

引言:为什么AI应用都离不开它?
嗨!我是你们的AI伙伴~狸猫算君。不知道你有没有发现,现在很多酷炫的AI应用——比如能和你聊公司内部文件的智能助手、电商平台的“猜你喜欢”、甚至是一秒找出相似图片的相册——背后都有一个共同的技术核心:向量数据库。
简单来说,向量数据库就是AI时代的“超级记忆中枢”。我们人类的记忆是联想式的,提到“苹果”,你会想到水果、手机、公司。AI也需要这种能力,但它理解世界的方式是通过数字——更准确地说,是高维向量。
你上传的一张图片、一段语音、一篇文档,被AI模型(比如各种大语言模型)处理后会变成一串长长的数字(向量)。这串数字就是这个内容的“数学指纹”。向量数据库干的就是高效存储和快速比对这无数个“指纹” 的活儿。当你想搜索“与这幅画风格相近的作品”或“意思和这句话类似的文档”时,它能在毫秒级从海量数据中找出最匹配的结果。
所以,无论你是想搭建一个智能客服、一个推荐系统,还是当前火热的RAG(检索增强生成)应用,选对一个趁手的向量数据库,项目就成功了一半。今天,我就用最直白的方式,带你一次看懂8种主流的向量数据库,帮你找到最适合你的那一个。
技术原理:三分钟搞懂核心概念
别被“高维向量”“嵌入”这些词吓到,咱们用生活中的例子来理解:
- 万物皆可向量化
想象一下,你要用一个数字来描述一个朋友。你可以用[身高, 体重, 外向程度, 幽默感…]这一组数字来定义他。AI模型做得更精细,它能把一段话、一张图变成由几百甚至几千个维度组成的“特征向量”,就像给内容定做了一个超精密的数学坐标。
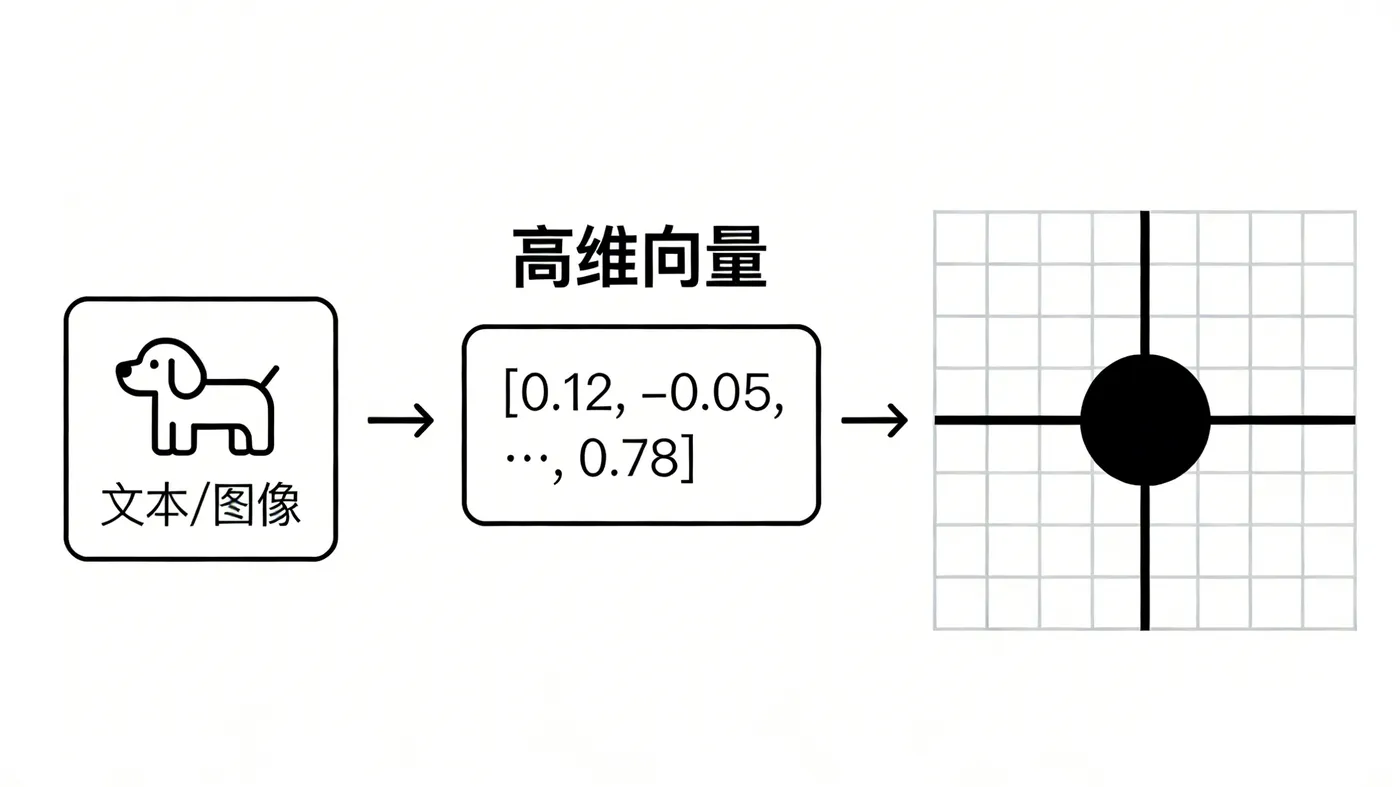
- 相似度计算 = 找“邻近点”
向量数据库把所有内容的坐标点都存起来。当你查询时,它把你的问题也变成坐标点,然后快速计算空间中距离最近的那些点。空间中两点距离越近,内容就越相似。这就像在一个超大的宇宙星图中,快速找到离你当前位置最近的那些星球。 - 索引:快速查找的“秘籍”
如果挨个计算距离,数据一多就慢如蜗牛。所以需要“索引”——一种高级的目录或地图。常见的如HNSW(分层导航小世界)算法,它像建立了一个多层次的“交友网络”,让你能通过少数几个“朋友”就快速联系到目标人物,极大提升了搜索速度。
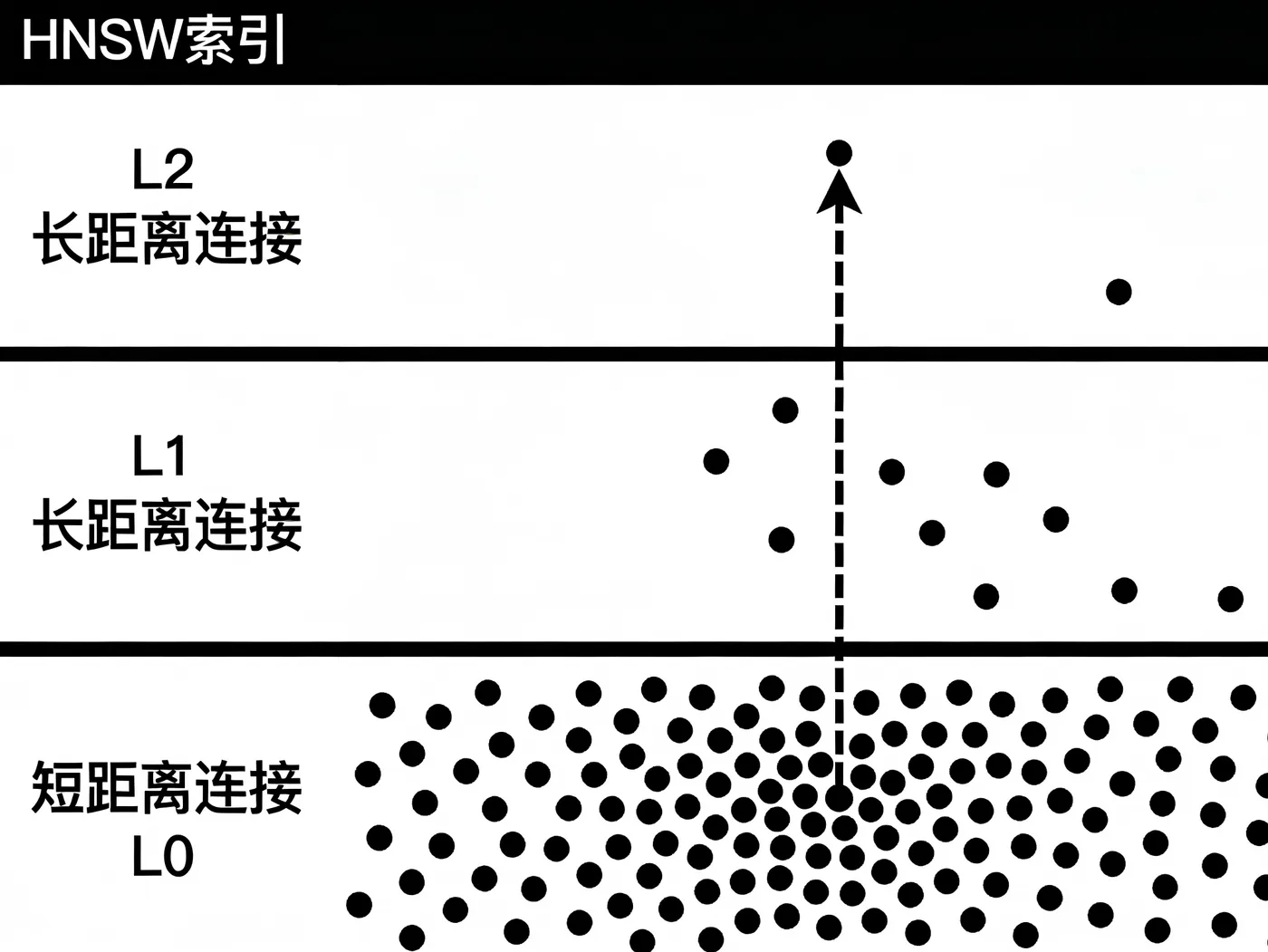
理解了这三个核心,你就掌握了向量数据库90%的原理。接下来,我们看看市面上有哪些好用的工具。
八大向量数据库全方位PK
我将它们分为三大类: “省心托管型” 、 “强大开源型” 和 “轻量嵌入型” 。你可以对号入座。
第一类:省心托管型——拿来即用,专注业务
适合:追求开发速度、不想操心运维的团队或个人。
1. Pinecone:云原生“优等生”
它像谁:AI数据库领域的“AWS”,全托管,服务到位。
核心优点:
- 开箱即用:注册账号、拿到API密钥就能调用,几分钟接入。
- 性能强劲:为低延迟搜索深度优化,应对实时场景毫无压力。
- 自动伸缩:数据量增长或流量爆发,它自动扩容,无需干预。
需要注意:
- 成本较高:按使用量收费,大规模、高并发时账单可能比较“感人”。
- 无法本地部署:数据必须放在它的云上,对数据隐私有极端要求的场景需谨慎。
典型场景:快速原型验证、实时推荐系统、需要稳定高性能的创业公司早期产品。
2. Weaviate (云托管版):搜索“多面手”
它像谁:一个既懂关键词又懂语义的“全能搜索助理”。
核心优点:
- 混合搜索:独家绝活!可同时进行向量搜索(找意思相近的)和传统关键词搜索(找字面匹配的),结果更精准。
- 模块化:内置多种AI模型,切换文本/图像嵌入模型像换插件一样方便。
- 接口友好:使用GraphQL查询,对于前端开发者非常友好。
需要注意:
- 超大规模性能:面对十亿级以上的向量数据时,可能需要更精细的调优。
- 社区相对小:相比一些老牌开源项目,生态和中文资料稍少。
典型场景:需要结合关键字和语义搜索的知识库、企业内部智能搜索引擎。
第二类:强大开源型——功能强悍,自主可控
适合:有技术运维能力、注重成本和控制力的团队。
3. Milvus:开源领域的“性能怪兽”
它像谁:数据库界的“Linux”,强大、灵活,但需要一些动手能力。
核心优点:
- 性能标杆:专为海量向量搜索设计,分布式架构能轻松处理千亿级数据。
- 生态丰富:社区活跃,支持多种索引算法和客户端语言,可定制化程度极高。
- 成本优势:免费开源,只需支付硬件成本。
需要注意:
- 部署运维复杂:需要自己搭建集群、监控和优化,对运维有要求。
- 学习有曲线:需要理解其存储、索引等概念才能发挥最大效能。
典型场景:超大规模图像/视频检索、基因序列分析、大型互联网平台的推荐系统。
4. Elasticsearch (向量搜索插件):搜索巨头的“新技能”
它像谁:一位学会了“语义理解”的传统搜索大师。
核心优点:
- 功能全面:本身就是最强的全文搜索引擎,现在加上向量,能实现“文本+语义”的混合搜索。
- 生态成熟:插件、工具、文档极其丰富,遇到问题几乎都能找到答案。
- 企业级特性:分布式、高可用、安全管控等开箱即用。
需要注意:
- 向量非原生:向量搜索通过插件实现,纯向量搜索性能可能不如专用库。
- 系统较重:本身比较消耗资源,架构相对复杂。
典型场景:已有ES生态,需要增加AI能力;日志的语义分析;商品搜索(既要关键词匹配又要理解语义)。
5. PgVector:关系型数据库的“AI扩展包”
它像谁:给你的老朋友PostgreSQL戴上了一副AI眼镜。
核心优点:
- 无缝集成:就是PostgreSQL的一个扩展,无需引入新的数据库系统,管理和查询都用熟悉的SQL。
- 学习成本低:对已用PostgreSQL的团队来说,几乎是零成本上手。
- 事务支持:完美支持ACID事务,这是很多专用向量数据库不具备的。
需要注意:
- 性能上限:在处理海量、超高维向量时,性能可能无法与Milvus等专业选手媲美。
- 索引类型较少:目前主要支持HNSW等少数几种索引。
典型场景:已有PostgreSQL的中小规模AI应用;需要严格事务保证的AI业务;希望用SQL统一管理关系数据和向量数据。
6. Redis (向量模块):内存闪电侠的“新武器”
它像谁:以速度闻名的“闪电侠”,现在能看懂内容了。
核心优点:
- 极致延迟:数据全在内存,搜索速度极快,适合微秒级响应场景。
- 一库多用:既能当缓存、消息队列,又能做向量搜索,架构简化。
- 简单易用:Redis的API大家都很熟悉。
需要注意:
- 内存成本高:存储大量向量对内存要求高,成本显著。
- 功能相对基础:向量搜索的高级功能(如过滤、复杂索引)不如专用库。
典型场景:实时广告竞价、在线游戏匹配、需要毫秒级响应的推荐。
第三类:轻量嵌入型——简单灵活,无处不在
适合:开发测试、本地应用、边缘计算或轻量级产品。
7. ChromaDB:AI应用开发的“瑞士军刀”
它像谁:一个轻巧、便携的向量工具箱,随时可以掏出来用。
核心优点:
- 极致简单:几行Python代码就能启动,API设计非常人性化。
- 嵌入式运行:无需单独部署数据库服务器,可以集成在你的应用进程中。
- 为RAG而生:与大语言模型配合紧密,是构建RAG系统的热门选择。
需要注意:
- 处理规模有限:不适合存储和处理超大规模(如十亿级以上)的向量数据。
- 功能简洁:专注于核心的存储和检索,高级数据库管理功能较少。
典型场景:本地开发测试、快速构建原型、中小型RAG应用、学术研究。如果你正想基于自己的数据,快速微调出一个专属的AI模型来验证RAG想法,可以试试LLaMA-Factory Online低门槛大模型微调平台。它能把你的数据轻松“喂”给模型,即使没代码基础,也能跑完微调全流程,让你在实践中理解怎么让模型输出“更像你想要的样子”,正好和ChromaDB这类向量库搭配,构建完整的AI应用链条。
8. LanceDB:面向未来的“高效能手”
它像谁:一个用尖端技术打造的、省油又跑得快的“新能源车”。
核心优点:
- 性能与效率俱佳:基于Rust和自研的列式存储格式,查询快且CPU/内存占用低。
- 云原生友好:与数据湖(如S3)无缝集成,直接处理云存储上的向量数据。
- 多模态原生支持:对图像、视频、文本等混合数据处理顺畅。
需要注意:
- 项目较新:生态和社区还在快速成长中,遇到深坑可能需自己解决。
- 文档和案例:相比成熟项目,学习资料相对少一些。
典型场景:边缘AI设备、需要与数据湖结合的分析场景、对资源消耗敏感的应用。
如何选择?一张表帮你决策
| 数据库 | 核心类型 | 性能 | 易用性 | 典型适用场景 | 一句话推荐 |
|---|---|---|---|---|---|
| Pinecone | 全托管云服务 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 实时推荐、快速原型、不差钱求省心 | “不想折腾,就要又快又稳的云服务” |
| Milvus | 开源可自托管 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 超大规模检索、图像/视频搜索、有强技术团队 | “我要处理海量数据,且有能力驾驭它” |
| Weaviate | 开源/托管可选 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 混合搜索、知识图谱、快速AI应用 | “我既要语义搜索,也要关键词匹配” |
| Elasticsearch | 搜索引擎扩展 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 企业级混合搜索、日志语义分析、已有ES生态 | “我的搜索需求复杂,且已用惯ES” |
| PgVector | 数据库扩展 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 中小规模AI应用、PostgreSQL用户、需事务支持 | “我用PostgreSQL,想低成本加点AI能力” |
| Redis | 内存数据库扩展 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 超低延迟实时推荐、缓存+搜索融合 | “速度就是生命,毫秒级响应不能等” |
| ChromaDB | 轻量嵌入式 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 开发测试、原型、轻量RAG、学习入门 | “我想快速上手试试,从本地开始玩转AI” |
| LanceDB | 轻量嵌入式 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 边缘计算、数据湖分析、追求资源效率 | “我需要在资源有限或云端对象存储里高效处理向量” |
效果评估:你的数据库选对了吗?
上线后,可以从以下几个维度检验:
- 精度 (Recall @ K) :搜索时,前K个结果中包含正确答案的比例。这直接关系到搜索质量。
- 延迟 (Latency) :从发起查询到得到结果的时间。特别是实时应用,99分位延迟(P99)是关键。
- 吞吐量 (QPS) :每秒能处理的查询数量。在高并发场景下至关重要。
- 资源消耗:CPU、内存、磁盘IO的占用情况。这关系到成本和系统稳定性。
- 运维复杂度:监控、扩容、备份恢复是否方便。
建议在项目初期就用真实数据做一个 “烘焙测试” ,从上述维度对比2-3个候选数据库,数据会给你最客观的答案。
总结与展望
向量数据库已成为AI基础设施的关键一环。选择没有绝对的对错,只有适合与否。
- 如果你是初学者或独立开发者,从 ChromaDB 或 Pinecone 开始,能让你最小阻力地感受AI应用的构建。
- 如果你身处创业团队,Weaviate 的混合搜索或 Pinecone 的省心可能是快速迭代的利器。
- 如果你在大型企业,处理海量数据且技术储备足,Milvus 或 Elasticsearch 能提供坚实支撑。
- 如果你有明确的边缘或混合云需求,LanceDB 和 PgVector 展示了独特价值。
未来,向量数据库的发展会朝着 “更智能”(与AI模型深度集成)、“更融合”(统一处理多模态、结构化数据)、“更平民化” 的方向演进。门槛会进一步降低,而能力会不断增强。
