技术文档散落在语雀、GitHub、本地硬盘,新员工入职像 “寻宝”;写一份部署手册要熬 4 小时,修改迭代还要跨平台同步;搜索 “token 过期解决方案”,返回几十篇无关文档,翻半天找不到重点;敏感数据不敢存云端,私有化部署又要折腾好几天……
在信息爆炸的时代,我们囤积了海量知识,却陷入 “存得住、找不着、用不上” 的困境。直到 PandaWiki 的出现 —— 这款 GitHub 斩获 8.3K 星标的 AI 原生开源知识库,用 “智能驱动 + 极简部署 + 安全可控” 的三重优势,重新定义了知识管理的效率边界。
AI 全链路赋能:让知识 “自己生长”
PandaWiki 最颠覆的突破,是把知识管理从 “人适应系统” 变成 “系统适配人”。技术团队实测显示,输入 “微服务部署手册” 主题,AI 瞬间生成包含环境配置、故障排查的结构化大纲,文档撰写效率直接提升 70%,4 小时工作量压缩至 1 小时。更强大的是 “无感知沉淀” 能力:会议录音上传后自动提取知识点,客服聊天记录授权后生成标准化问答,某企业半年内知识库内容增长 3 倍,员工录入负担却减少 50%。
检索体验更是 “降维打击”。传统关键词搜索的 “信息噪音” 被彻底终结,语义检索能精准理解自然语言意图 —— 提问 “如何解决用户登录 token 过期问题”,30 秒内整合技术文档、故障案例、会议纪要的步骤化答案,还自动关联 JWT 配置规范、权限校验流程等相关内容,这背后是动态知识图谱打破了部门间的信息孤岛。
企业级适配:开源自由与安全可控的完美平衡
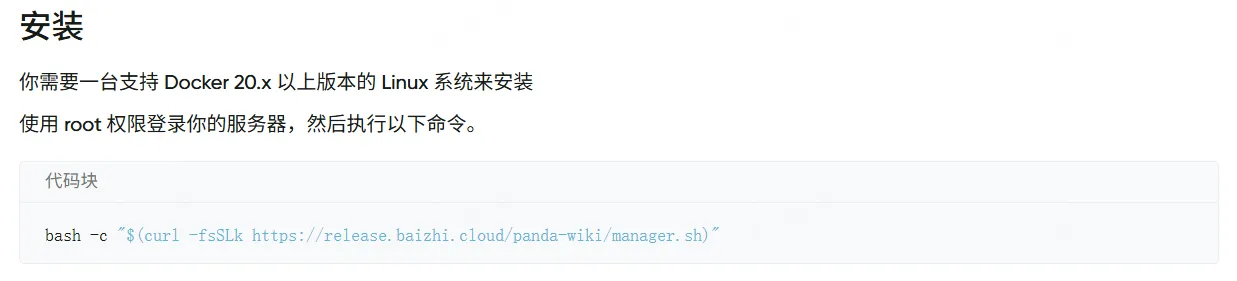
对于企业而言,工具的落地关键在适配性与安全性。PandaWiki 用 Docker 实现一键部署,复制一行命令,5 分钟内即可完成私有化搭建,非技术人员也能轻松操作,告别传统系统数天的部署周期。更灵活的是部署模式:公有云、私有化、混合云自由选择,敏感数据存本地,普通文档放云端,既满足金融、政务等强监管行业的合规要求,又降低运维成本。
细粒度权限管控精确到 “部门 - 角色 - 文档” 三级,操作日志实时审计,搭配 SSO 单点登录和 RBAC 权限体系,让知识安全无死角。同时,它能无缝集成企业微信、飞书、CRM、ERP 等主流办公系统,员工无需切换平台即可调用知识库,实现数据互通无壁垒。
全场景覆盖:从个人到企业的智能知识管家
技术团队:AI 辅助创作 API 文档、故障排查手册,语义搜索快速定位技术方案,新员工上手时间从 2 周缩短至 3 天,重复开发问题减少 85%,每年节省研发成本超 200 万元;
企业 HR / 行政:AI 自动生成新员工 Onboarding 指南、抽取 FAQ 构建标准化问答库,员工咨询重复率大幅下降,客服工作量减少 60%,客户等待时间从 3 分钟压缩至 30 秒;
个人用户:开源免费无订阅陷阱,支持 PDF、Word、URL 等 10 + 格式导入,搭建专属知识库,提问 “诸葛亮是怎么死的”“Python 爬虫入门技巧”,AI 基于导入资料精准作答,单次对话成本低至 1 分钱。
PandaWiki不一样在哪?
对比 Notion 的权限不足、FastGPT 的高定制成本,PandaWiki 实现了 “开箱即用” 与 “灵活扩展” 的平衡;相较于腾讯乐享等生态绑定产品,它不局限于特定平台;与 SaaS 工具相比,它保障数据自主可控。8.3K+GitHub 星标、活跃的开源社区,让行业模板、定制插件持续丰富,适配场景不断拓展。
告别知识内耗,从选择 PandaWiki 开始
当知识不再沉睡于文件夹和收藏夹,当系统主动适配你的工作习惯,当安全与效率不再两难 ——PandaWiki 不仅是一款知识库工具,更是驱动团队增长的 “数字大脑”。无论是技术文档中心、企业培训平台,还是个人知识管家,它都能一站式满足需求。
现在就复制一行命令,5 分钟搭建你的智能知识库,让知识真正 “活” 起来,成为你最核心的竞争力!