
代码是最晚发声的那一层
很多项目在复盘时,都会给自己一个“看起来合理”的结论:
- 架构选错了
- 代码写得不够优雅
- 技术方案不够先进
这些结论并不是完全错误,
但它们有一个共同的问题:
它们几乎都发生在项目已经失控之后。
在真实工程里,代码层面的异常,
往往是最晚显现的症状,而不是病因。
项目真正开始失控的地方,
通常要早得多,也隐蔽得多。
项目失控时间轴——早期决策 vs 晚期代码问题
一个必须先讲清楚的事实:代码是“结果层”,不是“决策层”
我们先把一件事讲清楚。
在一个真实项目中,代码承担的角色是:
- 把已经确定的决策实现出来
- 把已经接受的假设固化成系统行为
它很少主动制造问题。
真正制造问题的,是代码之前的那些决定:
- 我们要解决什么问题
- 什么算“成功”
- 哪些风险可以接受
- 哪些不行
如果这些问题没有被清楚回答,
代码写得再漂亮,也只是把错误跑得更快。
第一条失控路径:问题定义开始模糊,但没人觉得这是个问题
几乎所有失控项目,在早期都会出现同一个信号:
大家对“我们到底在解决什么问题”,
开始出现轻微但持续的分歧。
一开始,这种分歧非常不起眼:
- 产品说的是体验
- 技术说的是效果
- 业务说的是覆盖率
每个人说的都“对”,
于是没人觉得这是风险。
但问题在于:
当问题定义不再一致时,
每一次优化,都会把系统往不同方向拉。
你后面看到的很多“技术分歧”,
其实都是这个阶段的延迟反应。
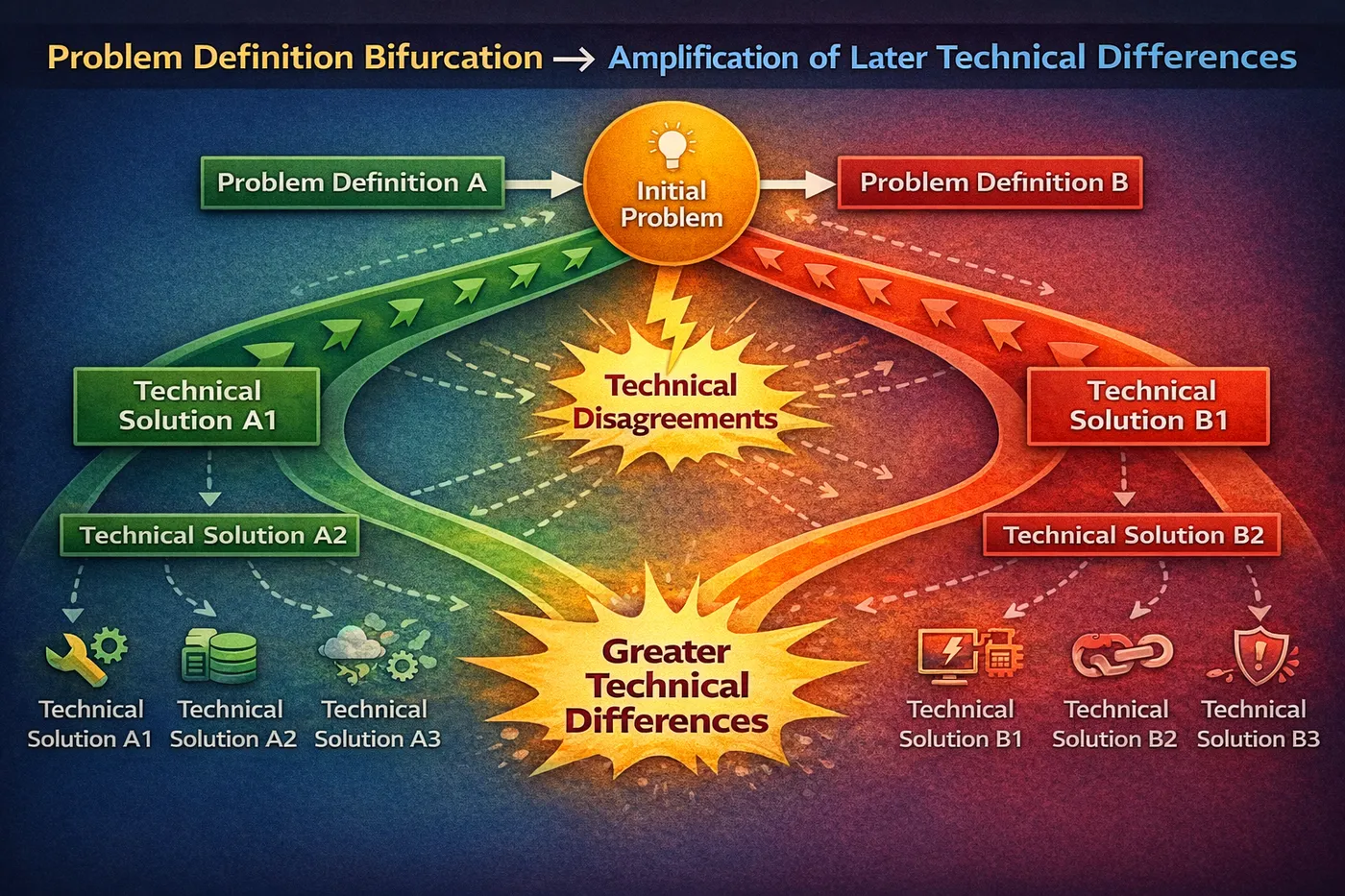
问题定义分叉 → 后期技术分歧放大示意图
第二条失控路径:评估指标先妥协了,但没人当回事
在项目初期,评估体系往往是“临时的”:
- 先用 loss 看看
- 先人工感觉一下
- 先把 demo 跑出来
这些选择在早期非常合理。
但失控项目的一个共同特征是:
临时评估,慢慢变成了长期评估。
你会发现:
- 重要但难量化的指标被忽略
- 风险类指标被放到“之后再说”
- 成功被简化成“看起来还行”
当评估开始妥协时,
项目其实已经失去了自我校正能力。
后面再怎么调代码,
都只是在沿着错误坐标系前进。
第三条失控路径:系统边界一直没画清楚
这是 AI 项目里最致命、也最常见的一条。
在早期阶段,大家往往会默认:
- 模型能多做一点
- 规则先简单一点
- 兜底以后再补
于是很多问题被默默交给了模型:
- 该不该答
- 是否合规
- 是否需要人工
- 是否存在风险
这些问题一开始并不会立刻爆炸,
因为用户量小、场景简单。
但随着使用规模扩大,
这些“没画清的边界”,会开始一个个变成事故。
而这时候你再回头看代码,
已经晚了。
第四条失控路径:复杂度被一次次“合理化”
失控项目里,经常能听到这些话:
- “先这样,之后再重构”
- “这只是个临时方案”
- “再加一层也不算复杂”
每一次复杂度增加,
在当下都有非常合理的理由。
但问题在于:
复杂度是会累积的,
而你的控制能力不会自动升级。
当系统复杂度超过团队的认知负载时,
失控就变成了一种必然。
而这时候,代码只是替罪羊。
第五条失控路径:团队开始依赖“解释”,而不是“约束”
这是一个非常明确、也非常危险的信号。
当系统出现异常行为时,
你开始听到越来越多的解释:
- “模型本来就是概率性的”
- “这个 case 比较极端”
- “从技术上讲也说得通”
解释本身并不错误,
但当解释开始取代约束,问题就来了。
因为你在做的是:
为不可控行为寻找合理性,
而不是减少它发生的概率。
这几乎可以作为一个项目即将失控的预警信号。
第六条失控路径:所有问题,最终都被归因到“再调一版”
这是很多 AI 项目的终局状态。
不管问题是什么,
最后都会落到一句话上:
“要不我们再调一版模型?”
这句话本身非常危险,
因为它意味着:
- 问题来源已经不清楚
- 责任边界已经模糊
- 技术成了情绪安慰剂
当“再调一版”成为默认答案时,
项目已经在结构上失控了。
一个非常真实的失控全景路径
一开始:问题定义不完全一致
↓
评估先凑合用
↓
系统边界没画清
↓
复杂度不断累积
↓
用解释替代约束
↓
所有问题都指向“再调模型”
注意:
这里面,没有一步是明显错误的。
正因为如此,它才如此危险。
为什么代码总是最后“背锅”的那一层
当项目真正出问题时,你最容易看到的是:
- 代码难维护
- 系统很乱
- 架构不清晰
于是复盘自然会指向:
- 技术选型
- 代码质量
但实际上,代码只是:
把前面所有模糊、妥协、逃避的决定,
忠实地执行了出来。
代码不是问题的源头,
只是问题的放大器。
一个非常实用的自检问题(强烈建议)
如果你想判断一个项目是否正在走向失控,可以问自己一句话:
如果今天冻结所有代码,
这个系统在逻辑上是否仍然是“可控的”?
- 如果答案是否定的 → 问题不在代码
- 如果答案是肯定的 → 那你才值得去优化代码
这是一个非常残酷,但非常有效的问题。
很多项目在失控前,其实早就出现了信号,只是缺乏一个能把“模型行为、评估结果和系统边界”放在同一视角下观察的工具。用LLaMA-Factory online把微调、评估、版本变化集中对照,更容易提前发现:问题是不是已经不该再从代码层解决了。
总结:当代码开始“看起来有问题”时,失控往往已经发生
我用一句话,把这篇文章彻底收住:
项目真正开始失控的那一刻,
通常不是代码写错了,
而是你已经默认了一些
“其实不该默认的事情”。
当你开始:
- 回到问题定义
- 重建评估坐标
- 明确系统边界
- 主动限制复杂度
你会发现:
- 很多“技术问题”自然消失了
- 代码反而变简单了
- 项目重新变得可控了
这不是因为你技术更强了,
而是因为你终于开始在决策层止损了。

