
PPO 最难的不是“理解”,而是“第一次真的跑通”
如果你已经看过 PPO 的原理文章,大概率会有一种感觉:
“逻辑我好像懂了,但真让我跑一次,我还是不知道从哪开始。”
这是完全正常的。
因为 PPO 实战,和你熟悉的 SFT / LoRA 微调,几乎是两种完全不同的工程体验。
在 SFT 里,你面对的是:
- 固定数据
- 固定标签
- 固定 loss
- 一条清晰的训练曲线
但在 PPO 里,你面对的是:
- 动态生成的数据
- 不稳定的 reward
- 多个 loss 共同作用
- 行为变化却很难量化
PPO 的难点,从来不是算法,而是“系统性不确定”。
在写代码之前,你必须先想清楚的一件事:你到底要对齐什么
这是 PPO 实战的第一道生死线。
很多人一上来就写代码,结果跑到一半才发现:
- reward 不知道怎么设计
- 评估指标完全对不上
- 模型行为变化无法解释
原因只有一个:
你一开始并没有把“对齐目标”说清楚。
在 PPO 实战中,你必须能用一句人话说清楚:
“我希望模型在什么情况下,更偏向哪种行为?”
比如:
- 面对不确定问题,更倾向于澄清而不是直接回答
- 面对违规请求,更坚决地拒绝
- 面对多种回答方式,偏向简洁而不是冗长
如果你说不清楚这句话,那 PPO 基本必翻。
PPO 实战的最小闭环,不是“训完一次”,而是“能观察到变化”
很多人第一次跑 PPO,目标设得非常大:
- 想一次就把模型调到“可上线”
- 想一轮训练解决所有问题
这是非常危险的。
PPO 实战的第一个目标,应该是:
我能不能清楚地看到模型行为,正在朝某个方向变化?
哪怕这个变化:
- 很小
- 很不稳定
- 甚至有副作用
只要你能解释这个变化,这次 PPO 实验就是成功的。
第一步:准备一个“不会害死你”的初始模型
这是 PPO 实战里最容易被低估的一步。
很多人会想:
“我直接用 base 模型不就行了吗?”
从工程经验来看,这几乎一定是错的。
PPO 的起点,必须是一个已经做过 SFT 的模型。
原因很现实:
- base 模型输出极不稳定
- PPO 会放大不稳定行为
- reward 很容易被随机输出干扰
你需要的,是一个:
- 输出基本可控
- 行为已经在“合理范围内”
- 不会在第一步就发疯的模型
Base 模型 vs SFT 模型作为 PPO 起点对比
第二步:Reference Model,不是“可选项”,而是命门
在 PPO 实战里,没有 reference model,几乎等于自杀。
很多人为了省显存、图简单,会尝试:
- 不设 reference
- 或直接用 policy 自己当 reference
这是非常危险的。
Reference model 的作用只有一个,但非常关键:
告诉你:你现在到底离“原来的自己”有多远。
在工程上,你可以简单理解为:
reference_model = copy.deepcopy(policy_model)
reference_model.eval()
Reference 不参与训练,
它是你所有 KL 计算的锚点。
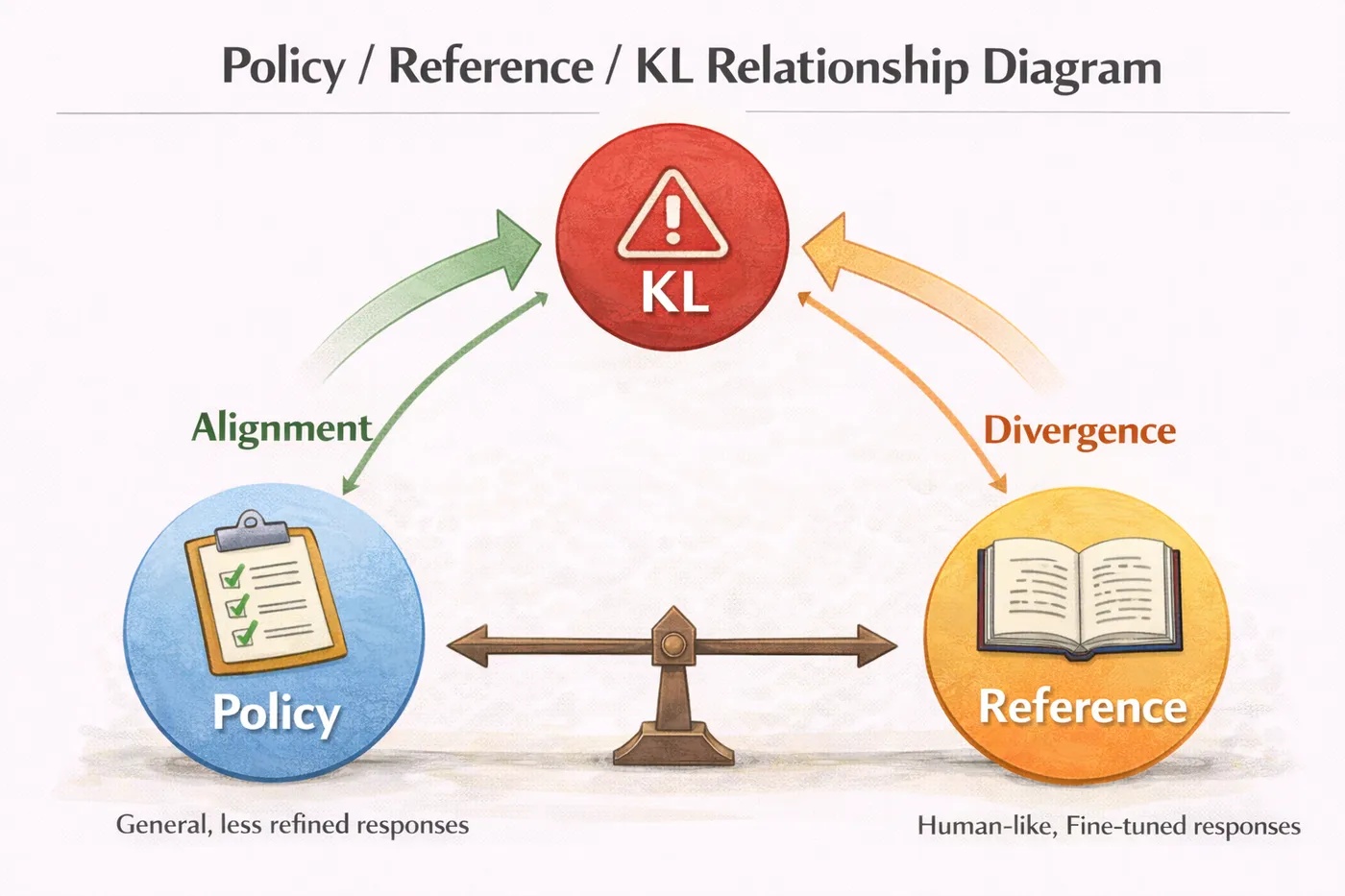
Policy / Reference / KL 关系示意图
第三步:Reward 设计,几乎决定了 PPO 的上限和下限
如果说 PPO 有“最容易翻车”的地方,那一定是 reward。
因为 reward 有一个非常反直觉的特性:
reward 并不会教模型“什么是对的”,
它只会放大“什么更容易拿高分”。
最常见的错误 reward 设计
- 只奖励“像人类回答”
- 只奖励“长度 / 礼貌 / 拒绝”
- 奖励规则过于单一
结果往往是:
- 模型学会套话
- 输出越来越模板化
- 行为变得极端
一个更安全的 reward 思路
在实战中,reward 更像是偏好比较器,而不是打分器。
reward = r_preferred - r_other
你不是在说“这个回答值 0.8 分”,
而是在说:
“这个回答,比那个更符合我的偏好。”
第四步:PPO 训练循环,真正更新的只有一个东西
在代码层面,PPO 看起来很复杂,但真正被更新的,始终只有 policy。
一个极简但真实的 PPO 核心流程是这样的:
for batch in data_loader:
responses = policy.generate(batch["prompt"])
rewards = reward_model(batch["prompt"], responses)
kl = compute_kl(policy, reference, batch["prompt"], responses)
loss = -rewards + kl_coef * kl
loss.backward()
optimizer.step()
optimizer.zero_grad()
你可以暂时忘掉 advantage、value head 的数学细节,
先抓住一个核心事实:
PPO 的本质,是在 reward 和 KL 的拉扯中,更新 policy。
为什么 PPO 的 loss 曲线,几乎“没有参考价值”
这是第一次跑 PPO 的人,一定会被误导的一点。
你会盯着 loss,看它:
- 忽高忽低
- 甚至发散
- 和输出效果毫无对应关系
这是正常的。
因为 PPO 的 loss,本身就是一个混合目标函数:
- reward 在变
- KL 在变
- sampling 分布在变
PPO 的 loss,不是“优化指标”,而是“控制信号”。
第五步:KL 系数,是你最重要的“风险旋钮”
在 PPO 实战里,如果只能让你调一个参数,那一定是:
KL coefficient。
- KL 太小 → 模型行为剧烈变化
- KL 太大 → 模型几乎不动
一个非常实用的经验是:
宁愿一开始 KL 大一点,也不要太小。
因为 PPO 的风险,永远来自“走太快”。
一个真实现象:PPO 成功的第一信号,往往不是“效果变好”
这是很多人第一次跑通 PPO 后,最意外的一点。
PPO 成功的第一信号,往往是:
- 输出变得“更一致”
- 边界问题上更保守
- 风格明显发生变化
而不是准确率突然提升。
如果你第一轮 PPO 就看到模型“更聪明了”,
那反而要小心是不是 reward 设计出了问题。
调试 PPO 的唯一正确方式:固定一切,只看行为
PPO 调试时,最忌讳的事情是:
- 一边改 reward
- 一边改 prompt
- 一边换模型
这会让你完全失去因果判断能力。
更健康的方式是:
- 固定 prompt
- 固定评估集
- 固定生成参数
- 只动 PPO 相关变量
PPO 实战中,最常见的 5 种翻车方式
- 1️⃣ reward 设计过于“聪明”:模型学会走捷径。
- 2️⃣ KL 太小:模型行为发散,难以收敛。
- 3️⃣ 数据分布太窄:模型在少数场景下过拟合。
- 4️⃣ 评估集和训练集同质:你以为模型变好了,其实只是记住了模式。
- 5️⃣ 太早追求“可上线效果”:PPO 本质是迭代过程,不是一次性工程。
一个非常现实的建议:第一次 PPO,别在本地硬刚
这是一个非常工程向、但极其重要的建议。
第一次跑 PPO,你会遇到的问题包括但不限于:
- reward 接口不稳定
- 日志难以对比
- checkpoint 行为差异难观察
- 中断恢复成本极高
在第一次把 PPO 从“理论”推进到“可运行”阶段时,用 LLaMA-Factory online这类已经封装好 PPO 训练、评估和版本对比的平台,先把最小闭环跑通,再回到本地深度定制,往往能少踩非常多“无意义的工程坑”。
PPO 实战的一个健康节奏(非常重要)
一个更健康的 PPO 实战节奏,通常是:
- 第 1 轮:只验证“行为是否可控”
- 第 2 轮:微调 reward,观察趋势
- 第 3 轮:扩大数据覆盖面
- 第 4 轮:引入更复杂的评估
而不是:“一次跑到完美”。
为什么 PPO 实战一定离不开评估,而不是训练本身
在 PPO 项目中,训练只是过程,
评估才是你唯一能确认方向的工具。
如果你无法稳定地判断:
- 模型是不是在变
- 变得是不是你想要的方向
那 PPO 就只是一次“随机扰动”。
一个很现实的结论:PPO 是“慢工”,不是“猛药”
很多人对 PPO 的期待,其实是错的。
PPO 不会:
- 一夜之间让模型脱胎换骨
- 神奇地解决所有问题
它更像是:
在你已经有一个可控模型的前提下,
慢慢推它往某个方向靠拢。
总结:PPO 实战真正难的,是“你有没有耐心把闭环跑完整”
写到这里,其实可以把整篇文章压缩成一句话:
PPO 实战的难点,不在代码、不在公式,
而在你能不能控制变量、读懂行为、接受它慢慢变化。
当你真正用“行为变化”而不是“指标提升”来评估 PPO,
你会发现:
- reward 设计变清晰了
- KL 调整有意义了
- PPO 不再那么神秘


