — the log-scale performance vs input length graph.
### 信息密集型推理任务的性能
差距最大的地方在信息密集型任务上。OOLONG 和 OOLONG-Pairs 要求模型聚合输入的几乎每个部分,做语义变换,根据成对关系构建输出——简单说就是不能跳过任何信息。
在 OOLONG-Pairs 上,基础模型的 F1 分数接近零,根本处理不了长上下文下的密集关系推理。RLM 却通过递归分解展示了涌现能力,GPT-5 的配置下拿到了 58% 的 F1。
这说明 RLM 做的不只是"看更多 Token"这么简单。它改变的是推理本身的执行方式。

Image from [4] — performance comparison table.
### 效率和成本分析
递归推理听起来开销应该很大,但实际数据却不是这样:RLM 的平均 API 成本跟基础模型差不多,有时候反而更低。
原因在于 RLM 不会获得整个上下文。它通过代码执行和针对性的子调用只探测相关部分,避免了全量上下文的输入,减少了无效 Token 的处理,计算资源只分配到真正需要的地方。虽然由于执行轨迹的不同,RLM 的成本方差会大一些,但中位成本通常跟摘要压缩之类的基线策略持平甚至更低。
好的推理性能靠的不是暴力堆算力,而是结构化分解和选择性上下文交互。

Image from [4]-cost distribution quartiles.
RLM 的核心优势不在于访问了更多 Token,而在于彻底改变了推理的计算结构。把提示词外化到环境中、允许递归子调用,推理就从被动地消耗 Token 变成了主动的信息检索和受控分解。Context Rot 被削弱了,推理时的信噪比上去了,任意长度的输入都可以通过可扩展的聚合来处理。本质上RLM 把长上下文推理从内存瓶颈问题转化成了一个编程式的搜索问题。
### 实现
我这里用一本 Arthur Conan Doyle 的《福尔摩斯探案集》(txt 格式)[5] 当输入。Grammerly 统计下来单词量超过 1M,字符数约 6.5M。

using Grammerly for word count
按 OpenAI[6] 的换算规则,常见英文文本中 1 个 Token 大约对应 4 个字符,也就是约 0.75 个单词。6.5M 字符对应大约 1.625M Token。

Image from [7]
OpenAI 当前最强模型的上下文窗口是 400,000 Token,我实验用的 GPT-4.1-mini 是 1,047,576 Token。但实际推理时用户拿不到全部窗口,系统提示词、工具描述之类的要占掉一大块,输入输出 Token 还得共享这个空间。就算假设能用满 1,047,576 的窗口,1,625,000 Token 的输入也放不进去。
所以问题很明确:这么大的上下文,怎么用 RLM 来处理?
实验任务是让模型"提取前 20 个最频繁出现的大写实体,并总结 3 个主要主题"。
安装依赖,用 pip 装 rlms[8] 包:
!pip install -qU rlms
导入包,加载环境变量(Google Colab 的写法略有不同):
import os
from rlm import RLM
from rlm.logger import RLMLogger
from google.colab import userdata #google colab
api_key = userdata.get('OPENAI_API_KEY')
加载文档,创建 RLMLogger 存日志:
with open("big.txt", "r", encoding="utf-8") as f:
large_document = f.read()
print(f"Loaded document with {len(large_document)} characters.")
logger = RLMLogger(log_dir="./logs")
初始化 RLM environment 设成 local, Python 内置的 exec() 来跑代码。也可以换成 docker、prime-sandbox、modal、daytona 之类的外部服务。
max-depth 设成 1,跟论文里一致,调用结构是这样的:
Root LM
├── Sub LM call
├── Sub LM call
└── Sub LM call
如果 max-depth = 2 就多一层嵌套:
Root LM
├── Sub LM
│ ├── Sub-Sub LM
│ └── Sub-Sub LM
└── Sub LM
└── Sub-Sub LM
以此类推。
rlm = RLM(
backend="openai",
backend_kwargs={
"model_name": "gpt-4.1-mini", # You can upgrade to stronger model
"api_key": api_key,
},
environment="local",
environment_kwargs={},
max_depth=1, # Depth-1 recursion like in paper
logger=logger,
verbose=True,
)
prompt = f"""
You are analyzing a large enterprise document.
Return ONLY valid JSON.
TASK:
Extract the top 20 most frequent capitalized entities
and summarize 3 major themes.
Document:
{large_document}
"""
result = rlm.completion(prompt)
print("\n RLM Analysis Result:\n")
print(result)
结果出来了:
Loaded document with 6488666 characters.
╭─ ◆ RLM ━ Recursive Language Model ──────────────────────────────────────────────────────────────────────────────╮
│ │
│ Backend openai Environment local │
│ Model gpt-4.1-mini Max Iterations 30 │
│ Max Depth 1 │
│ │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
────────────────────────────────────────────────── Iteration 1 ──────────────────────────────────────────────────
╭─ ◇ LLM Response (1.57s) ───────────────────────────────────────────────────────────────────────────────────────╮
│ repl │ │ # First, let's see what the prompt or question is exactly, and inspect the beginning of the context to │ │ understand what type of information it contains. │ │ print(context[:2000]) # print the first 2000 chars to get an idea of what the context looks like │ │ │
│ │
│ ~45 words │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ ▸ Code Execution (0.000s) ────────────────────────────────────────────────────────────────────────────────────╮
│ Code: │
│ # First, let's see what the prompt or question is exactly, and inspect the beginning of the context to │
│ understand what type of information it contains. │
│ print(context[:2000]) # print the first 2000 chars to get an idea of what the context looks like │
│ │
│ Output: │
│ │
│ You are analyzing a large enterprise document. │
│ │
│ Return ONLY valid JSON. │
|
| (To be continue)
|
───────────────────────────────────────────────── Iteration 25 ──────────────────────────────────────────────────
╭─ ◇ LLM Response (2.98s) ───────────────────────────────────────────────────────────────────────────────────────╮
│ FINAL({ │
│ "top_20_most_frequent_capitalized_entities": [ │
│ ["Holmes", 278], │
│ ["Watson", 114], │
│ ["Mr", 92], │
│ ["Sherlock Holmes", 77], │
│ ["Baker Street", 23], │
│ ["McCarthy", 22], │
│ ["Neville St. Clair", 22], │
│ ["Irene", 20], │
│ ["Adler", 18], │
│ ["London", 18], │
│ ["King", 17], │
│ ["Hosmer Angel", 16], │
│ ["Henry Baker", 14], │
│ ["Lestrade", 12], │
│ ["Bohemia", 11], │
│ ["City", 11], │
│ ["Mr. Windibank", 11], │
│ ["K. K. K.", 11], │
│ ["Mrs. St. Clair", 11], │
│ ["Lascar", 11] │
│ ], │
│ "top_3_major_themes_summary": [ │
│ "Deduction and Observation", │
│ "Deception and Disguise", │
│ "Mystery and Detection" │
│ ] │
│ }) │
│ │
│ ~68 words │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ ★ Final Answer ────────────────────────────────────────────────────────────────────────────────────────────────╮
│ │
│ { │
│ "top_20_most_frequent_capitalized_entities": [ │
│ ["Holmes", 278], │
│ ["Watson", 114], │
│ ["Mr", 92], │
│ ["Sherlock Holmes", 77], │
│ ["Baker Street", 23], │
│ ["McCarthy", 22], │
│ ["Neville St. Clair", 22], │
│ ["Irene", 20], │
│ ["Adler", 18], │
│ ["London", 18], │
│ ["King", 17], │
│ ["Hosmer Angel", 16], │
│ ["Henry Baker", 14], │
│ ["Lestrade", 12], │
│ ["Bohemia", 11], │
│ ["City", 11], │
│ ["Mr. Windibank", 11], │
│ ["K. K. K.", 11], │
│ ["Mrs. St. Clair", 11], │
│ ["Lascar", 11] │
│ ], │
│ "top_3_major_themes_summary": [ │
│ "Deduction and Observation", │
│ "Deception and Disguise", │
│ "Mystery and Detection" │
│ ] │
│ } │
│ │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════
Iterations 25
Total Time 397.59s
Input Tokens 2,026,303
Output Tokens 98,396
═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════
```
25 轮迭代,总耗时约 400 秒,处理了 2M 输入 Token(含子 LM 调用)输出约 98,000 Token。给了一个塞不进任何上下文窗口的巨大输入,模型还是给出了接近正确的结果。
Actual count vs RLM count

跟确定性正则匹配的计数比,RLM 的输出有轻微偏差。这可以理解因为RLM 做的是跨 chunk 的递归语义实体提取,不是严格的词法计数。聚合过程中会引入累计漂移,高频实体和变体形式尤其容易受影响。但关键是模型准确识别了语料库的主要叙事主题。RLM 追求的是结构化的语义理解而非 Token 粒度的精确计数。
DSPy 也把 RLM 集成进了自己的包里,可以直接用 dspy.RLM [10]。
总结:动作 vs 推理——选择正确的范式
大语言模型已经不只是文本生成器了。它们正在变成可编程的系统。CodeAct 和 RLM 是这条进化路径上两个方向不同但可以组合的范式。这两种方法都让 LLM 的推理过程变得透明可观察:中间步骤、执行轨迹、分解结构都暴露出来了,开发者不用再对着一个黑箱去猜模型在想什么。
CodeAct 把 LLM 变成了执行引擎。模型不再只是给你一个文本答案,而是写代码、跑代码、看结果,不满意就再来一轮。适合的场景包括工具调用与 API 编排、数据库查询与数据处理、流程自动化,以及需要通过执行来验证正确性的结构化问题求解。一句话概括:CodeAct 适合需要"动手做事"的任务。
RLM 走的是另一个方向。它不是让模型去操作外部世界,而是让模型用代码来组织自己的推理过程——递归分解大输入、通过受控子调用聚合结果。适用于超长文档处理、多文档推理、信息密集型的分析任务、跨大规模语料库的结构化聚合。RLM 解决的是推理规模的瓶颈。
CodeAct 是代码作为动作接口,RLM 是代码作为推理控制器。
两者不是互斥的。在生产系统里完全可以组合使用——RLM 负责在海量上下文中完成推理,CodeAct 负责把决策执行出去、跟外部系统交互。
这里真正的范式转移是:与其一味地扩大上下文窗口,不如去重构计算本身。无论是 CodeAct 的执行循环还是 RLM 的递归分解,LLM 系统的未来不在于能吃下多少 Token,而在于如何更聪明地控制推理和动作。
引用
https://avoid.overfit.cn/post/021ca9c0ed414fac82ab09532992b7df
by Shreyansh Jain




