

最近英伟达公布了他们最新论文《Autonomous Code Evolution Meets NP-Completeness》,一个由AI自主编辑的智能体,在顶级NP问题SAT上超越了25年人类冠军。
如果是以前,有人告诉我“AI写代码超过了人类”,我可能会笑笑说:“也就是写写LeetCode简单题或者是简单的Web页面吧。”但是这一次不一样,AI挑战的是计算机科学上的珠穆朗玛峰——SAT(布尔可满足性)求解器,而且,它赢了。不仅赢了,还赢得很彻底。一个由AI全自动演进出来的求解器系统 SATLUTION,在使用2024年的代码库和题目训练的情况下,不仅吊打了2024年的冠军,甚至超越了刚刚出炉的 2025年SAT竞赛的人类冠军(也就是作者本人) 。
今天想和大家聊聊这项工作背后的技术细节,以及它给我带来的一些关于“AI与我们”的思考。
为什么要“卷”SAT求解器?
首先得科普一下,为什么SAT求解器这么重要?SAT问题是第一个被证明为NP完全的问题,也是千禧年十大数学问题榜首。简单来说,它是计算复杂性理论的基石,NP完全问题即代表所有的NP问题都可以被归约为SAT问题,解决SAT问题对所有同类型问题都有较大推动。在工业界,SAT求解器是芯片验证、软件分析、加密破译等领域的核心引擎,特别是在EDA的等价验证上,SAT求解器被广泛使用。
过去三十年里,像 MiniSat、Kissat 这样的经典 SAT 求解器,基本都是人一点点“抠”出来的成果。里面的各种启发式、分支策略、内存管理,说白了,全是顶级专家靠长期经验和直觉慢慢打磨出来的。也正因为这样,大家普遍觉得这是一个非常吃专家经验、非常工程化的领域,AI 很难直接插手。打个不太严谨的比方,就像一堆已经堆到很高、结构还特别复杂的积木,看起来哪里都能动,但你真去随便换一块,很可能整个就塌了。所以,指望直接让大模型去“改一个 SAT 求解器”,本身就是一件难度极高的事情。但英伟达的团队却另辟蹊径,设计了SATLUTION。
SATLUTION:并不是简单的“让GPT写代码”
很多人对AI写代码的印象还停留在Copilot补全几行代码的阶段。但SATLUTION展示的是一种代码库级别(Repository-scale)的进化 。这就好比,以前的AI是帮你砌砖的瓦工,而SATLUTION是一个能接管整个工地的包工头,甚至还带了个建筑师。
1. 双“大脑”架构:规划与执行
SATLUTION设计了两个核心Agent(智能体):
规划智能体(Planning Agent):负责动脑子。它分析当前的性能瓶颈,提出改进方向,比如“我是不是该改改分支策略?”或者“这个内存管理是不是有问题?”。
编码智能体(Coding Agent):负责动手。它不仅是写C/C++代码,还要处理Makefile、修复编译错误、甚至处理Segmentation Fault(段错误)。
2. 最大的亮点:它有“家规”(Rule System)
这是我觉得整篇论文最精彩、也最有人情味的地方。
研究人员发现,如果你让AI随便写,它很容易“放飞自我”,写出虽然能跑但逻辑错误的代码,或者引入一些看似优化实则作弊的策略。于是,他们引入了一套规则系统(Rule System) 。
这就好比带徒弟。一开始,师父(人类)会给徒弟(AI)一套手册:
基础家规:必须用C++,不能用外部库 。
红线:如果是SAT,必须给出赋值;如果是UNSAT,必须给出DRAT数学证明 。
最神的是,这套规则是可自进化的 。如果AI发现某种写法总是导致Bug,它会自动把这条教训写入“家规”里的《禁止事项》(Forbidden Patterns)。比如,AI自己学会了“别乱用malloc,容易内存泄漏”,并把它写进规则里提醒未来的自己 。
3. 极度严苛的“考试系统”:Verifier
AI生成的代码能不能用,不是看它能不能跑通Hello World,而是要经过地狱级的测试。SATLUTION引入了一个双阶段验证器 :
第一关(Smoke Test):编译通过了吗?跑简单的例子会崩吗?
第二关(Correctness Check):这是核心。如果求解器说“无解(UNSAT)”,你不能光嘴上说,你得生成一个数学证明,然后有一个独立的第三方程序来验证你的证明是对的 。
正是这个“如果不给证明,我就不信你”的机制,保证了AI不会产生“幻觉”或者瞎猜。论文提到,只要通过了这两关的求解器,在后续测试中从未出错过 。
结果:降维打击
这种进化带来的效果是惊人的。
SATLUTION从2024年的几个开源求解器(Kissat等)起步,经过70轮的自我迭代,产生了一个“怪兽”。
- 在2025年SAT竞赛的题目上,它比人类冠军(AE_kissat2025_MAB)解出了更多的题目,速度更快 。
- 它不仅在SAT(有解)问题上表现好,在UNSAT(无解)问题上也甚至更强 。
看下面这张图,蓝色的柱子是人类冠军,左边那排金色的、越跑越快的是SATLUTION进化出来的家族。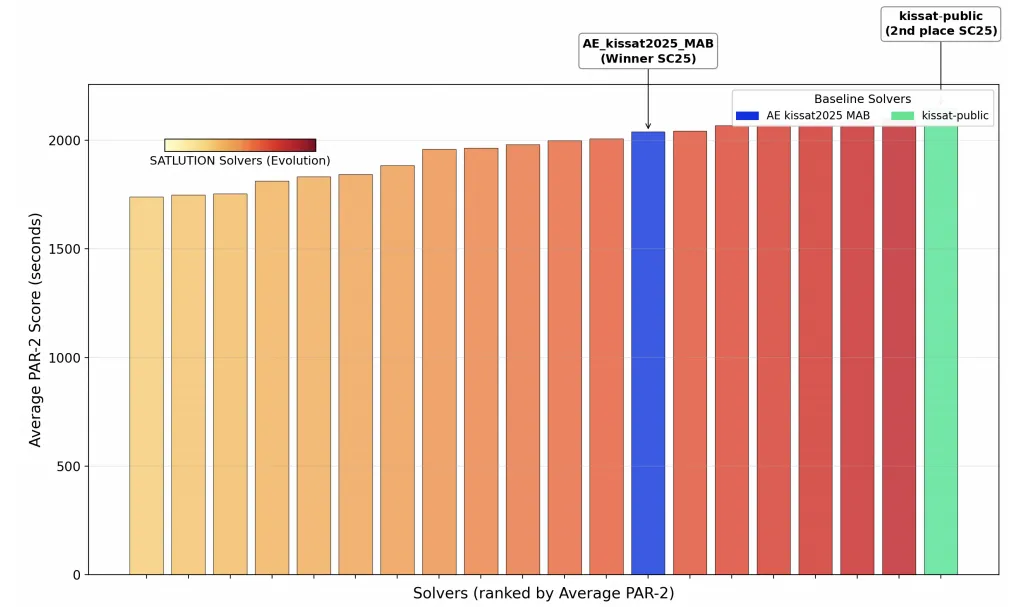
更杀人诛心的是成本。人类专家开发一个顶尖求解器,通常需要数月甚至数年的积累。而SATLUTION跑完全程,花费的Token成本不到 2000美元,加上算力成本也就不到2万美元 。技术之外的思考:程序员的“后AI时代”
读完这篇论文,我最大的感触并不是“失业焦虑”,而是一种角色的转变。
- 从“写代码”到“定规矩”:
在SATLUTION里,人类作者并没有直接写核心算法,他们做的是设计验证器(Verifier)和制定规则(Rules)。
这可能就是未来的编程范式。我们不再纠结于具体的for循环怎么写,而是专注于定义“什么是对的”。只要我们能清晰地定义“正确性”(比如要求DRAT证明),AI就能帮我们在无限的搜索空间里找到最优解 。 - AI也能搞科研:
论文里提到,AI自己发现了一些人类未曾深入探索的策略,比如动态调整Clause Vivification(子句活跃化)的敏感度,甚至学会了用Bandit算法来动态控制参数 。这说明AI不仅是在模仿,它开始产生某种程度的“算法创新”。 - 验证(Verification)是新的护城河:
论文作者在讨论部分特意强调:Verifier is Critical 。能够构建一个鲁棒的、自动化的验证系统,比写出代码本身更重要。在EDA(电子设计自动化)等容错率极低的领域,谁掌握了验证,谁就掌握了让AI落地的钥匙 。
SATLUTION 像是一个信号。它告诉我们,在那些即使是人类最顶尖大脑统治的硬核领域,AI也开始入场了。它不是来替代我们的创造力,而是来替代那些“需要极高试错成本”的探索过程。
作为开发者,也许我们该换个思路了:别总想着怎么自己手搓每一行代码,想想怎么做一个好的“考官”,让AI去帮你考个满分回来。
参考资料:本文核心数据与图片均引用自论文《Autonomous Code Evolution Meets NP-Completeness》


